SqlServer性能优化索引(五)
导入表结构:
select * into ProductCategory from AdventureWorksDW2014.dbo.DimProductCategory
select * into Product from AdventureWorksDW2014.dbo.DimProduct
开启磁盘io:
set statistics io on
select EnglishProductName,StandardCost,Color,Size,Weight from Product
where size>'M'--0.189 io:251
set statistics io off

非聚簇索引:
创建的语句:
create nonclustered index nc_product_size on product(size)
再次执行上面的查询代码(提高了三倍):
set statistics io on
select EnglishProductName,StandardCost,Color,Size,Weight from Product
where size>'M' --0.054 io:19
set statistics io off

建立覆盖索引:
create nonclustered index nc_product_size1 on product(size) include(EnglishProductName,
StandardCost,Color,Weight)
再次执行上述语句:
set statistics io on
select EnglishProductName,StandardCost,Color,Size,Weight from Product
where size>'M' --0.003 io:2
set statistics io off
数据库会自动选择索引:


没有创建索引的情况:
set statistics io on
select c.EnglishProductCategoryName,p.EnglishProductName,p.Color,p.Size
from product as p inner join ProductCategory as c on p.ProductSubcategoryKey=c.ProductCategoryKey
where c.ProductCategoryKey=1 --0.1928
set statistics io off
创建索引:
create nonclustered index nc_productcategory_key on ProductCategory(ProductcategoryKey) include
(EnglishProductCategoryName)
在次查询:
set statistics io on
select c.EnglishProductCategoryName,p.EnglishProductName,p.Color,p.Size
from product as p inner join ProductCategory as c on p.ProductSubcategoryKey=c.ProductCategoryKey
where c.ProductCategoryKey=1 --0.1928 io:c 2 p 251
set statistics io off
IO情况:
由此可见 Product表影响比较严重 251
建立一个非聚簇索引:(做一个物理排序)
create nonclustered index nc_product_categorykey on product(productsubcategorykey) include
(englishproductname,color,size)
执行语句:
set statistics io on
select c.EnglishProductCategoryName,p.EnglishProductName,p.Color,p.Size
from product as p inner join ProductCategory as c on p.ProductSubcategoryKey=c.ProductCategoryKey
where c.ProductCategoryKey=1 --4.29 od 1497 oh 783 c 155
set statistics io off

导入三张表:
select * into Customer from AdventureWorks2014.Sales.Customer
select * into OrderHeader from AdventureWorks2014.Sales.SalesOrderHeader
select * into OrderDetail from AdventureWorks2014.Sales.SalesOrderDetail
实现一些业务:
set statistics io on
select c.CustomerID,SUM(od.LineTotal) from OrderDetail as od inner join
orderheader as oh on od.SalesOrderID=oh.SalesOrderID inner join customer as c
on oh.CustomerID =c.CustomerID group by(c.CustomerID) --4.29
set statistics io off

优化的第一步:
1.查看sql语句写法是否有问题(进行改造)
set statistics io on
select oh.CustomerID,sum(od.LineTotal) from OrderDetail as od inner join
OrderHeader as oh on od.SalesOrderID=oh.SalesOrderID group by(oh.CustomerID) --3.77 od 1497 oh 783
set statistics io off

创建索引:
create nonclustered index nc_OrderDetail_SalesOrderID on OrderDetail(SalesOrderID) include
(linetotal)
创建另外一个索引:针对group by 的列
create nonclustered index nc_OrderHeader_CustomerID on OrderHeader(CustomerID)
在次执行上述语句:
set statistics io on
select oh.CustomerID,sum(od.LineTotal) from OrderDetail as od inner join
OrderHeader as oh on od.SalesOrderID=oh.SalesOrderID group by(oh.CustomerID) --3.10 od 533 oh 783
set statistics io off

采用索引视图的方式:
create view v_Order_Total
as
select oh.CustomerID,sum(od.LineTotal) as 总额 from OrderDetail as od inner join
OrderHeader as oh on od.SalesOrderID=oh.SalesOrderID group by(oh.CustomerID)
效果差不多:
set statistics io on
select * from v_Order_Total --3.10 od 533 oh 783
set statistics io off

修改:
alter view v_Order_Total
as
select oh.CustomerID as 客户ID, sum(od.LineTotal) as 总额 from OrderDetail as od inner join
OrderHeader as oh on od.SalesOrderID=oh.SalesOrderID group by(oh.CustomerID)
对唯一列做聚集索引:
create clustered index c_vordertotal_customerid on v_order_total(客户ID)
直接运行报错:

解决方案:
在次执行:
alter view v_Order_Total
with schemabinding
as
select oh.CustomerID as 客户ID, sum(od.LineTotal) as 总额 from OrderDetail as od inner join
OrderHeader as oh on od.SalesOrderID=oh.SalesOrderID group by(oh.CustomerID)
报错:

解决方法:
alter view v_Order_Total
with schemabinding
as
select oh.CustomerID as 客户ID, sum(od.LineTotal) as 总额 from dbo.OrderDetail as od inner join
dbo.OrderHeader as oh on od.SalesOrderID=oh.SalesOrderID group by(oh.CustomerID)
在次创建:
create clustered index c_vordertotal_customerid on v_order_total(客户ID)
报错:

办法:
create unique clustered index c_vordertotal_customerid on v_order_total(客户ID)
报错:

方法:
alter view v_Order_Total
with schemabinding
as
select oh.CustomerID as 客户ID, sum(od.LineTotal) as 总额,COUNT_BIG(*) as 计数 from dbo.OrderDetail as od inner join
dbo.OrderHeader as oh on od.SalesOrderID=oh.SalesOrderID group by(oh.CustomerID)
执行创建索引:
create unique clustered index c_vordertotal_customerid on v_order_total(客户ID)
成功
set statistics io on
select * from v_Order_Total --0.09 io:92
set statistics io off
执行计划:
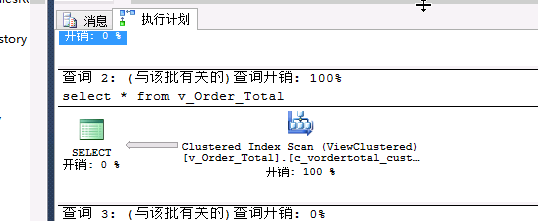

会自动进行值的更新,不用关心
对语句的访问会用到刚才的架构:
set statistics io on
select oh.CustomerID,sum(od.LineTotal) from OrderDetail as od inner join
OrderHeader as oh on od.SalesOrderID=oh.SalesOrderID group by(oh.CustomerID) --0.09 io:92
set statistics io off
SqlServer性能优化索引(五)的更多相关文章
- 03.SQLServer性能优化之---存储优化系列
汇总篇:http://www.cnblogs.com/dunitian/p/4822808.html#tsql 概 述:http://www.cnblogs.com/dunitian/p/60413 ...
- PLSQL_性能优化索引Index介绍(概念)
2014-06-01 BaoXinjian
- 01.SQLServer性能优化之----强大的文件组----分盘存储
汇总篇:http://www.cnblogs.com/dunitian/p/4822808.html#tsql 文章内容皆自己的理解,如有不足之处欢迎指正~谢谢 前天有学弟问逆天:“逆天,有没有一种方 ...
- 02.SQLServer性能优化之---牛逼的OSQL----大数据导入
汇总篇:http://www.cnblogs.com/dunitian/p/4822808.html#tsql 上一篇:01.SQLServer性能优化之----强大的文件组----分盘存储 http ...
- SQLServer性能优化专题
SQLServer性能优化专题 01.SQLServer性能优化之----强大的文件组----分盘存储(水平分库) http://www.cnblogs.com/dunitian/p/5276431. ...
- SQLServer性能优化之---数据库级日记监控
上节回顾:https://www.cnblogs.com/dotnetcrazy/p/11029323.html 4.6.6.SQLServer监控 脚本示意:https://github.com/l ...
- JAVA性能优化的五种方式
一,JAVA性能优化之设计优化 设计优化处于性能优化手段的上层.它往往须要在软件开发之前进行.在软件开发之前,系统架构师应该就评估系统可能存在的各种潜在问题和技术难点,并给出合理的设计方案,因为软件设 ...
- SqlServer性能优化(一)
一:数据存储的方式: 1.数据文件:.mdf或.ndf 2.日志文件:.ldf 二:事务日志的工作步骤: 1.数据修改由应用程序发出(在缓冲区进行缓存) 2.数据页位于缓存区缓冲中,或者读入缓冲区缓存 ...
- SqlServer性能优化 查询和索引优化(十二)
查询优化的过程: 查询优化: 功能:分析语句后最终生成执行计划 分析:获取操作语句参数 索引选择 Join算法选择 创建测试的表: select * into EmployeeOp from Adve ...
随机推荐
- (转)再不用担心DataRow类型转换和空值了(使用扩展方法解决高频问题)
再不用担心DataRow类型转换和空值了(使用扩展方法解决高频问题) XML文档操作集锦(C#篇) webapi文档描述-swagger
- PHP浮点数计算
涉及到计算 和金额交易 使用bc系列函数 高精度计算 不会有0.57不精确的问题
- ios中属性和对象的初始化
属性和对象的初始化为了方便记忆, 我们可以都使用self.来初始化. 这样可以避免内存的过度释放.
- 尺寸不固定的图片在div中垂直居中并完全显示
前几天做一个项目,需要批量上传图片,图片外侧div尺寸固定:由于图片是用户输入的,所以大小存在不确定性,产品需求是无论图片尺寸多大,都要垂直居中完全显示 废话不多说,直接上代码 html <ul ...
- DataTable数据导出CSV文件
public static void SaveAsExcel(DataTable dt1) { //System.Windows.Forms.SaveFileDialog sfd = new Syst ...
- javascript 手势缩放 旋转 拖动支持:hammer.js
原文: https://cdn.rawgit.com/hammerjs/hammer.js/master/tests/manual/visual.html /*! Hammer.JS - v2.0.4 ...
- jQuery LigerUI V1.2.3 (包括API和全部源码) 发布
前言 这次版本主要是增加了Panel和Portal组件,并增加了一套皮肤,并解决了部分兼容性的问题,添加了几个功能点. 欢迎使用反馈. 相关链接 API: http://api.lig ...
- OC基础--Xcode 模板修改和文档安装
修改项目模板 项目模板就是创建工程的时候选择的某一个条目, Xcode会根据选择的条目生成固定格式的项目 如何修改项目模板 找到Xcode, 右键"显示包内容" 打开"/ ...
- apache中虚拟主机的配置
一.两种方式:基于域名的虚拟主机和基于IP地址的的虚拟主机 (这里基于前者) 二.作用:实现在同一个web服务器下,同时运行很多个站点(项目) 三.虚拟主机的配置 1.在核心配置文件中加载虚拟主机配置 ...
- PDO创建mysql数据库并指定utf8编码
<?php //PDO创建mysql数据库并指定utf8编码 header('Content-type:text/html; charset=utf-8'); $servername = &qu ...