oracle_SQL 实验查询及删除重复记录 依据条件 (row)
除数据库表中的重复记录 根据条件
① 创建表准备数据
创建表 tab_test
-- Create table
create table TAB_TEST
(
ID NUMBER,
NAME NVARCHAR2(10),
VALUE NVARCHAR2(10),
TIME DATE default sysdate not null
)
插入模拟数据
insert into tab_test (ID, NAME, VALUE)values (1, 'aa ', 'vv');
insert into tab_test (ID, NAME, VALUE)values (1, 'aa ', 'vv');
insert into tab_test (ID, NAME, VALUE)values (2, 'bb ', 'vv');
insert into tab_test (ID, NAME, VALUE)values (2, 'bb ', 'vv');
insert into tab_test (ID, NAME, VALUE)values (3, 'cc ', 'vv');
insert into tab_test (ID, NAME, VALUE)values (3, 'cc ', 'vv');
insert into tab_test (ID, NAME, VALUE)values (4, 'dd ', 'vv');
insert into tab_test (ID, NAME, VALUE)values (4, 'dd ', 'vv');
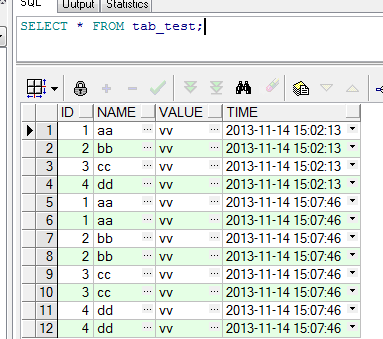
查询数据
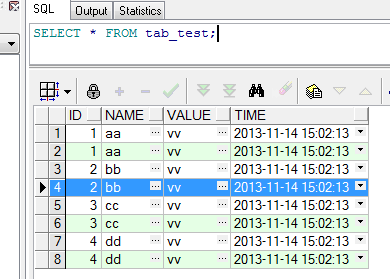
delete from tab_test
where id in (select id from tab_test group by id having count(id) > 1)
and rowid not in (select min(rowid) from tab_test group by id having count(id )>1)
oracle_SQL 实验查询及删除重复记录 依据条件 (row)的更多相关文章
- [SQL]查询及删除重复记录的SQL语句
一:查询及删除重复记录的SQL语句1.查找表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断select * from peoplewhere peopleId in (select ...
- MySQL查询及删除重复记录的方法
查询及删除重复记录的方法(一)1.查找表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断select * from peoplewhere peopleId in (select p ...
- Oracle 查询并删除重复记录的SQL语句
查询及删除重复记录的SQL语句 1.查找表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断select * from peoplewhere peopleId in (select ...
- oracle 查询及删除重复记录的SQL语句
查询及删除重复记录的SQL语句 1.查找表中多余的重复记录,重复记录是根据单个字段(Id)来判断 select * from 表 where Id in (select Id from 表 group ...
- SQL操作语句之查询及删除重复记录的方法
delete from 表 where id not in(select min(id) from 表 group by name ) //删除重复名字的记录 删除之前请用语句 select * fr ...
- MySQL中查询、删除重复记录的方法大全
查找所有重复标题的记录: select title,count(*) as count from user_table group by title having count>1; SELECT ...
- 新MySQL查询和删除重复记录
在工作中,我们经常会发现表中会存在重复数据,那么如何找出和删除这些数据呢? 下面,以一个小例子来说明: 1.创建学生表 1 CREATE TABLE student( 2 id INT PRIMARY ...
- 查询及删除重复记录的SQL语句
1.查找表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断 select * from people where peopleId in (select peopleId from ...
- ORACLE查询删除重复记录
比如现在有一人员表 (表名:peosons) 若想将姓名.身份证号.住址这三个字段完全相同的记录查询出来 复制代码 代码如下: select p1.* from persons p1,pers ...
随机推荐
- poj 3414 Pots (bfs+线索)
Pots Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 10071 Accepted: 4237 Special J ...
- Ognl底层使用
今天,在得知ognl采用.在这里和大家分享一下.我希望能帮助. package com.hcj.test; import java.util.ArrayList; import java.util.L ...
- linux根据该文件夹的读取权限和权限运行差异
假设你linux下使用ls.细心的你会发现居然夹有权限运行.例如: drwxrwxr-x 11 cl cl 4096 9 25 14:22 ./ drwxr-xr-x 49 cl cl 4096 1 ...
- ListView滑动删除 ,仿腾讯QQ
转载请表明出处:http://blog.csdn.net/lmj623565791/article/details/22961279 在CSDN上开了很多大神们的文章,感觉受益良多,也非常欣赏大家的分 ...
- 用PowerDesigner生成自定义建表语句
原文:用PowerDesigner生成自定义建表语句 我们经常用PowerDesigner来进行数据库表结构的设计,并且设计出来的表比较直观的看出之间的相互关系,方便理解:但其自动生成的脚本并不一定符 ...
- iframe滚动条问题:显示/隐藏滚动条
iframe 问题2008-01-22 16:37****** 显示 iframe 内容 XHTML 1.0 Transitional 标准不能显示 <!DOCTYPE html PUBLI ...
- UI设计学习路径(一个)—好酒也怕巷子深
来源 參与米老师对项目的验收的时候.听了老师对UI的看法才注意UI这块内容.非常奇怪为什么我们总是不能注意到本该注意的问题呢?软件开发难道仅仅是功能的实现不包含界面设计吗?当然不是.问题的根源在于我们 ...
- CI-持续集成(2)-软件工业“流水线”技术实现(转)
1 概述 持续集成(Continuous Integration)是一种软件开发实践.在本系列文章的前一章节已经对其背景及理论体系进行了介绍.本小节则承接前面提出的理论构想进行具体的技术实现. & ...
- 思维导图之C++语言程序设计总结
花了大约一周的时间,将c++的课本过了一遍,米老师说第一遍不求甚解,仅仅管去看就能够了,我很成功地运行了老师这种方法,嘿嘿.那么c++是什么呢?百度上这样说,它是一种使用很广泛的计算机编程语言.C++ ...
- Effective C++ -- 继承和面向对象设计
32.确保你的public继承了模is-a关系 public继承意味着is-a关系(里氏替换原则),一切适用于基类也适用于派生类. 矩形继承正方形问题: 可实施与矩形的操作无法实施与正方形 在编程领域 ...