CDH5.12.1 安装部署
###通过http://192.168.50.200:7180/cmf/login 访问CM控制台
4.CDH安装
4.1CDH集群安装向导
1.admin/admin登陆到CM
2.同意license协议,点击继续

3.选择60试用,点击继续
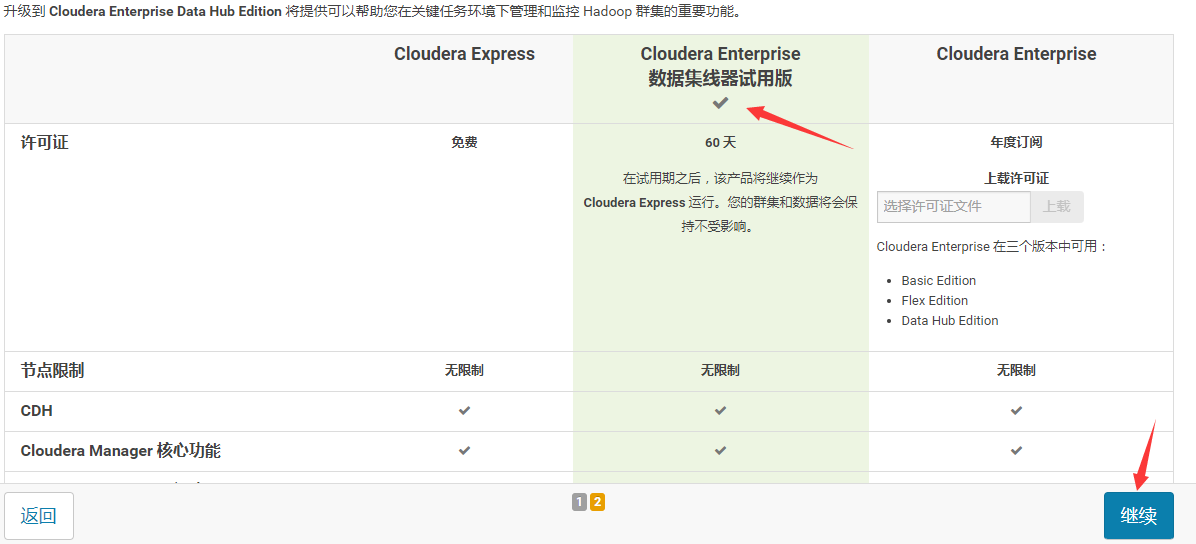
4.点击“继续”

5.输入主机IP或者名称,点击搜索找到主机名后点击继续
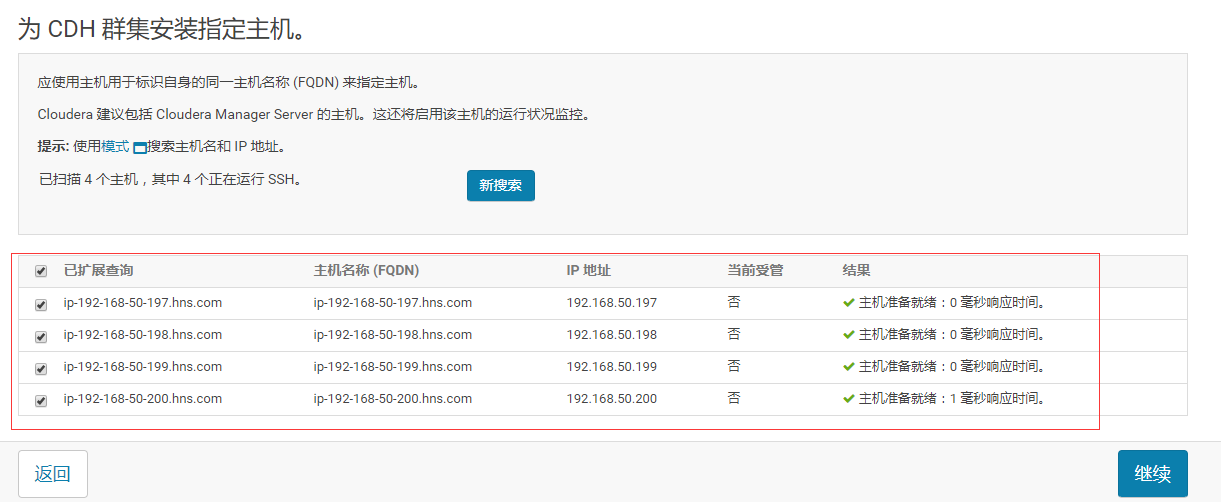
6.点击“继续”
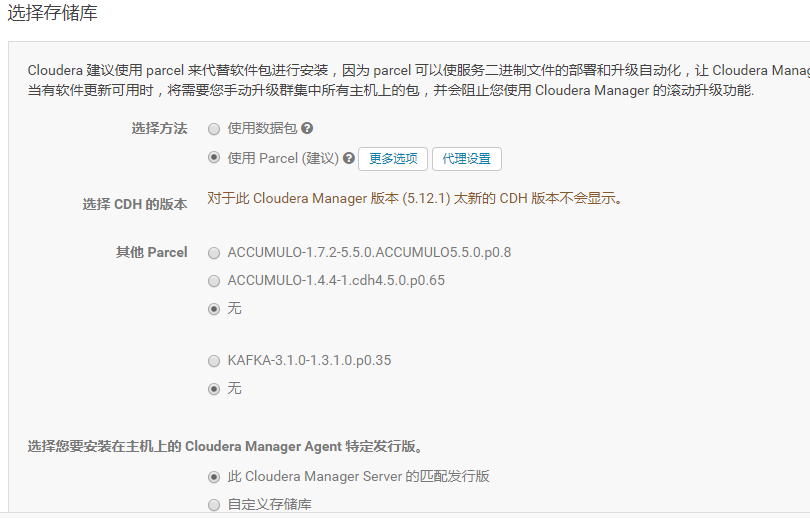
7.使用parcel选项,点击“更多选项”,点击“-”删除其他所有的地址,输入http://ip-192-168-50-200.hns.com/cdh5.12.1/点击“保存更改”
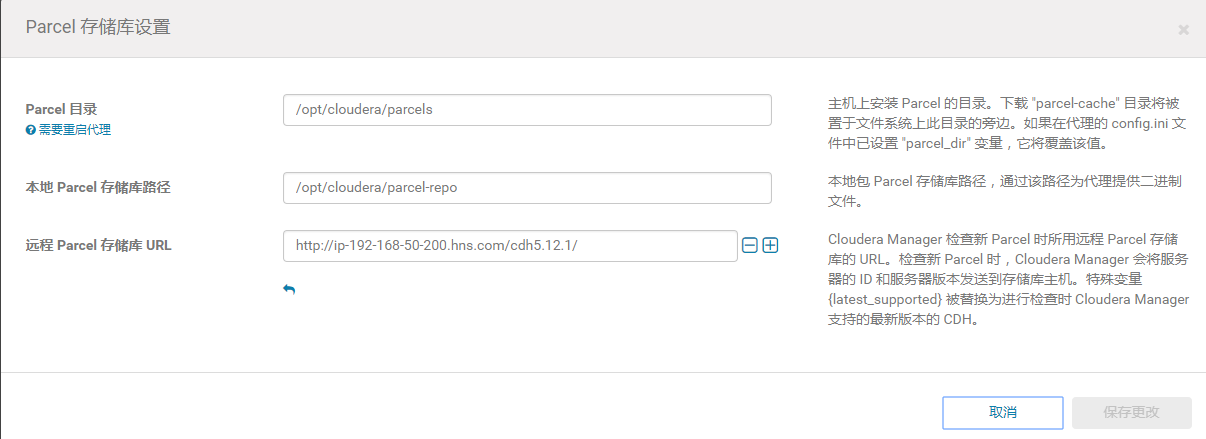
8.选择自定义存储库,输入cm的http地址
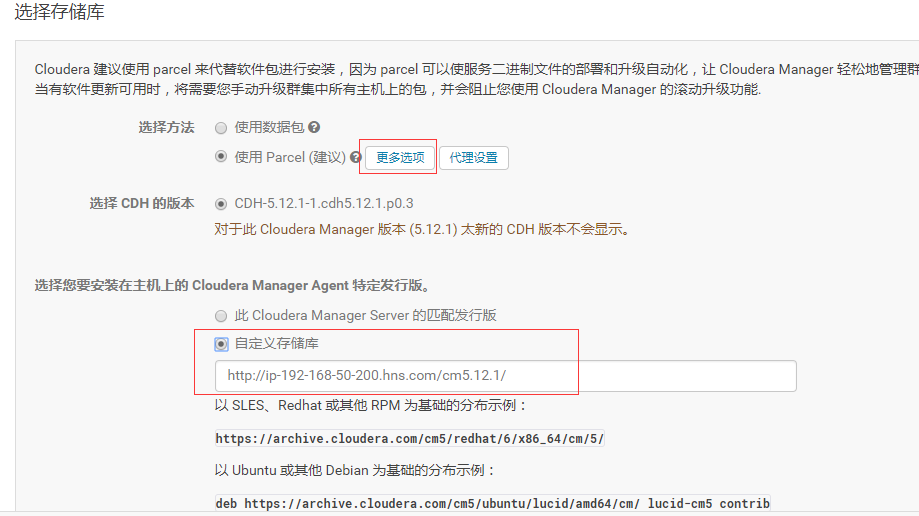
9.点击“继续”,进入下一步安装jdk

10.点击“继续”,进入下一步,默认多用户模式
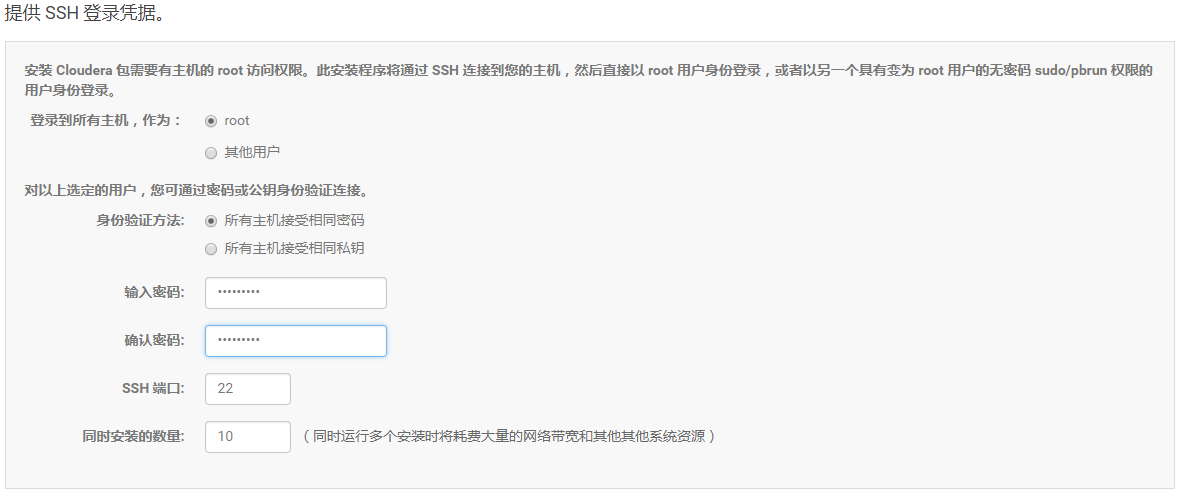
11.点击“继续”,进入下一步配置ssh账号密码:
12.点击“继续”,进入下一步,安装Cloudera Manager相关到各个节点
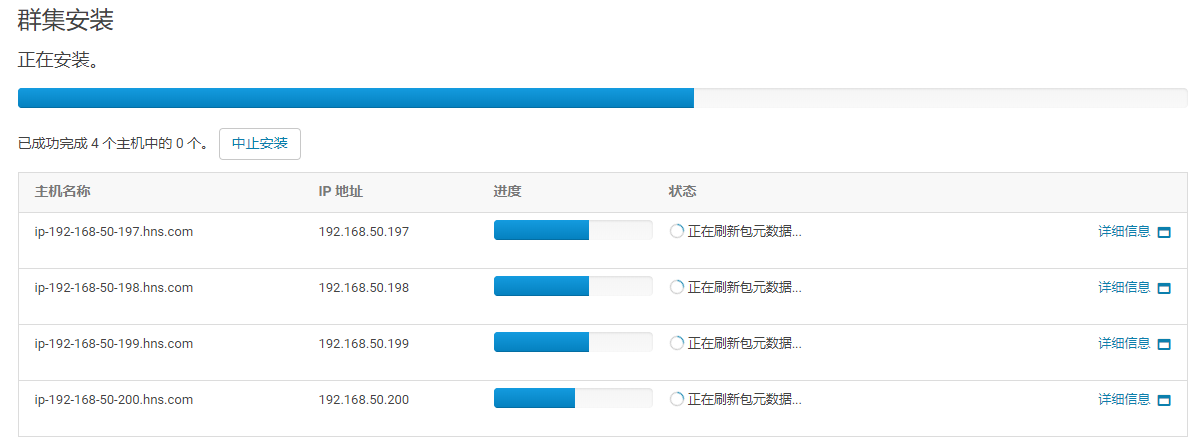

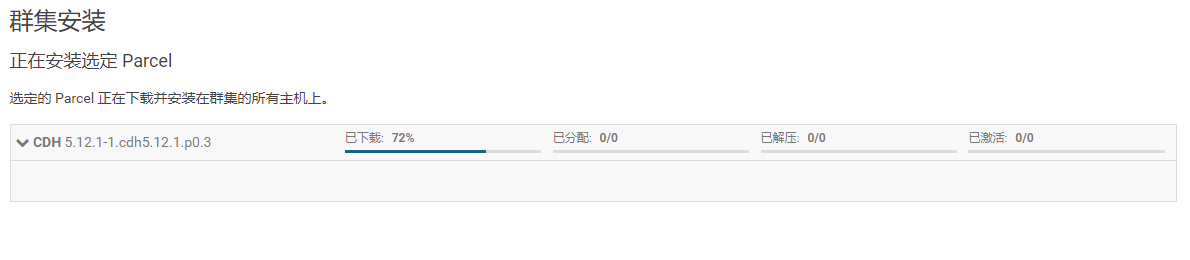
13.点击“继续”,进入下一步安装cdh到各个节点

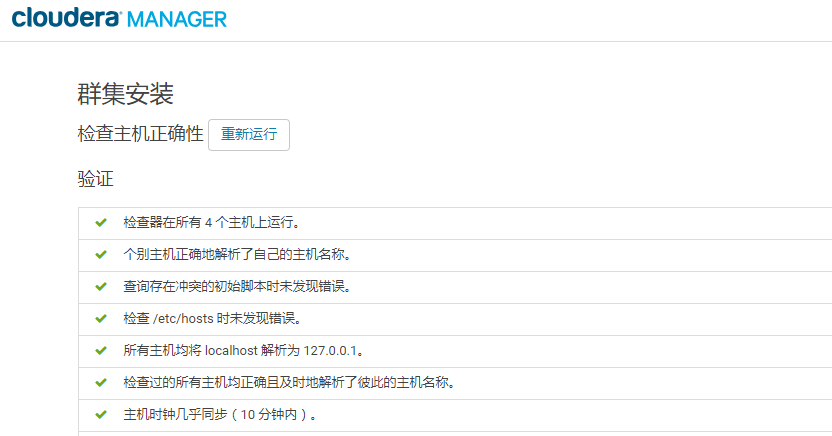
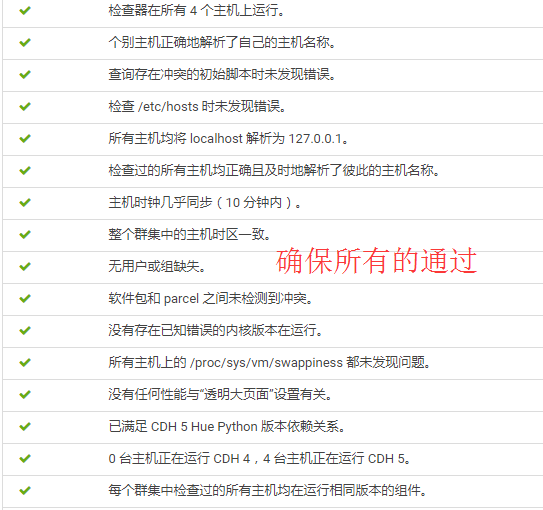
14.点击“继续”,进入下一步主机检查,确保所有检查项均通过

上述的解决方案:
在每台机器上执行如下操作:
[root@ip-192-168-50-200 ~]# echo never > /sys/kernel/mm/transparent_hugepage/enabled
[root@ip-192-168-50-200 ~]# echo never > /sys/kernel/mm/transparent_hugepage/defrag
[root@ip-192-168-50-200 ~]# echo "vm.swappiness = 10" >> /etc/sysctl.conf
[root@ip-192-168-50-200 ~]# sysctl -p
点击完成进入服务安装向导!!!
4.2 集群设置安装向导
1.选择需要安装的服务,此处使用自定义服务,如下图


2.点击“继续”,进入集群角色分配
HDFS角色分配:

Hive角色分配:

Cloudera Manager Service 角色分配:

Spark角色分配:(Spark on Yarn 所以没有spark的master和worker 角色)

Yarn角色分配:

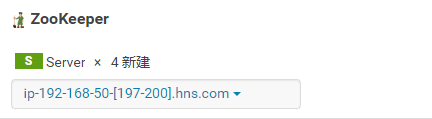
Zookeeper角色分配:(至少3个Server)
3.角色分配完成点击“继续”,进入下一步,测试数据库连接
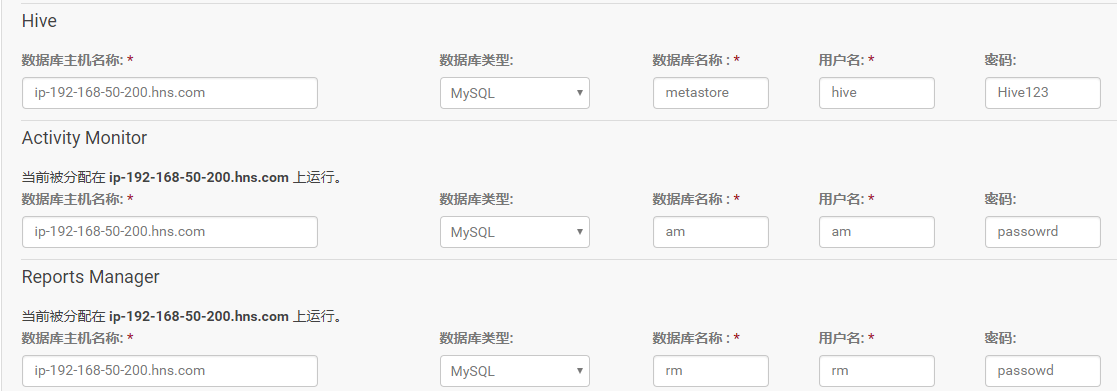
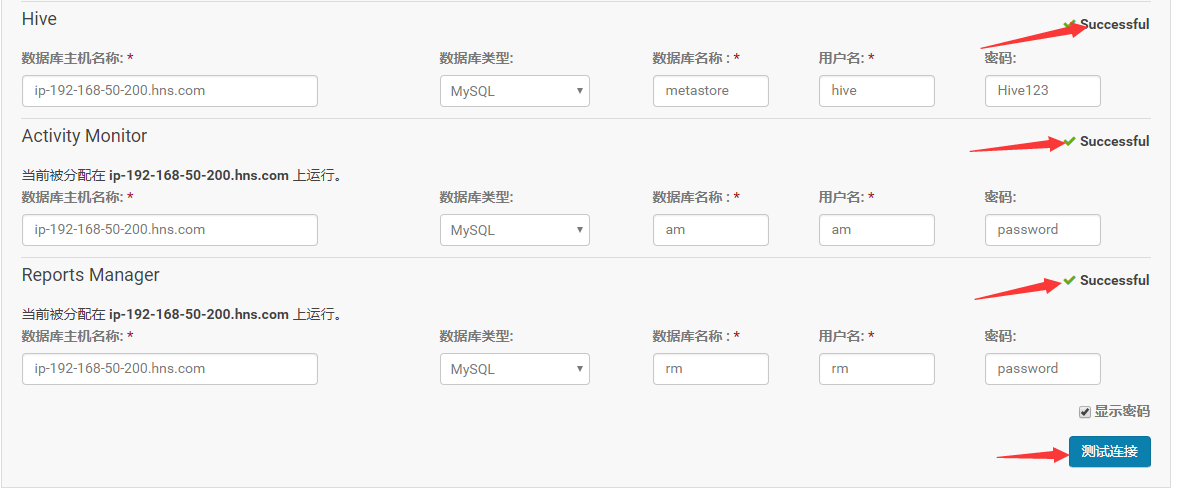
4.测试成功,点击“继续”,进入目录设置,此处使用默认默认目录,根据实际情况进行目录修改



5.点击“继续”,等待服务启动成功!!!
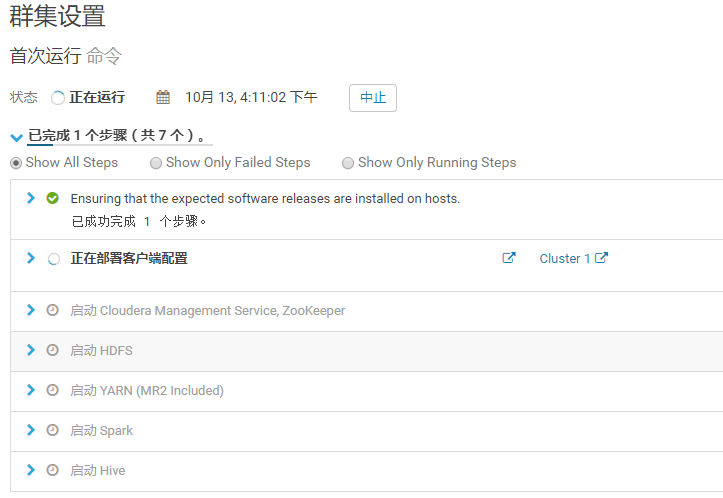
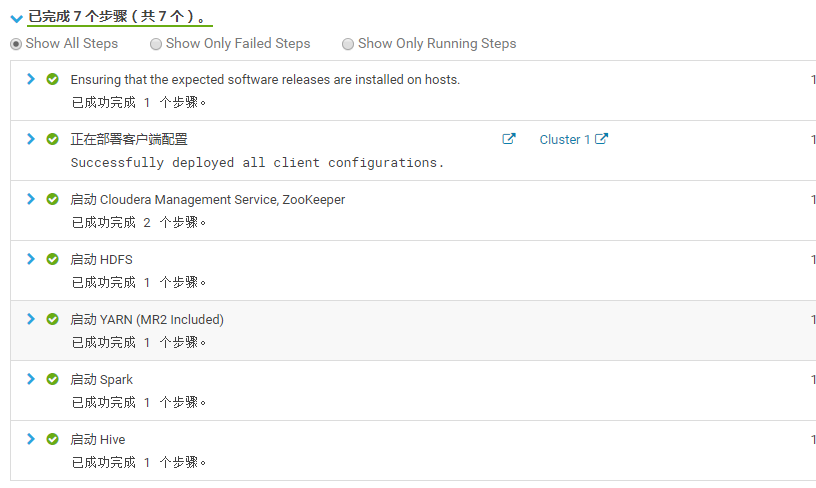
6.点击“继续”,显示集群安装成功!

7.安装成功后,进入home管理界面

5.快速组建服务验证
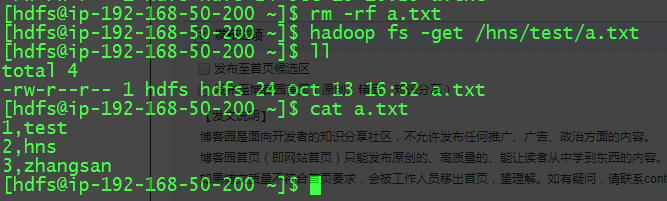
5.1HDFS验证(mkdir+put+cat +get)
mkdir操作:

put 操作:


cat 操作:

get 操作:
5.2 Hive 验证
使用hive命令行操作
hive> create external table test_table(
> s1 string,
> s2 string
> )row format delimited fields terminated by ','
> stored as textfile location '/hns/test';
OK
Time taken: 0.074 seconds
hive> show tables;
OK
test_table
Time taken: 0.012 seconds, Fetched: row(s)
hive> select * from test_table;
OK
1 test
2 hns
3 zhangsan
Time taken: 0.054 seconds, Fetched: 3 row(s)
hive>
hive> insert into test_table values("","lisi");
Query ID = hdfs_20181013220202_823a17d7-fb58-40e9-bf33-11f44d0de10a
Total jobs =
Launching Job out of
Number of reduce tasks is set to since there's no reduce operator
Starting Job = job_1539418452562_0003, Tracking URL = http://ip-192-168-50-200.hns.com:8088/proxy/application_1539418452562_0003/
Kill Command = /opt/cloudera/parcels/CDH-5.12.-.cdh5.12.1.p0./lib/hadoop/bin/hadoop job -kill job_1539418452562_0003
Hadoop job information for Stage-: number of mappers: ; number of reducers:
-- ::, Stage- map = %, reduce = %
-- ::, Stage- map = %, reduce = %, Cumulative CPU 0.93 sec
MapReduce Total cumulative CPU time: msec
Ended Job = job_1539418452562_0003
Stage- is selected by condition resolver.
Stage- is filtered out by condition resolver.
Stage- is filtered out by condition resolver.
Moving data to: hdfs://ip-192-168-50-200.hns.com:8020/hns/test/.hive-staging_hive_2018-10-13_22-02-31_572_2687237229927791201-1/-ext-10000
Loading data to table default.test_table
Table default.test_table stats: [numFiles=, numRows=, totalSize=, rawDataSize=]
MapReduce Jobs Launched:
Stage-Stage-: Map: Cumulative CPU: 0.93 sec HDFS Read: HDFS Write: SUCCESS
Total MapReduce CPU Time Spent: msec
OK
Time taken: 19.016 seconds
hive> select * from test_table;
OK
lisi
test
hns
zhangsan
Time taken: 0.121 seconds, Fetched: row(s)
hive>
Hive MapReduce操作:
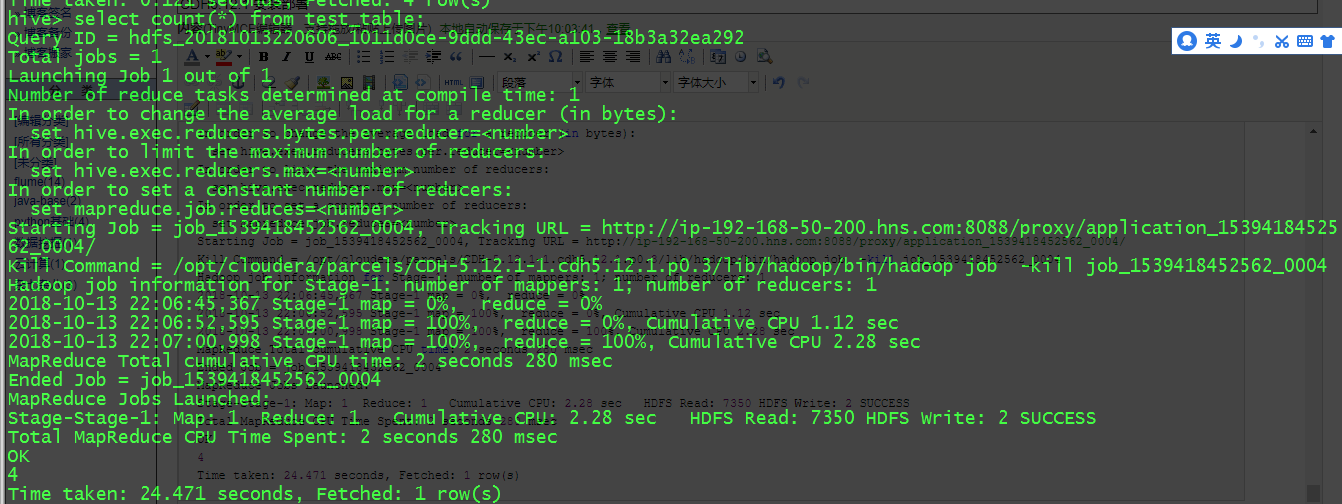
hive> select count(*) from test_table;
Query ID = hdfs_20181013220606_1011d0ce-9ddd-43ec-a103-18b3a32ea292
Total jobs =
Launching Job out of
Number of reduce tasks determined at compile time:
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1539418452562_0004, Tracking URL = http://ip-192-168-50-200.hns.com:8088/proxy/application_1539418452562_0004/
Kill Command = /opt/cloudera/parcels/CDH-5.12.-.cdh5.12.1.p0./lib/hadoop/bin/hadoop job -kill job_1539418452562_0004
Hadoop job information for Stage-: number of mappers: ; number of reducers:
-- ::, Stage- map = %, reduce = %
-- ::, Stage- map = %, reduce = %, Cumulative CPU 1.12 sec
-- ::, Stage- map = %, reduce = %, Cumulative CPU 2.28 sec
MapReduce Total cumulative CPU time: seconds msec
Ended Job = job_1539418452562_0004
MapReduce Jobs Launched:
Stage-Stage-: Map: Reduce: Cumulative CPU: 2.28 sec HDFS Read: HDFS Write: SUCCESS
Total MapReduce CPU Time Spent: seconds msec
OK Time taken: 24.471 seconds, Fetched: row(s)
5.3 MapReduce 验证:
[hdfs@ip---- hadoop-mapreduce]$ pwd
/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce
[hdfs@ip---- hadoop-mapreduce]$ hadoop jar hadoop-mapreduce-examples.jar pi
Number of Maps =
Samples per Map =
Wrote input for Map #
Wrote input for Map #
Wrote input for Map #
Wrote input for Map #
Wrote input for Map #
Starting Job
.
.
.
// :: INFO mapreduce.Job: Running job: job_1539418452562_0005
// :: INFO mapreduce.Job: Job job_1539418452562_0005 running in uber mode : false
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: Job job_1539418452562_0005 completed successfully
// :: INFO mapreduce.Job: Counters:
File System Counters
.
.
.
5.4 Spark 验证
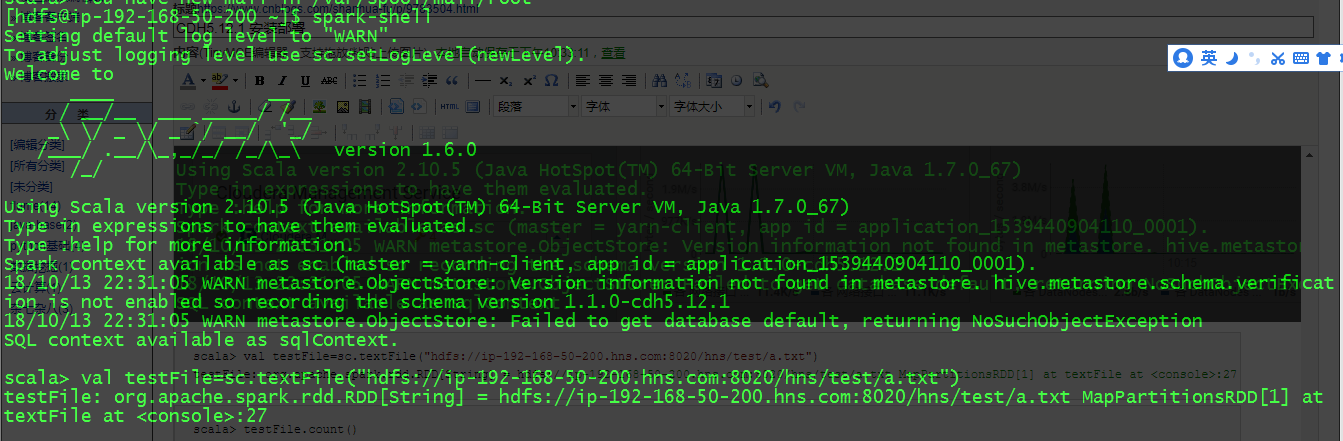
scala> val testFile=sc.textFile("hdfs://ip-192-168-50-200.hns.com:8020/hns/test/a.txt")
testFile: org.apache.spark.rdd.RDD[String] = hdfs://ip-192-168-50-200.hns.com:8020/hns/test/a.txt MapPartitionsRDD[1] at textFile at <console>:27
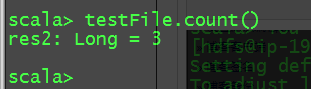
scala> testFile.count()
res2: Long =
CDH5.12.1 安装部署的更多相关文章
- CDH-5.12.2安装教程
CDH是Cloudera公司提供的Hadoop发行版,它在原生开源的Apache Hadoop基础之上,针对特定版本的Hadoop以及Hadoop相关的软件,如Zookeeper.HBase.Flum ...
- CentOS7安装CDH 第六章:CDH的管理-CDH5.12
相关文章链接 CentOS7安装CDH 第一章:CentOS7系统安装 CentOS7安装CDH 第二章:CentOS7各个软件安装和启动 CentOS7安装CDH 第三章:CDH中的问题和解决方法 ...
- rabbitmq安装部署
本文主要介绍rabbitmq-server-3.6.12的安装部署 # 检查是否已经安装旧版本的软件 rpm -qa|grep erlang rpm -qa|grep rabbitmq # 如果之前 ...
- 【Spark学习】Spark 1.1.0 with CDH5.2 安装部署
[时间]2014年11月18日 [平台]Centos 6.5 [工具]scp [软件]jdk-7u67-linux-x64.rpm spark-worker-1.1.0+cdh5.2.0+56-1.c ...
- CENTOS6.5安装CDH5.12.1(一) https://mp.weixin.qq.com/s/AP_m0QqKgzEUfjf0PQCX-w
CENTOS6.5安装CDH5.12.1(一) 原创: Fayson Hadoop实操 2017-09-13 温馨提示:要看高清无码套图,请使用手机打开并单击图片放大查看. 1.概述 本文档主要描 ...
- 在Ubuntu 12.10 上安装部署Openstack
OpenStack系统有几个关键的项目,它们能够独立地安装但是能够在你的云计算中共同工作.这些项目包括:OpenStack Compute,OpenStack Object Storage,OpenS ...
- 阿里云三台CentOS7.2配置安装CDH5.12
1 购买3台阿里云服务 2 配置好ssh连接客户端 根据自己情况连接 3 安装好MySQL5.7 跳过,见之前博客 安装在hadoop001上 4 设置好Hosts文件 3台机器同时操作 vim /e ...
- Linux平台Oracle 12.1.0.2 单实例安装部署
主题:Linux平台Oracle 12.1.0.2 单实例安装部署 环境:RHEL 6.5 + Oracle 12.1.0.2 需求:安装部署OEM 13.2需要Oracle 12.1.0.2版本作为 ...
- 1.安装CDH5.12.x
安装方式安装前准备安装步骤安装过程修改/etc/hosts设置ssh 互信修改linux 系统设置安装JDK1.8安装python2.7安装mysql/postgreysql数据库安装ntp设置本地y ...
随机推荐
- HDU 2242 考研路茫茫——空调教室(边双连通)
HDU 2242 考研路茫茫--空调教室 题目链接 思路:求边双连通分量.然后进行缩点,点权为双连通分支的点权之和,缩点完变成一棵树,然后在树上dfs一遍就能得出答案 代码: #include < ...
- Enumerate Combination C(k, n) in a bitset
Suppose n<=32, we can enumerate C(k, n), with bits representing absence or presence, in the follo ...
- Android—— 4.2 Vold挂载管理_NetlinkManager (四)
在前文Android-- 4.2 Vold挂载管理_主体构建main (一)中有结构图表示,Vold是kernel与用户层的一个交互管理模块. Android-- 4.2 Vold挂载管理_Volum ...
- C#高级编程 第十五章 反射
(二)自定义特性 使自定义特性非常强大的因素时使用反射,代码可以读取这些元数据,使用它们在运行期间作出决策. 1.编写自定义特性 定义一个FieldName特性: [AttributeUsage(At ...
- mac上利用minikube搭建kubernetes(k8s)环境
友情提示:对于初次接触k8s的同学,强烈建议先看看本文最后的参考文章. 环境: mac os(Mojave) 前提:先安装好kubectl (brew install kubectl) .docker ...
- Git 自己的一些工作中的总结
这个网址很重要:https://gitee.com/progit/2-Git-%E5%9F%BA%E7%A1%80.html#2.4-%E6%92%A4%E6%B6%88%E6%93%8D%E4%BD ...
- COGS1532. [IOI2001]移动电话
1532. [IOI2001]移动电话 ★☆ 输入文件:mobilephones.in 输出文件:mobilephones.out 简单对比时间限制:5 s 内存限制:256 MB [ ...
- 【BZOJ2654】tree 二分+最小生成树
[BZOJ2654]tree Description 给你一个无向带权连通图,每条边是黑色或白色.让你求一棵最小权的恰好有need条白色边的生成树. 题目保证有解. Input 第一行V,E,need ...
- Eclipse打jar包的方法
1.准备主清单文件 “MANIFEST.MF” Manifest-Version: 1.0 Class-Path: lib/commons-codec.jar lib/commons-httpclie ...
- MongoDB API java的使用
1.创建一个MongoDB数据库连接对象,它默认连接到当前机器的localhost地址,端口是27017. Mongo mongo=new Mongo(); 2.获得与某个数据库(例如“test”)的 ...