Python日志(logging)模块,shelve,sys模块
菜鸟学python第十七天
1.logging 模块
logging模块即日志记录模块
用途:用来记录日志
为什么要记录日志:
为了日后复查,提取有用信息
如何记录文件
直接打开文件,往里写东西
直接写入文件的两个问题:(logging模块解决这两个问题)
你写的数据格式 别人看不懂
解析数据模块
logging的使用
logging模块的两种记录日志的方式
使用logging提供的模块级别函数
使用logging日志系统四大组件
<!--本质上logging模块级别函数日志记录就是对日志系统四大组件内容的封装-->
logging模块定义模块级别的常用函数级别:(从低到高,默认级别为warning,低于该级别的不打印)
debug : 最详细的日志信息,典型运用场景是问题诊断 \10
info : 记录普通信息,用于确认一切都是按照我预期的那样进行的 \20
warning : 警告信息(记录出错之前的提示信息及一些敏感操作) \30
error : 错误信息(记录程序遇到错误时的信息) \40
critical : 严重错误(当程序遇到问题 无法继续执行) \50
分级的目的
随着日志文件的增多,成千上万条,这时要提取有用的信息很慢,所以这样一来,在查看日志的时候,可以快速的定位筛选到想要的日志
import logging
logging.debug('这是第一条日志信息')
logging.info('这是第一条日志信息')
logging.warning('这是第一条日志信息')
logging.error('这是第一条日志信息')
logging.critical('这是第一条日志信息')
输出结果:
WARNING:root:这是第一条日志信息
ERROR:root:这是第一条日志信息
CRITICAL:root:这是第一条日志信息 # 默认情况下,级别warning为输出的位置时控制台,默认的日志格式为 级别:日志级别:日志信息修改默认行为(logging.basicConfig()函数)
该函数可以接收的关键字参数如下:
参数名称 描述 filename 指定输出文件的文件名,指定该信息后就不会被打印到控制台了 filemode 指定输出文件的打开模式,默认为‘a',filename 指定时才有效 level 指定日志器的日志级别 format 指定日志格式字符串,即指定日志输出时所包含的字段信息及他们的顺序 stream 指定日志输出的stream logging模块中定义好的可以用于format格式字符串
| 字段/属性名称 | 使用格式 | 描述 |
|---|---|---|
| asctime | %(asctime)s | 日志事件发生的时间--人类可读时间,如:2003-07-08 16:49:45,896 |
| created | %(created)f | 日志事件发生的时间--时间戳,就是当时调用time.time()函数返回的值 |
| relativeCreated | %(relativeCreated)d | 日志事件发生的时间相对于logging模块加载时间的相对毫秒数(目前还不知道干嘛用的) |
| msecs | %(msecs)d | 日志事件发生事件的毫秒部分 |
| levelname | %(levelname)s | 该日志记录的文字形式的日志级别('DEBUG', 'INFO', 'WARNING', 'ERROR', 'CRITICAL') |
| levelno | %(levelno)s | 该日志记录的数字形式的日志级别(10, 20, 30, 40, 50) |
| name | %(name)s | 所使用的日志器名称,默认是'root',因为默认使用的是 rootLogger |
| message | %(message)s | 日志记录的文本内容,通过 msg % args计算得到的 |
| pathname | %(pathname)s | 调用日志记录函数的源码文件的全路径 |
| filename | %(filename)s | pathname的文件名部分,包含文件后缀 |
| module | %(module)s | filename的名称部分,不包含后缀 |
| lineno | %(lineno)d | 调用日志记录函数的源代码所在的行号 |
| funcName | %(funcName)s | 调用日志记录函数的函数名 |
| process | %(process)d | 进程ID |
| processName | %(processName)s | 进程名称,Python 3.1新增 |
| thread | %(thread)d | 线程ID |
| threadName | %(thread)s | 线程名称 |
import logging logging.basicConfig(filename='mylog.txt', # 指定的日志文件名
filemode='a', # 指定的是稳健的打开模式 通常为a
level=logging.DEBUG, # 指定级别
format='%(filename)s %(levelname)s %(asctime)s \
%(message)s %(pathname)s') # 指定显示格式 logging.debug('这是一条日志信息')
logging.info('这是一条日志信息')
logging.warning('这是一条日志信息')
logging.error('这是一条日志信息')
logging.critical('这是一条日志信息') # 输出结果(mylog.txt)
#loging_test.py DEBUG 2018-12-07 19:44:25,417 这是一条日志信息 C:/Users/liusijun/PycharmProjects/loging_test.py
#loging_test.py INFO 2018-12-07 19:44:25,458 这是一条日志信息 C:/Users/liusijun/PycharmProjects/loging_test.py
#loging_test.py WARNING 2018-12-07 19:44:25,459 这是一条日志信息 C:/Users/liusijun/PycharmProjects/loging_test.py
#loging_test.py ERROR 2018-12-07 19:44:25,459 这是一条日志信息 C:/Users/liusijun/PycharmProjects/loging_test.py
#loging_test.py CRITICAL 2018-12-07 19:44:25,459 这是一条日志信息 C:/Users/liusijun/PycharmProjects/loging_test.py
日志的四大核心组件
<!--logging模块提供的模块级别的那些函数实际上也是通过这几个组件的相关类来记录日志的,只是在创建这些类时设置了一些默认值-->
Loggers 日志的生成器 负责产生一条完整的日志
Filter过滤器 负责对日志进行过滤
Handler处理器 负责将日志输出到指定位置
Formatter格式化 负责处理日志显示的格式
一条日志的生命周期
由Loger产生日志
交给filter过滤器进行过滤
交给Handler按照Formater的格式进行输出
import logging
# logger产生日志
a = logging.getLogger()
# 设置日志级别
a.setLevel(10)
# filter pass
# handler 控制日志输入到文件或终端
fh1 = logging.FileHandler(filename='a.log', encoding='utf-8') # 输出到文件
fh2 = logging.FileHandler(filename='b.log', encoding='utf-8') # 输出到文件
fh3 = logging.StreamHandler() # 输出到终端
fh1.setLevel(10)
fh2.setLevel(10)
fh3.setLevel(10)
# Formatter 控制日志输出格式
formatter1 = logging.Formatter(fmt='%(asctime)s %(module)s %(levelname)s %(message)s')
formatter2 = logging.Formatter(fmt="%(asctime)s %(module)s %(message)s",)
# logger绑定handler
a.addHandler(fh1)
a.addHandler(fh2)
a.addHandler(fh3)
# handle 绑定 Formatter
fh1.setFormatter(formatter1)
fh2.setFormatter(formatter2)
fh3.setFormatter(formatter2)
# 写日志
a.info('你好啊 !')
a.warning('你好啊 !')
a.debug('你好啊 !')
a.error('你好啊 !')
a.critical('你好啊 !')
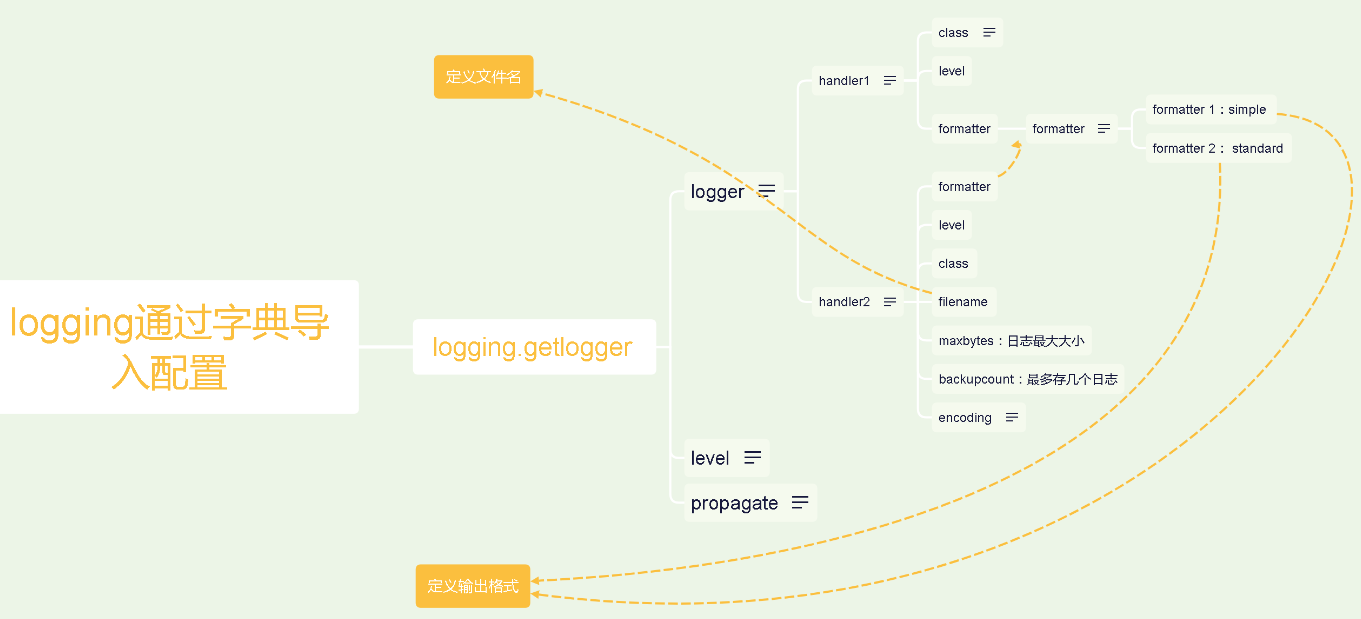
通过字典导入配置

2.shelve模块
shelve模也是一个序列化的模块
仅有一个函数,open用于打开一个文件
打开以后,操作方式与字典完全一致,你可以把它当做字典,而且自带buff的字典,可以给字典完成序列化。
同样支持python所有的基础数据类型
该模块不支持跨平台,序列化得到的数据,只能被该模块使用。
import shelve
# 序列化
a = {'name': 'jason', 'age': '', 'weight': ''}
b = {'name': 'james', 'age': '', 'weight': ''}
d = shelve.open('ds.shv')
d['jason'] = a
d['james'] = b
d.close()
运行结果:产生一个文件(不同系统有差异)
# 反序列化
d = shelve.open('ds.shv')
print(d['jason'])
print(d['james'])
d.close()
运行结果:
{'name': 'jason', 'age': '', 'weight': ''}
{'name': 'james', 'age': '', 'weight': ''}
# 如果想改文件里面的内容,则需要更改shelve默认形参writeback
d = shelve.open('ds.shv', writeback=True)
d['jason']['age'] = 18
print(d['jason'])
运行结果:
{'name': 'jason', 'age': 18, 'weight': ''}
3.sys 模块
sys模块:全称system,指的是解释器(os指的是操作系统)
常用操作,用于接收系统操作系统调用解释器传入的参数
# 1 sys.argv 命令行参数List,第一个元素是程序本身路径
print(sys.argv)
# 2 sys.exit(n) 退出程序,正常退出时exit(0)
print(sys.exit(1))
# 3 sys.version 获取Python解释程序的版本信息
print(sys.version)
# 4 sys.maxint 最大的Int值
print(sys.maxsize)
# 5 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
print(sys.path)
# 6 sys.platform 返回操作系统平台名称
print(sys.platform)
Python日志(logging)模块,shelve,sys模块的更多相关文章
- python常用模块之sys模块
python常用模块之sys模块 1.sys.argv[]:命令行参数List,第一个元素是程序本身 # 写一个简单的python程序,代码如下: #!/usr/bin/python #coding= ...
- Python库的使用之-Sys模块
Python标准库之sys模块使用详解,讲解了使用sys模块获得脚本的参数.处理模块. 使用sys模块操作 模块搜索路径.使用sys模块查找内建模块.使用sys模块查找已导入的模块,重定向输出以及重定 ...
- (转)python常用模块(模块和包的解释,time模块,sys模块,random模块,os模块,json和pickle序列化模块)
阅读目录 1.1.1导入模块 1.1.2__name__ 1.1模块 什么是模块: 在计算机程序的开发过程中,随着程序代码越写越多,在一个文件里代码就会越来越长,越来越不容易维护. 为了编写可维护的代 ...
- 时间模块之datatime模块、os模块、sys模块、json模块、json模块实操
目录 一.模块的绝对导入和相对导入 二.包的概念 三.编程思想的转变 四.软件开发目录规范 五.常见的内置模块 一.时间模块之datatime模块 1.datetime.datetime.today( ...
- Python基础(12)_python模块之sys模块、logging模块、序列化json模块、pickle模块、shelve模块
5.sys模块 sys.argv 命令行参数List,第一个元素是程序本身路径 sys.exit(n) 退出程序,正常退出时exit(0) sys.version 获取Python解释程序的版本信息 ...
- logging模块、sys模块、shelve模块
一.logging模块 1.logging模块就是用于记录日志的,日志就是记录某个时间点,发生的事情. 2.记录日志是为了日后来复查,提取有用的信息. 3.如何去记录日志:可以直接打开文件,记录信息, ...
- Python的logging模块、os模块、commands模块与sys模块
一.logging模块 import logging logging.debug('This is debug message') logging.info('This is info message ...
- Python 自学基础(四)——time模块,random模块,sys模块,os模块,loggin模块,json模块,hashlib模块,configparser模块,pickle模块,正则
时间模块 import time print(time.time()) # 当前时间戳 # time.sleep(1) # 时间延迟1秒 print(time.clock()) # CPU执行时间 p ...
- os模块,sys模块,json和pickle模块,logging模块
目录 OS模块 sys模块 json和pickle模块 序列化和反序列化 json模块 pickle logging模块 OS模块 能与操作系统交互,控制文件 / 文件夹 # 创建文件夹 import ...
随机推荐
- 测试 | 单元测试工具 | JUnit
http://junit.sourceforge.net/javadoc/org/junit/Assert.html 使用: 新建测试类: 在预测试的类上点击右键--->NEW--->Ju ...
- EM算法(徐亦达)笔记
- 使用express+mongoDB搭建多人博客 学习(5)权限控制
修改index.js如下: var express = require('express'); var router = express.Router(); var crypto=require('c ...
- Java Lambda表达式 Stream
Stream Stream不是集合元素,它不是数据结构并不保存数据,而是有关算法和计算的,更像是一个高级版本的Iterator,原始版本的Iterator,用户只能显式地一个一个遍历元素并对其进行操作 ...
- input type=file 选择图片并且实现预览效果
通过<input />标签,给它指定type类型为file,可提供文件上传: accept:可选择上传类型,如:只要传图片,且不限制图片格式,为image/*: multiple:规定是否 ...
- Dll加载总是出问题,显示无法加载
我从网上找了一个类似的问题,具体的内容如下 创建了个mfc的共享链接库,里面只有这样一个加法 _declspec(dllexport) int add(int a,int b){ return a+b ...
- log日志应用 自定义的log
package com.kxd.utils; import java.util.Hashtable; import android.util.Log; /** * The class for prin ...
- No input file specified的解决方法
(一)IIS Noinput file specified 方法一:改PHP.ini中的doc_root行,打开ini文件注释掉此行,然后重启IIS 方法二:请修改php.ini找到; cgi.for ...
- 【数据库-Azure SQL Database】如何创建事务复制将本地数据同步到 SQL Azure
Azure SQL DB 可以被配置成为 SQL Server 事务复制的一个订阅者( subscriber ). 主要应用场景有两种: 将您的数据迁移到 Azure SQL DB, 并且没有宕机时间 ...
- HDU 3377 Plan (插头DP,变形)
题意:有一个n*m的矩阵,每个格子中有一个值(可能负值),要从左上角走到右下角,求路径的最大花费. 思路: 除了起点和终点外,其他的点可以走,也可以不走. (2)我用的是括号表示法,所以起始状态为') ...