Elasticsearch 之 数据索引
对于提供全文检索的工具来说,索引时一个关键的过程——只有通过索引操作,才能对数据进行分析存储、创建倒排索引,从而让使用者查询到相关的信息。
本篇就ES的数据索引操作相关的内容展开:
更多内容参考:Elasticsearch资料汇总
索引操作
最简单的用法就是指定索引操作的index索引、type类型、ID(需要区分动词的索引和名次的索引),参考下面的例子:
$ curl -XPUT 'http://localhost:9200/twitter/tweet/1' -d '{
"user" : "kimchy",
"post_date" : "2009-11-15T14:12:12",
"message" : "trying out Elasticsearch"
}'
这样就在索引twitter中的tweet类型中存储了id为1的数据。
索引操作的结果为:
{
"_shards" : {
"total" : ,
"failed" : ,
"successful" :
},
"_index" : "twitter",
"_type" : "tweet",
"_id" : "",
"_version" : ,
"created" : true
}
上面的_shards中描述了分片相关的信息,即当前一共有10个分片(5个主分片,5个副分片,并且均可用);以及index、type、id、version相关的信息。
自动创建索引
如果上面执行操作前,ES中没有twitter这个索引,那么默认会直接创建这个索引;并且type字段也会自动创建。也就是说,ES并不需要像传统的数据库事先定义表的结构。
每个索引中的类型都有一个mapping映射,这个映射是动态生成的,因此当增加新的字段时,会自动增加mapping的设置。
通过在配置文件中设置action.auto_create_index为false,可以关闭自动创建index这个功能。
自动创建索引功能,也可以设置黑名单或者白名单,比如:
设置action.auto_create_index为 +aaa*,-bbb*,'+'号意味着允许创建aaa开头的索引,'-'号意味着不允许创建bbb开头的索引。
关于版本号
版本号维护了一个文档的状态,我们只会针对最高版本号的文档进行操作。
文档号不仅可以在文档中进行存储,也可以在外部维护版本号,具体的参考官方文档吧....
操作类型op_type
ES通过参数op_type提供“缺少即加入”的功能,即如果ES中没有该文档,就进行索引;如果有了,则报错返回。
如果已经存在id为1的文档,则会报错,直接使用_create API,效果一样:
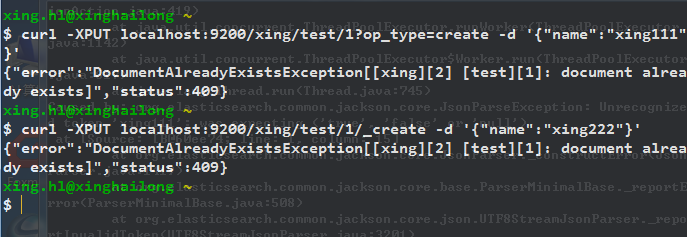
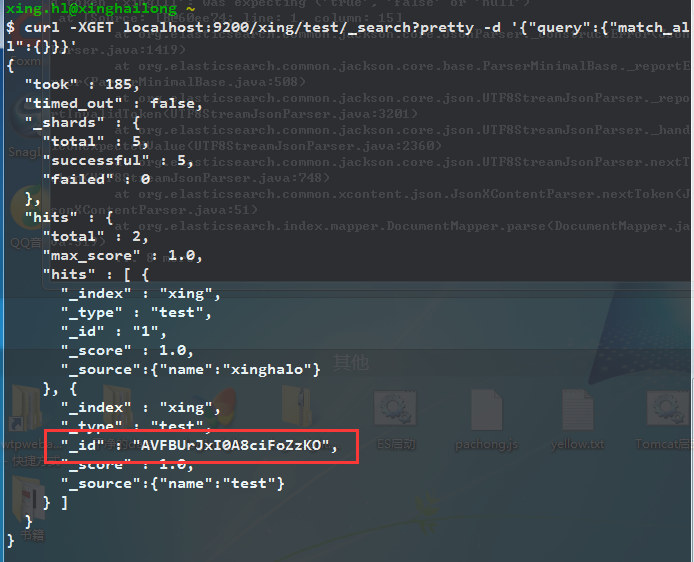
自动创建ID:
按照最上面的例子来说,ES会把我们指定的文档id做为ID。如果不指定ID,那么就会随机分配一个:

路由routing
ES是通过路由来进行查询的,一般一个查询会经过下面的过程:
1 节点接收请求,广播给每个分片
2 分片接收请求,进行计算,返回结果
3 合并消息,返回
如果我们设置了路由信息,就相当于告诉了ES,该去哪个分片查询数据,也就取消了广播合并这个过程,从而提高了查询的效率。使用方法:
$ curl -XPOST 'http://localhost:9200/twitter/tweet?routing=kimchy' -d '{
"user" : "kimchy",
"post_date" : "2009-11-15T14:12:12",
"message" : "trying out Elasticsearch"
}'
路由是通过哈希来实现的,如果我们在索引的时候直接指定routing的值,就会按照这个值计算哈希值,分配分片;如果不指定,就会根据ID来分配。由于一般情况下ID都是随机生成的,这样就可以保证默认情况下分片的数据负载是相同的。如果我们需要在特定的分片保存特定的内容,就可以使用路由指定分片。不过这样做,日后随着数据量的增加,也可能会导致某个分片压力过大。
另外,也可以在定义mapping的时候,直接设置routing的相关值。这样这个类型中的数据如果不指定routing的值,默认就会使用mapping中定义的那个路由值。
parent设置父子关系
ES中可能会涉及到一些文档的从属关系,使用parent参数,可以设置这种关系:
$ curl -XPUT localhost:/blogs/blog_tag/?parent= -d '{
"tag" : "something"
}'
_timestamp设置时间戳
时间戳字段可以也可以在索引操作时指定:
$ curl -XPUT localhost:/twitter/tweet/?timestamp=--15T14%3A12%3A12 -d '{
"user" : "kimchy",
"message" : "trying out Elasticsearch"
}'
如果没有手动指定时间戳,_source中也不存在时间戳,就会设置为索引指定的时间。不过需要指定mapping中的_timestamp设置为enable
PUT my_index
{
"mappings": {
"my_type": {
"_timestamp": {
"enabled": true
}
}
}
}
ttl文档过期
ES中也可以设置文档自动过期,过期是设置一个正的时间间隔,然后以_timestamp为基准,如果超时,就会自动删除。
如果设置为时间戳:
curl -XPUT 'http://localhost:9200/twitter/tweet/1?ttl=86400000' -d '{
"user": "kimchy",
"message": "Trying out elasticsearch, so far so good?"
}'
如果设置为日期数学表达式:
curl -XPUT 'http://localhost:9200/twitter/tweet/1?ttl=1d' -d '{
"user": "kimchy",
"message": "Trying out elasticsearch, so far so good?"
}'
也可以在JSON字段中指定:
curl -XPUT 'http://localhost:9200/twitter/tweet/1' -d '{
"_ttl": "1d",
"user": "kimchy",
"message": "Trying out elasticsearch, so far so good?"
}'
手动刷新
由于ES并不是一个实时索引搜索的框架,因此数据在索引操作后,需要等1秒钟才能搜索到。这里的搜索是指进行检索操作。如果你使用的是get这种API,就是真正的实时操作了。他们之间的不同是,检索可能还需要进行分析和计算分值相关性排序等操作。
为了在数据索引操作后,马上就能搜索到,也可以手动执行refresh操作。只要在API后面添加refresh=true即可。
这种操作仅推荐在特殊情况下使用,如果在大量所以操作中,每个操作都执行refresh,那是很耗费性能的。
Timeout超时
分片并不是随时可用的,当分片进行备份等操作时,是不能进行索引操作的。因此需要等待分片可用后,再进行操作。这时,就会出现一定的等待时间,如果超过等地时间则返回并抛出错误,这个等待时间可以通过timeout设置:
$ curl -XPUT 'http://localhost:9200/twitter/tweet/1?timeout=5m' -d '{
"user" : "kimchy",
"post_date" : "2009-11-15T14:12:12",
"message" : "trying out Elasticsearch"
}'
以上便是索引操作相关的知识,还有一些高级的知识,比如分片和版本号详细的用法,由于对ES还是理解的不够透彻,就先不做过多的讲述了,免得错误太多。
如有异议,还请多多指正。
Elasticsearch 之 数据索引的更多相关文章
- elasticsearch查询篇索引映射文档数据准备
elasticsearch查询篇索引映射文档数据准备 我们后面要讲elasticsearch查询,先来准备下索引,映射以及文档: 我们先用Head插件建立索引film,然后建立映射 POST http ...
- ElasticSearch基础(4)-索引
一.ES API常用规则 ES支持以Http协议的方式提供REST服务,以JSON格式发送请求返回响应. ES提供了大量的不管的数据操作,运维管理API,大量的api 这海量的api有一些通用的功能特 ...
- Elasticsearch 关键字:索引,类型,字段,索引状态,mapping,文档
1. 索引(_index)索引:说的就是数据库的名字.我这个说法是对应到咱经常使用的数据库. 结合es的插件 head 来看. 可以看到,我这个地方,就有这么几个索引,索引就是数据库,后面是这个数据库 ...
- Logstash中如何处理到ElasticSearch的数据映射
Logstash作为一个数据处理管道,提供了丰富的插件,能够从不同数据源获取用户数据,进行处理后发送给各种各样的后台.这中间,最关键的就是要对数据的类型就行定义或映射. 本文讨论的 ELK 版本为 5 ...
- 使用ES-Hadoop 6.5.4编写MR将数据索引到ES
目录 1. 开发环境 2. 下载地址 3. 使用示例 4. 参考文献 1. 开发环境 Elasticsearch 6.5.4 ES-Hadoop 6.5.4 Hadoop 2.0.0 2. 下载地址 ...
- Elasticsearch 搜索数据
章节 Elasticsearch 基本概念 Elasticsearch 安装 Elasticsearch 使用集群 Elasticsearch 健康检查 Elasticsearch 列出索引 Elas ...
- Elasticsearch 修改数据
章节 Elasticsearch 基本概念 Elasticsearch 安装 Elasticsearch 使用集群 Elasticsearch 健康检查 Elasticsearch 列出索引 Elas ...
- Elasticsearch写入数据的过程是什么样的?以及是如何快速更新索引数据的?
前言 最近面试过程中遇到问Elasticsearch的问题不少,这次总结一下,然后顺便也了解一下Elasticsearch内部是一个什么样的结构,毕竟总不能就只了解个倒排索引吧.本文标题就是我遇到过的 ...
- Atitit.数据索引 的种类以及原理实现机制 索引常用的存储结构
Atitit.数据索引 的种类以及原理实现机制 索引常用的存储结构 1. 索引的分类1 1.1. 按照存储结构划分btree,hash,bitmap,fulltext1 1.2. 索引的类型 按查找 ...
随机推荐
- 由 s:hidden 引起的文本框内容不能传到 struts的Action中
<s:form id="startForm" name ="startForm" action="/hall/hall_startList.do ...
- innodb 锁分裂继承与迁移
innodb行锁简介 行锁类型 LOCK_S:共享锁 LOCK_X: 排他锁 GAP类型 LOCK_GAP:只锁间隙 LOCK_REC_NO_GAP:只锁记录 LOCK_ORDINARY: 锁记录和记 ...
- objective-c(接口&实现)
objective-c在xcode6下的例子: 定义接口 #import <Foundation/Foundation.h> //基础库,类似C中的stdlib typedef ,type ...
- 依赖倒置原则(Dependency Inversion Principle)
很多软件工程师都多少在处理 "Bad Design"时有一些痛苦的经历.如果发现这些 "Bad Design" 的始作俑者就是我们自己时,那感觉就更糟糕了.那么 ...
- 实战-Fluxion与wifi热点伪造、钓鱼、中间人攻击、wifi破解
原作者:PG 整理:玄魂工作室-荣杰 目录: 0x00-Fluxion是什么 0x01-Fluxion工作原理 0x02-Kali上安装fluxion 0x03-Fluxion工具使用说明+实 ...
- Word文档合并的一种实现
今天遇到一个问题,就是需要把多个Word文档的内容追加到一个目标Word文档的后面,如果我有目标文档a.doc以及其他很多个文档b.doc,c.doc…等等数量很多.这个问题,如果是在服务端的话,直接 ...
- html表格相关
<html> <head> <style type="text/css"> thead {color:green} tbody {color:b ...
- java中的Static class
Java中的类可以是static吗?答案是可以.在java中我们可以有静态实例变量.静态方法.静态块.类也可以是静态的. java允许我们在一个类里面定义静态类.比如内部类(nested class) ...
- 欢迎访问我的快站fbengine.kuaizhan.com
欢迎访问我的快站 fbengine.kuaizhan.com
- [ZigBee] 10、ZigBee之睡眠定时器
0.概述 睡眠定时器用于设置系统进入和退出低功耗睡眠模式之间的周期.睡眠定时器还用于当进入低功耗睡眠模式时,维持定时器2 的定时. 睡眠定时器的主要功能如下: ● 24 位的定时器正计数器,运行在32 ...