HashMap归档-超越昨天的自己系列
java HashMap
读一下源码,一个数组存储数据:
transient Entry[] table;
内部存key和value的内部类:
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
final int hash;
/**
* Creates new entry.
*/
Entry( int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
public final int hashCode() {
return ( key== null ? 0 : key.hashCode()) ^
( value== null ? 0 : value.hashCode());
}
public final String toString() {
return getKey() + "=" + getValue();
}
/**
* This method is invoked whenever the value in an entry is
* overwritten by an invocation of put(k,v) for a key k that's already
* in the HashMap.
*/
void recordAccess(HashMap<K,V> m) {
}
/**
* This method is invoked whenever the entry is
* removed from the table.
*/
void recordRemoval(HashMap<K,V> m) {
}
}
所以HashMap的数据结构为数组下的链表结构,如图:
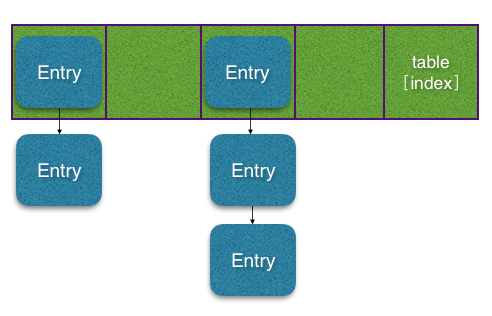
来看下put方法:
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);//hash 找到数组中位置
//遍历链表 找出key相同的
for (Entry<K, V> e = table [i]; e != null ; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess( this);
return oldValue;
}
}
modCount++;
//没有key相同的 在数组的这个位置里新加一个值进去
addEntry(hash, key, value, i);
return null;
}
放数据的代码可以看出,从性能的角度来说,链表的长度越长,查找一个key是否在这个map中的时间就越长。而在是否同一个链表上的key是由key.hashCode()决定的。
还注意到放null为key的对象时,是直接放入数组的头部的。这样处理也是最好的实现了吧。否则一个null还要找一遍。
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e. next) {
if (e. key == null) {
V oldValue = e. value;
e. value = value;
e.recordAccess( this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
void addEntry (int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
if (size++ >= threshold)
resize(2 * table. length);
}
HashMap的hash算法:
static int hash(int h) {
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
/**
* Returns index for hash code h.
*/
static int indexFor(int h, int length) {
return h & (length-1);
}
这个要详细看一下,hash方法中的算法在以前文章中有记录,可以参看:http://www.cnblogs.com/killbug/p/4560000.html
为了尽可能的试put的数据能平均的分布在数组上,提高map性能,上面的两个方法就是来做这件事的。
hash方法将key.hashcode再进行了一次hash,hash函数的通过若干次的移位、异或操作,把hashcode的“1位”变得“松散”,在接下来和数组长度的于操作时可以得出更平均的数组下标。
我们注意到数组的length被要求是2的幂次方,如此在做与操作的时候减1就变成1111这种,如此是最好的。
看下图,左边两组是数组长度为16(2的4次方),右边两组是数组长度为15。两组的hashcode均为8和9,但是很明显,当它们和1110“与”的时候,产生了相同的结果,也就是说它们会定位到数组中的同一个位置上去,这就产生了碰撞,8和9会被放到同一个链表上,那么查询的时候就需要遍历这个链表,得到8或者9,这样就降低了查询的效率。同时,我们也可以发现,当数组长度为15的时候,hashcode的值会与14(1110)进行“与”,那么最后一位永远是0,而0001,0011,0101,1001,1011,0111,1101这几个位置永远都不能存放元素了,空间浪费相当大,更糟的是这种情况中,数组可以使用的位置比数组长度小了很多,这意味着进一步增加了碰撞的几率,减慢了查询的效率!
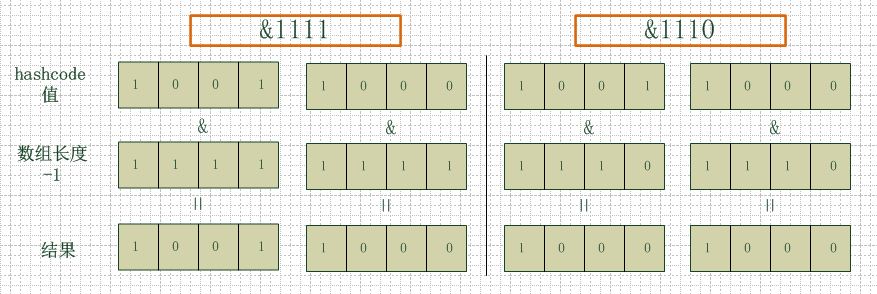
------------------------------20160203补充-----------------
那么HashSet的结构看起来有有些偷懒了,直接包一个HashMap,用key来来实现自己的功能。
比如构造函数:
public HashSet() {
map = new HashMap<E,Object>();
}
比如 contains函数:
public boolean contains(Object o) {
return map.containsKey(o);
}
LinkedHashMap也经常使用,它集成HashMap,结构和HashMap一样,为了实现顺序访问,在放元素(Entry)时,记录顺序。
Entry内部类也继承HashMap的,然后自己加了before,after来记录顺序:
/**
* LinkedHashMap entry.
*/
private static class Entry<K,V> extends HashMap.Entry<K,V> {
// These fields comprise the doubly linked list used for iteration.
Entry<K,V> before, after; Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {
super(hash, key, value, next);
} /**
* Removes this entry from the linked list.
*/
private void remove() {
before.after = after;
after.before = before;
} /**
* Inserts this entry before the specified existing entry in the list.
*/
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
} /**
* This method is invoked by the superclass whenever the value
* of a pre-existing entry is read by Map.get or modified by Map.set.
* If the enclosing Map is access-ordered, it moves the entry
* to the end of the list; otherwise, it does nothing.
*/
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
if (lm.accessOrder) {
lm.modCount++;
remove();
addBefore(lm.header);
}
} void recordRemoval(HashMap<K,V> m) {
remove();
}
}
在前面put函数代码里我们看到是调用addEntry方法,而LinkedHashMap也就是重写了这个方法,如此就调用到addBefore(header),即可每次加入元素都记录了顺序关系:
void addEntry(int hash, K key, V value, int bucketIndex) {
createEntry(hash, key, value, bucketIndex);
// Remove eldest entry if instructed, else grow capacity if appropriate
Entry<K,V> eldest = header.after;
if (removeEldestEntry(eldest)) {
removeEntryForKey(eldest.key);
} else {
if (size >= threshold)
resize(2 * table.length);
}
}
/**
* This override differs from addEntry in that it doesn't resize the
* table or remove the eldest entry.
*/
void createEntry(int hash, K key, V value, int bucketIndex) {
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<K,V>(hash, key, value, old);
table[bucketIndex] = e;
e.addBefore(header);
size++;
}
注意到一个细节,containsValue方法在HashMap中是需要遍历数组的:
public boolean containsValue(Object value) {
if (value == null)
return containsNullValue();
Entry[] tab = table;
for (int i = 0; i < tab.length ; i++)
for (Entry e = tab[i] ; e != null ; e = e.next)
if (value.equals(e.value))
return true;
return false;
}
而在LinkedHashMap里则不需要,因为我们维护了包含全部元素的链表,这个链表的长度肯定是小于数组长度的百分之75的,如果要查找一个值是否在这里面,遍历这个链表就好了:
public boolean containsValue(Object value) {
// Overridden to take advantage of faster iterator
if (value==null) {
for (Entry e = header.after; e != header; e = e.after)
if (e.value==null)
return true;
} else {
for (Entry e = header.after; e != header; e = e.after)
if (value.equals(e.value))
return true;
}
return false;
}
HashMap归档-超越昨天的自己系列的更多相关文章
- 时间作为横轴的图表(morris.js)超越昨天的自己系列(8)
超越昨天的自己系列(8) morris.js的官网有详细的例子:http://www.oesmith.co.uk/morris.js/ 特别注意它的依赖: <link rel="sty ...
- spring和redis的整合-超越昨天的自己系列(7)
超越昨天的自己系列(7) 扯淡: 最近一直在慢慢多学习各个组件,自己搭建出一些想法.是一个涉猎的过程,慢慢意识到知识是可以融汇贯通,举一反三的,不过前提好像是研究的比较深,有了自己的见解.自认为学习 ...
- maven为不同环境打包(hibernate)-超越昨天的自己系列(6)
超越昨天的自己系列(6) 使用ibatis开发中,耗在dao层的开发时间,调试时间,差错时间,以及适应修改需求的时间太长,导致项目看起来就添删改查,却特别费力. 在项目性能要求不高的情况下,开始寻 ...
- Collections.reverse 代码思考-超越昨天的自己系列(13)
点进Collections.reverse的代码瞄了眼,然后就开始了一些基础知识的收集. 现在发现知道的越多,知道不知道的越多. 列几个记录下: reverse方法源码: /** * Reverses ...
- crontab 移动日志-超越昨天的自己系列(12)
linux上定时执行某些脚本是管理服务器的时候比较常用的场景,比如定时检查进程是否存在,定时启动或关闭进程,定时检查日志删除日志等. 当我打开google百度crontab时长篇大论的一大堆,详细解释 ...
- java进程性能分析步骤-超越昨天的自己系列(11)
java进程load过高分析步骤: top 查看java进程情况 top -Hp 查看某个进程的具体线程情况 printf 0x%x 确认哪一个线程占用cpu比较多,拿出来转成16进制 ...
- 快速用springmvc搭建web应用-超越昨天的自己系列(10)
Demo地址:http://pan.baidu.com/s/1sjttKWd 创建命令: mvn archetype:generate -DgroupId=com.witown.open.demo - ...
- 简答一波 HashMap 常见八股面试题 —— 算法系列(2)
请点赞,你的点赞对我意义重大,满足下我的虚荣心. Hi,我是小彭.本文已收录到 GitHub · Android-NoteBook 中.这里有 Android 进阶成长知识体系,有志同道合的朋友,关注 ...
- spring和redis的整合
spring和redis的整合-超越昨天的自己系列(7) 超越昨天的自己系列(7) 扯淡: 最近一直在慢慢多学习各个组件,自己搭建出一些想法.是一个涉猎的过程,慢慢意识到知识是可以融汇贯通,举一反三 ...
随机推荐
- Volley的GET和POST方法
首先记得加上权限 <uses-permission android:name="android.permission.INTERNET"/> XML代码 <?xm ...
- python split()函数
Python split()函数 函数原型: split([char][, num])默认用空格分割,参数char为分割字符,num为分割次数,即分割成(num+1)个字符串 1.按某一个字符分割. ...
- LeetCode 4 Median of Two Sorted Arrays 查找中位数,排除法,问题拓展 难度:1
思路:设现在可用区间在nums1是[s1,t1),nums2:[s2,t2) 1.当一个数组可用区间为0的时候,由于另一个数组是已经排过序的,所以直接可得 当要取的是最小值或最大值时,也直接可得 2. ...
- storm启动过程之源码分析
TopologyMaster: 处理拓扑的一些基本信息和工作,比如更新心跳信息,拓扑指标信息更新等 NimbusServer: ** * * NimbusServer work flow: 1. ...
- 替换url中某个参数的值或是添加某个参数的方法(js 分页上下页可以使用)
function changeUrl(base, find, value) { var offset = base.indexOf(find); var index; var rr = ''; if( ...
- R语言入门系列1--数学狗还是做数据好了
nanana,作为一个不合格的数学专业学生,脑袋不好使,又穷逼,只好学点儿实用的东西,希望能养活自己~~~ 不瞎哔哔,想做数据方面工作的时候在犹豫是学R还是学python,一点儿python基础都没有 ...
- Linux下man安装及使用方法
常用法: man [section] name 其中: section 指的是手册页的哪个部分,可以是1.2.3…8.,若不指定,man会按照次序依次查找,知道找到第一个. name 指的是某个命令. ...
- How to use a 32bit Oracle11_g client in 64 win system and not conflict with sqldeveloper 64 bit tool
At the path:C:\app\USER_NAME\product\11.2.0\client_1\sqldeveloper\sqldeveloper\bin, there a file 'sq ...
- linux输出 /dev/null
在学习Linux的过程中,常会看到一些终端命令或者程序中有">/dev/null 2>&1 "出现,由于已经遇到了好几次了,为了理解清楚,不妨花点时间百度或者g ...
- 内核input子系统分析
打开/driver/input/input.c 这就是input代码的核心 找到 static int __init input_init(void) { err = class_register(& ...