《利用python进行数据分析》读书笔记--第七章 数据规整化:清理、转换、合并、重塑(三)
http://www.cnblogs.com/batteryhp/p/5046433.html
5、示例:usda食品数据库
下面是一个具体的例子,书中最重要的就是例子。

#-*- encoding: utf-8 -*-
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pandas import Series,DataFrame
import re
import json #加载下面30M+的数据
db = json.load(open('E:\\foods-2011-10-03.json'))
#print len(db)
#print type(db) #得到的db是个list,每个条目都是含有某种食物全部数据的字典
#print db[0] #这一条非常长
#print db[0].keys()
#nutrients 是keys中的一个key,它对应的值是有关食物营养成分的一个字典列表,很长……
#print db[0]['nutrients'][0]
#下面将营养成分做成DataFrame
nutrients = DataFrame(db[0]['nutrients']) #将字典列表直接做成DataFrame
#print nutrients.head()
#print type(db[0]['nutrients'])
info_keys = ['description','group','id','manufacturer']
info = DataFrame(db,columns = info_keys)
#print info
#查看分类分布情况
#print pd.value_counts(info.group)
#现在,为了将所有的营养数据进行分析,需要将所有营养成分整合到一个大表中,下面分几个步骤来完成
nutrients = [] for rec in db:
fnuts = DataFrame(rec['nutrients'])
fnuts['id'] = rec['id'] #广播
nutrients.append(fnuts)
nutrients = pd.concat(nutrients,ignore_index = True) #将列表连接起来,相当于rbind,把行对其连接在一起 #去重,这是数据处理的重要步骤
print nutrients.duplicated().sum()
nutrients = nutrients.drop_duplicates()
#由于nutrients与info有重复的名字,所以需要重命名一下info
#注意下面这样的命名方式
col_mapping = {'description':'food',
'group':'fgroup'}
#rename函数返回的是副本,需要copy = False
info = info.rename(columns = col_mapping,copy = False)
#print info.columns #查看一下列名
col_mapping = {'description':'nutrient','group':'nutgroup'}
nutrients = nutrients.rename(columns = col_mapping,copy = False)
#print nutrients.columns
#做完上面这些,显然我们需要将两个DataFrame合并起来
print nutrients.ix[:10,:]
#print info.id
ndata = pd.merge(nutrients,info,on = 'id',how = 'outer')
print ndata
print ndata.ix[3000]
#注意下面的处理方式很nice
result = ndata.groupby(['nutrient','fgroup'])['value'].quantile(0.5)
print result
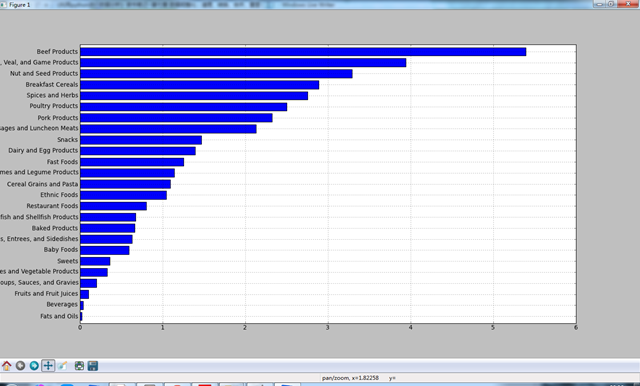
result['Zinc, Zn'].order().plot(kind = 'barh')
plt.show()
#只要稍微动动脑子(作者不止一次说过了……额),就可以发现各营养成分最为丰富的食物是什么了
by_nuttriend = ndata.groupby(['nutgroup','nutrient'])
print by_nuttriend.head()
#注意下面取出最大值的方式
get_maximum = lambda x:x.xs(x.value.idxmax())
get_minimum = lambda x:x.xs(x.value.idxmin())
max_foods = by_nuttriend.apply(get_maximum)[['value','food']]
#让food小一点
max_foods.food = max_foods.food.str[:50]
print max_foods.head()
print max_foods.ix['Amino Acids']['food']
>>>
14179
nutrient nutgroup units value id
0 Protein Composition g 25.18 1008
1 Total lipid (fat) Composition g 29.20 1008
2 Carbohydrate, by difference Composition g 3.06 1008
3 Ash Other g 3.28 1008
4 Energy Energy kcal 376.00 1008
5 Water Composition g 39.28 1008
6 Energy Energy kJ 1573.00 1008
7 Fiber, total dietary Composition g 0.00 1008
8 Calcium, Ca Elements mg 673.00 1008
9 Iron, Fe Elements mg 0.64 1008
10 Magnesium, Mg Elements mg 22.00 1008
<class 'pandas.core.frame.DataFrame'>
Int64Index: 375176 entries, 0 to 375175
Data columns:
nutrient 375176 non-null values
nutgroup 375176 non-null values
units 375176 non-null values
value 375176 non-null values
id 375176 non-null values
food 375176 non-null values
fgroup 375176 non-null values
manufacturer 293054 non-null values
dtypes: float64(1), int64(1), object(6)
nutrient Glycine
nutgroup Amino Acids
units g
value 0.073
id 1077
food Spearmint, fresh
fgroup Spices and Herbs
manufacturer
Name: 3000
nutrient fgroup
Adjusted Protein Sweets 12.900
Vegetables and Vegetable Products 2.180
Alanine Baby Foods 0.085
Baked Products 0.248
Beef Products 1.550
Beverages 0.003
Breakfast Cereals 0.311
Cereal Grains and Pasta 0.373
Dairy and Egg Products 0.271
Ethnic Foods 1.290
Fast Foods 0.514
Fats and Oils 0.000
Finfish and Shellfish Products 1.218
Fruits and Fruit Juices 0.027
Lamb, Veal, and Game Products 1.408
...
Zinc, Zn Finfish and Shellfish Products 0.67
Fruits and Fruit Juices 0.10
Lamb, Veal, and Game Products 3.94
Legumes and Legume Products 1.14
Meals, Entrees, and Sidedishes 0.63
Nut and Seed Products 3.29
Pork Products 2.32
Poultry Products 2.50
Restaurant Foods 0.80
Sausages and Luncheon Meats 2.13
Snacks 1.47
Soups, Sauces, and Gravies 0.20
Spices and Herbs 2.75
Sweets 0.36
Vegetables and Vegetable Products 0.33
Length: 2246
<class 'pandas.core.frame.DataFrame'>
MultiIndex: 467 entries, (u'Amino Acids', u'Alanine', 48) to (u'Vitamins', u'Vitamin K (phylloquinone)', 395)
Data columns:
nutrient 467 non-null values
nutgroup 467 non-null values
units 467 non-null values
value 467 non-null values
id 467 non-null values
food 467 non-null values
fgroup 467 non-null values
manufacturer 444 non-null values
dtypes: float64(1), int64(1), object(6)
value food
nutgroup nutrient
Amino Acids Alanine 8.009 Gelatins, dry powder, unsweetened
Arginine 7.436 Seeds, sesame flour, low-fat
Aspartic acid 10.203 Soy protein isolate
Cystine 1.307 Seeds, cottonseed flour, low fat (glandless)
Glutamic acid 17.452 Soy protein isolate
nutrient
Alanine Gelatins, dry powder, unsweetened
Arginine Seeds, sesame flour, low-fat
Aspartic acid Soy protein isolate
Cystine Seeds, cottonseed flour, low fat (glandless)
Glutamic acid Soy protein isolate
Glycine Gelatins, dry powder, unsweetened
Histidine Whale, beluga, meat, dried (Alaska Native)
Hydroxyproline KENTUCKY FRIED CHICKEN, Fried Chicken, ORIGINA...
Isoleucine Soy protein isolate, PROTEIN TECHNOLOGIES INTE...
Leucine Soy protein isolate, PROTEIN TECHNOLOGIES INTE...
Lysine Seal, bearded (Oogruk), meat, dried (Alaska Na...
Methionine Fish, cod, Atlantic, dried and salted
Phenylalanine Soy protein isolate, PROTEIN TECHNOLOGIES INTE...
Proline Gelatins, dry powder, unsweetened
Serine Soy protein isolate, PROTEIN TECHNOLOGIES INTE...
Threonine Soy protein isolate, PROTEIN TECHNOLOGIES INTE...
Tryptophan Sea lion, Steller, meat with fat (Alaska Native)
Tyrosine Soy protein isolate, PROTEIN TECHNOLOGIES INTE...
Valine Soy protein isolate, PROTEIN TECHNOLOGIES INTE...
Name: food
[Finished in 14.1s]
《利用python进行数据分析》读书笔记--第七章 数据规整化:清理、转换、合并、重塑(三)的更多相关文章
- 《利用Python进行数据分析》笔记---第6章数据加载、存储与文件格式
写在前面的话: 实例中的所有数据都是在GitHub上下载的,打包下载即可. 地址是:http://github.com/pydata/pydata-book 还有一定要说明的: 我使用的是Python ...
- 《利用Python进行数据分析》笔记---第5章pandas入门
写在前面的话: 实例中的所有数据都是在GitHub上下载的,打包下载即可. 地址是:http://github.com/pydata/pydata-book 还有一定要说明的: 我使用的是Python ...
- 《利用Python进行数据分析》笔记---第4章NumPy基础:数组和矢量计算
写在前面的话: 实例中的所有数据都是在GitHub上下载的,打包下载即可. 地址是:http://github.com/pydata/pydata-book 还有一定要说明的: 我使用的是Python ...
- 《利用Python进行数据分析》笔记---第2章--1880-2010年间全美婴儿姓名
写在前面的话: 实例中的所有数据都是在GitHub上下载的,打包下载即可. 地址是:http://github.com/pydata/pydata-book 还有一定要说明的: 我使用的是Python ...
- 《利用Python进行数据分析》笔记---第2章--MovieLens 1M数据集
写在前面的话: 实例中的所有数据都是在GitHub上下载的,打包下载即可. 地址是:http://github.com/pydata/pydata-book 还有一定要说明的: 我使用的是Python ...
- 《利用Python进行数据分析》笔记---第2章--来自bit.ly的1.usa.gov数据
写在前面的话: 实例中的所有数据都是在GitHub上下载的,打包下载即可. 地址是:http://github.com/pydata/pydata-book 还有一定要说明的: 我使用的是Python ...
- 【python】《利用python进行数据分析》笔记
[第三章]ipython C-a 到行首 C-e 到行尾 %timeit 测量语句时间,%time是一次,%timeit是多次. %pdb是自动调试的开关. %debug中,可以用b 12在第12行设 ...
- Getting Started With Hazelcast 读书笔记(第七章)
第七章 部署策略 Hazelcast具有适应性,能根据不同的架构和应用进行特定的部署配置,每个应用可以根据具体情况选择最优的配置: 数据与应用紧密结合的模式(重点,of就是这种) 胖客户端模式(最好用 ...
- 《利用python进行数据分析》读书笔记--第六章 数据加载、存储与文件格式
http://www.cnblogs.com/batteryhp/p/5021858.html 输入输出一般分为下面几类:读取文本文件和其他更高效的磁盘存储格式,加载数据库中的数据.利用Web API ...
随机推荐
- 关于MVC4.0中@Styles.Render用法与详解
本文分享于http://keleyi.com/a/bjac/q74dybjc.htm文章,感觉写的蛮好所以就拿过来做笔记了,希望对大家有帮助 最近公司的新项目用了MVC 4.0,接下来一步步把 工作中 ...
- 转:HAR(HTTP Archive)规范
HAR(HTTP Archive),是一个用来储存HTTP请求/响应信息的通用文件格式,基于JSON.这个格式的出现可以使HTTP监测工具以一种通用的格式导出所收集的数据,这些数据可以被其他支持HAR ...
- imx6 关闭调试串口
需要关闭imx6调试串口,用作普通的串口使用. 参考链接 http://blog.csdn.net/neiloid/article/details/7585876 http://www.cnblogs ...
- C++学习笔记 知识集锦(一)
1.内存管理的开销 2.函数调用框架 3.类为什么要定义在头文件 4.C++的组合 5.在类的外部定义成员函数 6.bool类型为什么可以当做int类型 7.无符号保留原则 8.C++类型检查 9.何 ...
- css给div添加0.5px的边框
具体代码实现如下: <!DOCTYPE html> <html lang="en"> <head> <meta charset=" ...
- 配置sqlserver端口
今天写java连接数据库时,出现错误:通过端口 1433 连接到主机 localhost 的 TCP/IP 连接失败.错误:“Connection refused: connect.请验证连接属性,并 ...
- PAT复杂度_最大子列和问题、最大子列和变种
01-复杂度1. 最大子列和问题 给定K个整数组成的序列{ N1, N2, ..., NK },“连续子列”被定义为{ Ni, Ni+1, ..., Nj },其中 1 <= i <= j ...
- 【C# 进阶】事件!直接上事件!
http://www.tracefact.net/csharp-programming/delegates-and-events-in-csharp.aspx ZiYang 张,何许人也?看了他写的博 ...
- win7 64位 asp+access 数据库连接出错[代码:02],请检查数据库链接文件中的连接字串
解决办法,启用32位应用程序改为true 打开“Internet 信息服务(IIS)管理器”,在最右边的窗口中点击“应用程序池”,在用到的应用程序池上点击右键,选择“高级设置”
- Java Thread wait, notify and notifyAll Example
Java Thread wait, notify and notifyAll Example Java线程中的使用的wait,notify和nitifyAll方法示例. The Object clas ...