浅析SQL查询语句未显式指定排序方式,无法保证同样的查询每次排序结果都一致的原因
本文出处:http://www.cnblogs.com/wy123/p/6189100.html
标题有点拗口,来源于一个开发人员遇到的实际问题
先抛出问题:一个查询没有明确指定排序方式,那么,第二次执行这个同样的查询的时候,查询结果会不会与第一次的查询结果排序方式完全一样?
答案是不确定的,两个完全一样的查询,结果也完全一样,两次(多次)查询结果的排序方式有可能一致,有可能不一致。
如果不一致,又是什么原因导致同样的查询默认排序方式不一致?
以下简单分析几种情况,说明为什么查询同样的查询会出现默认排序结果不一样的情况。当然对于该问题,包含但不限于以下几种情况。
场景1:并行查询导致默认结果集的排序是随机的
按照惯例,先造一个表供测试
create table TestDefaultOrder1
(
id int identity(1,1) primary key,
col2 varchar(50),
col3 varchar(50),
col4 varchar(50),
col5 varchar(50),
col6 varchar(50),
col7 varchar(50),
col8 varchar(50),
CreateDate Datetime
)
go declare @i int =0
begin tran
while @i<500000
begin
insert into TestDefaultOrder1 values (NEWID(),NEWID(),NEWID(),NEWID(),NEWID(),NEWID(),NEWID(),GETDATE()-RAND()*500)
set @i=@i+1
end
commit
测试场景:
这里先不考虑索引之类的性能问题,
如图是一个测试结果的示例,可以看到,两个查询的条件是完全一样的,都没有显式指定排序列,默认结果的排序是完全不一样的
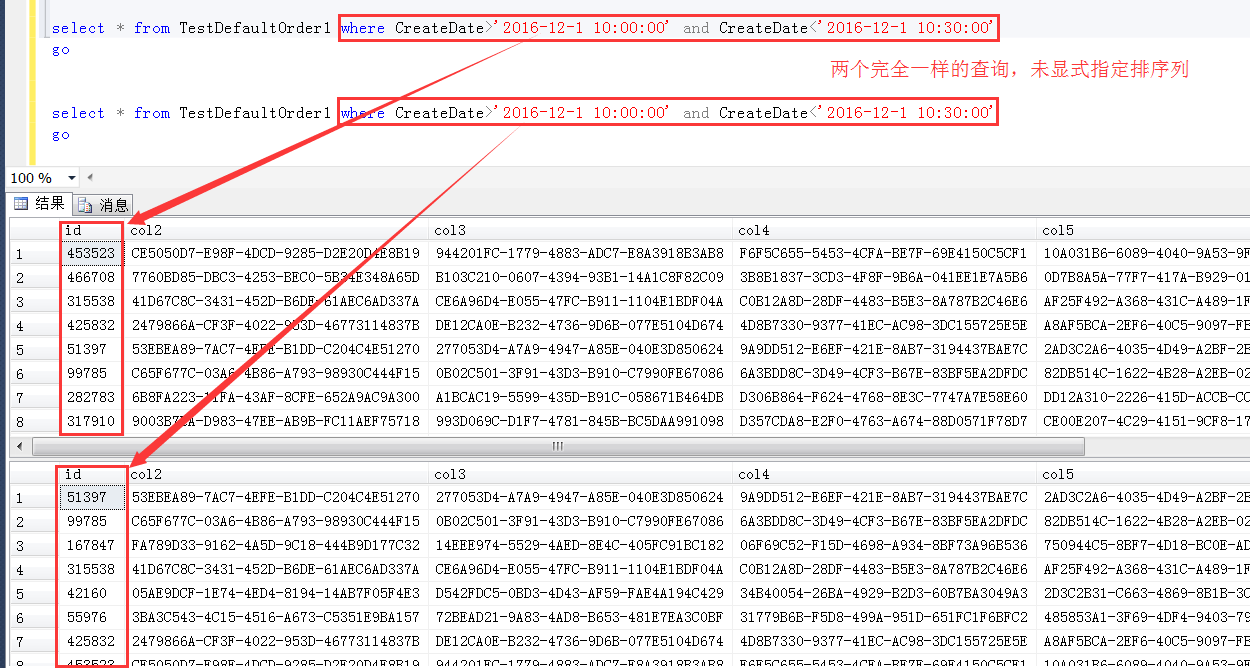
甚至可以用同样的条件做三次查询(可以更多次),结果依然都是完全不一致的

原因分析:
为什么一样的查询,每次查询结果的排序都不一样,正如上面所说,这种情况下是并行查询导致的。
查询引擎采用什么样的执行计划是基于代价考虑的,如果一旦发现一个查询的执行代价超过一定的阈值,就有可能采用并行的方式来处理,
如果采用了并行查询的方式,就会采用多个线程来分解整个查询任务,而每一个线程分配的任务量是无法固定的,同时,合并每个线程的结果顺序也是不固定的
这就导致了最终的查询结果的顺序是不固定的。
截图即为并行查询的每个线程分配的任务量示例。
如图,当前这个查询,第一个线程返回的行数是2,但是无法保证第二次查询的第一个线程返回的行数也是2,
即便是第二次返回的行数是2,也无法保证返回的2行与第一次返回的两行数据一样的
同时,在合并各个线程的结果集的时候,依据线程返回的时间来的,理论上讲也是不确定的,多个不确定因素在一起,就造成了最终的结果集排序(可以认为)是随机的。

有人说,只要执行计划一样,查询默认排序就一样,其实也是不对的,因为即便是执行计划一样,只要SQLServer开启了并行查询,默认排序都是无法保证一直的
场景2:物理存储导致默认结果的随机性
同样,先造一个测试数据的case,如下,创建一个堆表,
create table TestDefaultOrder2
(
id int identity(1,1),
col2 char(5000)
)
go declare @i int =0
begin tran
while @i<50
begin
insert into TestDefaultOrder2 values (NEWID())
set @i=@i+1
end
commit
测试场景:
这个场景排除了上述并行查询的影响,因为只有50条数据,根本不会启用并行查询
如截图,两次查询之间执行了一次表的重建动作,同样是数据本身没有发生任何变化,两次查询的默认顺序完全不一样
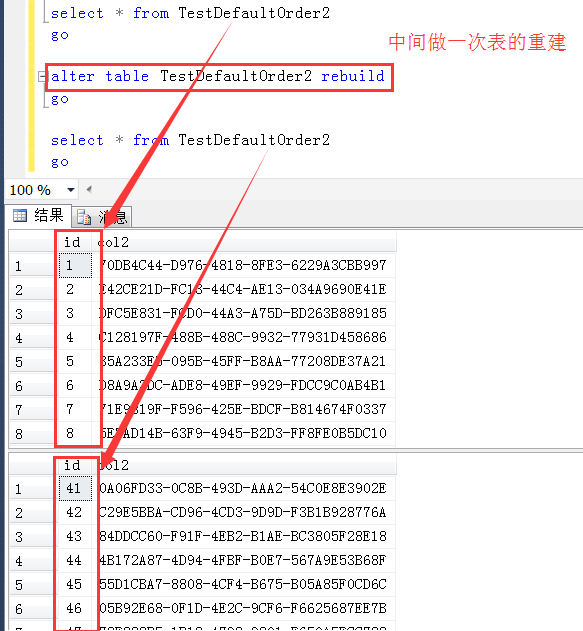
甚至在重建一次,查询结果仍然与上面两次还是都不一样的。
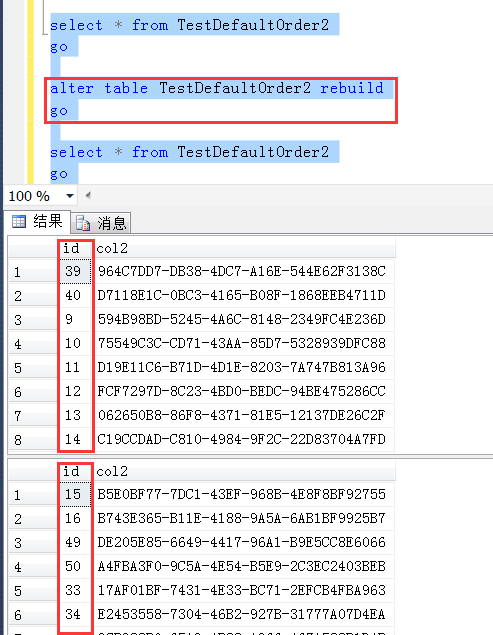
原因分析:
堆表的特点决定了堆内的数据行和数据页没有任何固定的顺序,整个堆内的数据在物理存储发生了变化之后,
在对查询(对堆表扫描)的过程中得不到一个与物理存储变化之前完全一样的顺序。
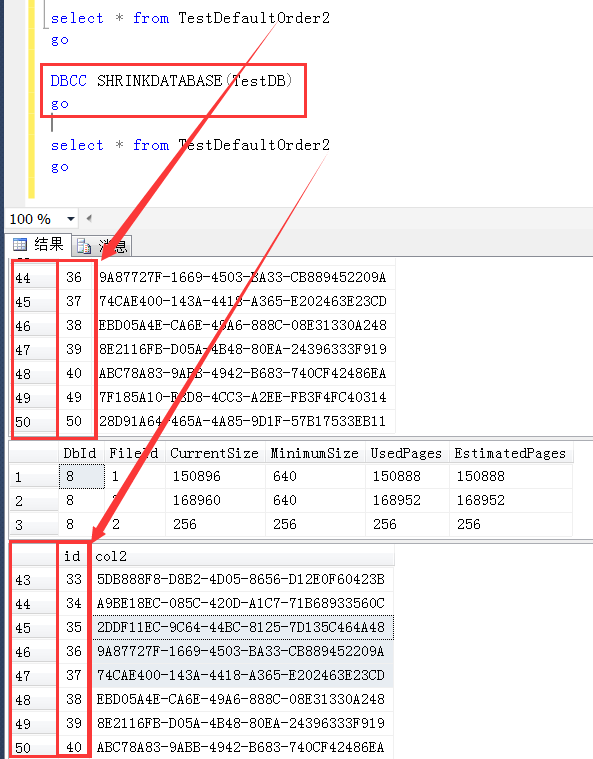
除了上述的重建表会导致查询的默认顺序不一致,其他影响物理空间的操作,都会影响堆表数据页面的物理存储位置,
比如这里再执行一次数据库的收缩,收缩之后的查询与收缩之前的查询顺序依旧是不一样的,我可没有动你表和你表中的任何一条数据,但你不能阻止我正常的数据库维护操作。
总之,一旦影响到物理存储位置,堆表的默认扫描结果顺序都有可能不一样。
以上仅仅通过单表查询来说明,如果未显式指定排序方式,即便是同样的查询条件,查询结果的顺序是无法保证每次都一致的,
如果是多表关联,或者是考虑到索引,数据库维护等操作,情况将变得更加复杂,比如这个也比较有意思:http://www.cnblogs.com/wy123/p/5425946.html
比较特殊的是:没有显式指定排序方式,
1,某段一个时间段内,查询结果可能是按照预期结果排序的,某个时间段内就不是了(物理存储改变的影响);
2,某些查询条件下是按照预期结果排序的,改变一下查询条件,排序结果就变得面目全非了(执行计划改变的影响)。
总之一句话:没有显式执行排序方式,不要期待查询结果每次都是预期的排序方式,甚至每次都不一样。
总结:
本文通过两个简单的示例,
从执行计划和物理存储两个方面,说明了“如果查询SQL没有显式指定排序方式,查询结果的顺序是无法保证总是按照你的预期来的”。
当然也不能局限于这两种情况,极有可能还有很多原因是我没有想到的。
然而话不能说死,某些条件下没有显式指定排序方式,一定条件下(多次查询)可能会得到预期的排序结果,但是这种期待往往是不可靠的。
“昨天系统查询结果的排序还是好好的,今天怎么变了?”
“为啥我用A条件查询是按照时间排序的,按照B条件查询就不是了?”
如果没有显式指定排序方式,不要问我数据库是不是有问题(或者说SQL Server这个数据库“不行”,或者说DBA说是内部原因是忽悠人的)。
所以同学,如果期望查询结果排序,不管默认是不是你预期的排序方式,都请显式指定排序方式。
浅析SQL查询语句未显式指定排序方式,无法保证同样的查询每次排序结果都一致的原因的更多相关文章
- dubbo接口方法重载且入参未显式指定序列化id导致ClassCastException分析
问题描述&模拟 线上登录接口,通过监控查看,有类型转换异常,具体报错如下图 此报错信息是dubbo consumer端显示,且登录大部分是正常,有少量部分会报类型转换异常,同事通过更换方法名+ ...
- 分析器错误消息: 类型“test.test.testx”不明确: 它可能来自程序集“F:\testProject\bin\test.test.DLL”或程序集“F:\testProject\bin \testProject.DLL”。请在类型名称中显式指定程序集。
问题描述: RT 分析器错误消息: 类型“test.test.testx”不明确: 它可能来自程序集“F:\testProject\bin\test.test.DLL”或程序集“F:\testProj ...
- explicit specialization 显式指定
//explicit specialization 显式指定 #include "stdafx.h" #include <iostream> #include < ...
- Python与数据库[2] -> 关系对象映射/ORM[4] -> sqlalchemy 的显式 ORM 访问方式
sqlalchemy 的显式 ORM 访问方式 对于sqlalchemy,可以利用一种显式的ORM方式进行访问,这种方式无需依赖声明层,而是显式地进行操作.还有一种访问方式为声明层 ORM 访问方式. ...
- sql server 自增长显式添加值
如果想在自增列添加数据,会提示我们不能插入显式值 解决:
- 表查询语句及使用-连表(inner join-left join)-子查询
一.表的基本查询语句及方法 from. where. group by(分组).having(分组后的筛选).distinct(去重).order by(排序). limit(限制) 1.单表查询: ...
- SQL查询语句如何能够让指定的记录排在最后
方法如下:select * from <表名> order by case when <条件> then 1 else 0 end asc 举例:把threads表中列id值小 ...
- addScalar 显式指定返回数据的类型
sql: select a.id as 受理 from a SQLQuery sqlQuery=this.getSession().createSQLQuery(sb.toString()).addS ...
- mysql在命令行模式下创建数据库时要显式指定字符集
create database db1 DEFAULT CHARACTER SET utf8 COLLATE utf8_chinese_ci;
随机推荐
- react-router 组件式配置与对象式配置小区别
1. react-router 对象式配置 和 组件式配置 组件式配置(Redirect) ----对应---- 对象式配置(onEnter钩子) IndexRedirect -----对应-- ...
- NodeJs之Path
Path模块 NodeJs提供的Path模块,使得我们可以对文件路径进行简单的操作. API var path = require('path'); var path_str = '\\Users\\ ...
- Storm如何保证可靠的消息处理
作者:Jack47 PS:如果喜欢我写的文章,欢迎关注我的微信公众账号程序员杰克,两边的文章会同步,也可以添加我的RSS订阅源. 本文主要翻译自Storm官方文档Guaranteeing messag ...
- 将 instance 部署到 OVS Local Network - 每天5分钟玩转 OpenStack(130)
上一节创建了 OVS 本地网络 first_local_net,今天我们会部署一个 instance 到该网络并分析网络结构.launch 一个 instance,选择 first_local_net ...
- Javacript实现字典结构
字典是一种用[键,值]形式存储元素的数据结构.也称作映射,ECMAScript6中,原生用Map实现了字典结构. 下面代码是尝试用JS的Object对象来模拟实现一个字典结构. <script& ...
- bzoj3095--数学题
题目大意:给定一个长度为n的整数序列x[i],确定一个二元组(b, k)使得S=Σ(k*i+b- x[i])^2(i∈[0,n-1])最小 看Claris大神的题解就行了.实际上就是用2次二次函数的性 ...
- java中的内部类
/** * 内部类 ?? * 定义在一个内部的类,被称为内部类. * 内部类里有类体,方法体 * 内部类所在的类,被称为外部类. * --------------------------------- ...
- BPM配置故事之案例14-数据字典与数据联动
小明遇到了点麻烦,他昨天又收到了行政主管发来的邮件,要求把出差申请单改由H3 BPM进行,表单如下 行政主管的出差申请表 小明对表单进行了调整,设计出了一份适合在系统中使用的表单,但在"出差 ...
- Android 死锁和重入锁
死锁的定义: 1.一般的死锁 一般的死锁是指多个线程的执行必须同时拥有多个资源,由于不同的线程需要的资源被不同的线程占用,最终导致僵持的状态,这就是一般死锁的定义. package com.cxt.t ...
- Hadoop伪分布式集群环境搭建
本教程讲述在单机环境下搭建Hadoop伪分布式集群环境,帮助初学者方便学习Hadoop相关知识. 首先安装Hadoop之前需要准备安装环境. 安装Centos6.5(64位).(操作系统再次不做过多描 ...