(数据科学学习手札67)使用Git管理Github仓库
一、简介
Git是目前使用最广泛的分布式版本控制系统,通过Git可以方便高效地管理掌握工作过程中项目内容文件的更新变化情况,通过Git我们可以以命令行的形式完成对Github上开源仓库的clone,以及对自己仓库的管理,本文就将针对使用Git管理Github远程仓库的基本方法进行介绍。
二、通过Git向远程仓库推送内容
2.1 准备工作
首先我们通过自己的Github账号创建一个新的远程仓库,名字随便起,这里为demo:
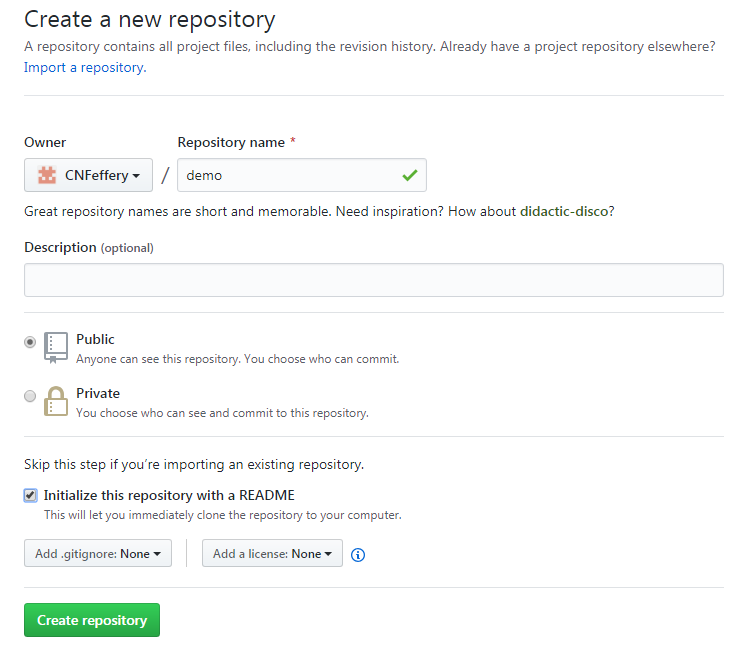
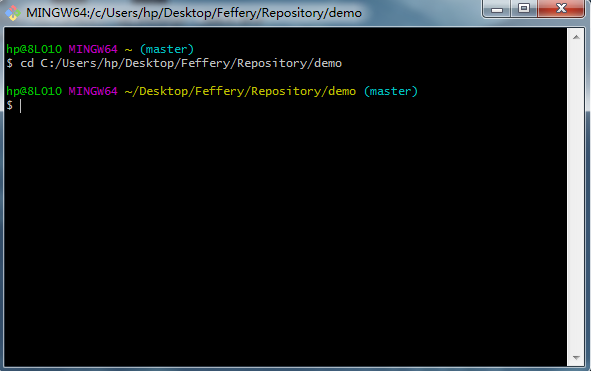
接着我们在本地指定位置创建文件夹作为仓库的根目录,如这里的我们叫demo,打开Git Bash,cd到仓库根目录:
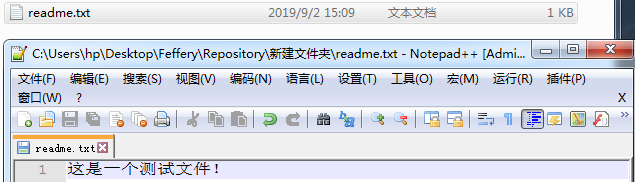
我们在demo目录下随便创建一个新的文件readme.txt,在里面随意写一些内容,注意windows下不要使用记事本编辑仓库下的txt文件,可以在notepad++ utf-8 without dom模式下来编辑保存txt文件:
接下来我们使用git init命令来初始化这个仓库:

使用git status命令查看仓库状态:
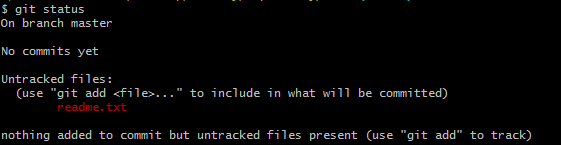
可以看到仓库成功初始化,并且我们当前的目录处于master分支下
2.2 提交文件至暂存区
2.1的最后我们使用git status命令后输出的结果中readme.txt是红色的代表该文件未被提交,使用git add 文件名命令来添加当前路径下的指定文件,单个文件时文件名即要添加的文件,多个文件可以用空格分隔多个文件名,输入.则代表当前目录下所有文件,下面我们将当前目录下全部文件添加到暂存区:

没有内容打印出来则代表添加成功,接着使用git commit -m "说明内容"来将当前暂存区内的文件提交到本地仓库,说明内容部分用于添加方便之后查看的描述内容:

使用git log可以查看提交日志:

这样我们就完成了对本地仓库的一次提交。
2.3 推送至远程仓库
接下来我们将本地仓库内容推送至Github上托管的远程仓库,首先需要在Github上添加公钥,在本地Git执行命令ssh-keygen -t rsa -C "GitHub账号",引号内填入你的Github用户名称,执行之后一路按enter直到执行结束(部分内容我已作打码处理):

找到公钥地址,即上图中红框内的部分,将其复制下来作为公钥地址,再在Git中执行cat 公钥地址,这样粘贴板中就已有了我们需要的公钥,在Github的Settings内找到以下内容:
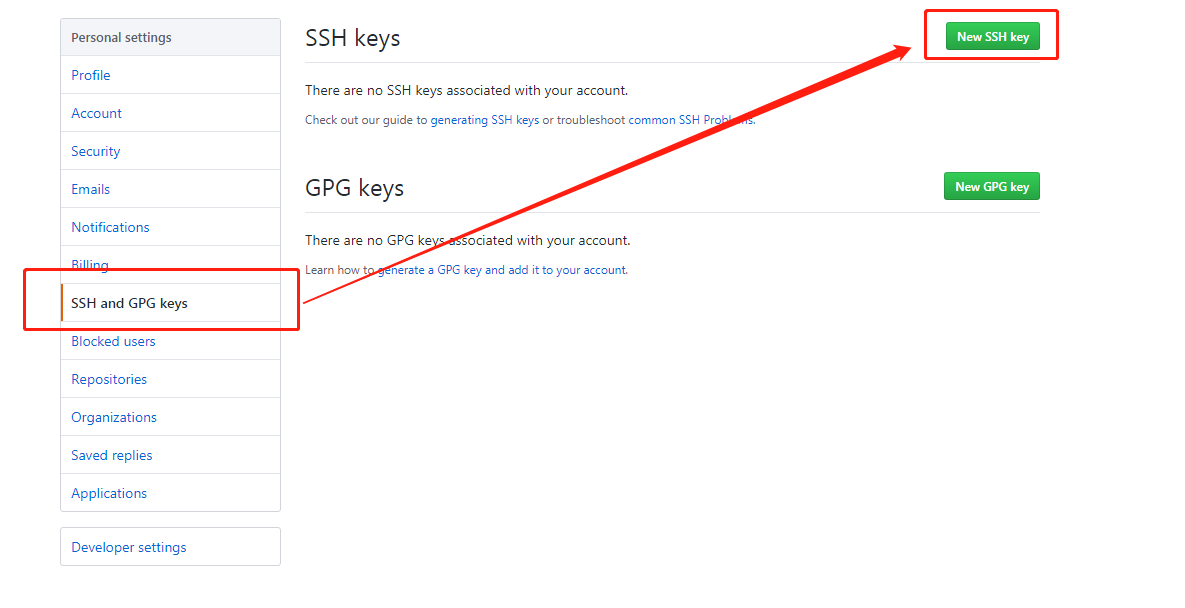
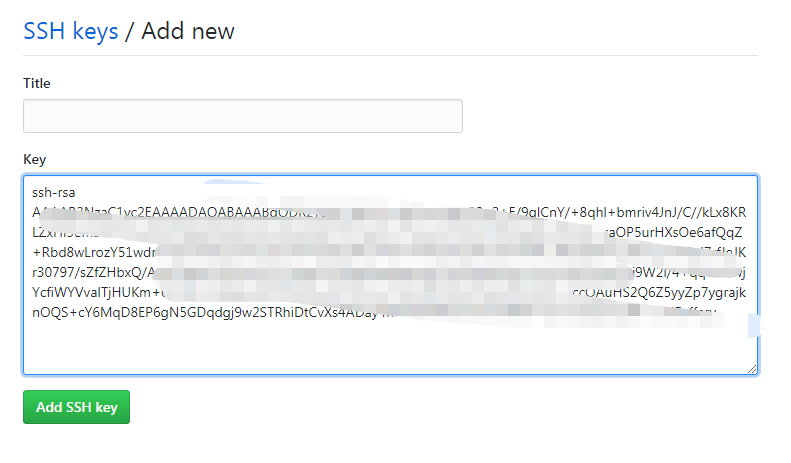
点击New SSH key添加公钥,这里title非必须不用管:
添加成功之后,到Github对应远程仓库主页复制下图红框内的信息:
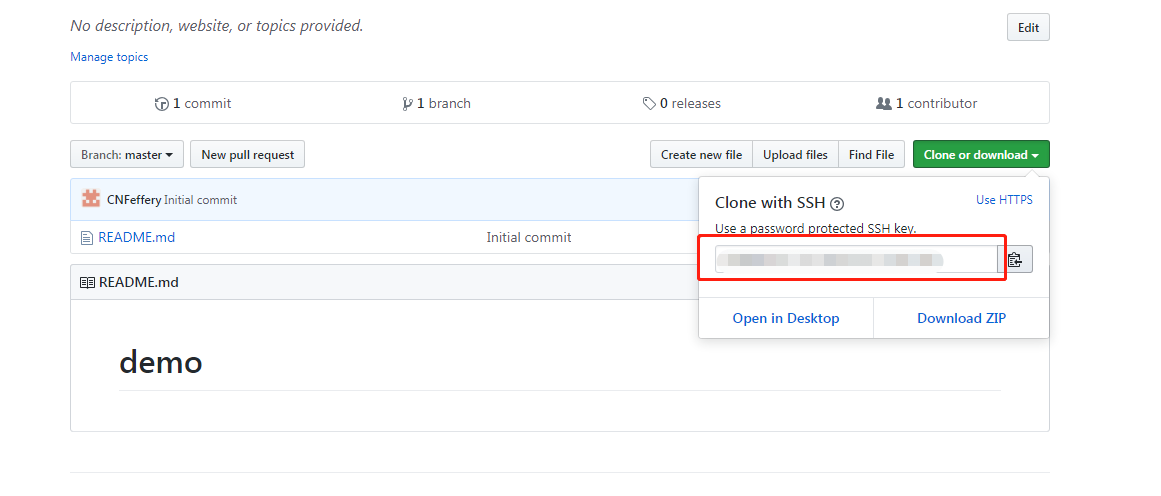
在Git中执行git remote add origin 从Github复制到的信息:

没有内容表示关联远程仓库成功,接下来执行命令git push -f -u origin master便可完成本地仓库向远程仓库的推送:
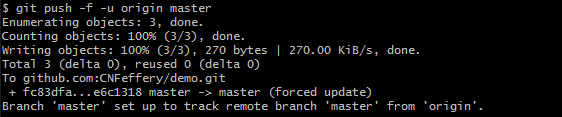
这时查看Github上的远程仓库可以看到对应的文件已经成功的被推送至远程仓库:

这时如果想要提交新的文件只需要参照下面的操作即可:
touch README.md
git add README.md
git commit -m "这是第二次提交"
git push -f -u origin master
对应的便出现了新推送的内容:

三、通过Git删除远程仓库中的内容
通过Git删除远程仓库中的内容则比较方便,譬如这里我们将最后一次添加的md文件删除,首先执行git rm --cached README.md,

接着向本地仓库提交本次操作:

最后向远程仓库推送本次操作:
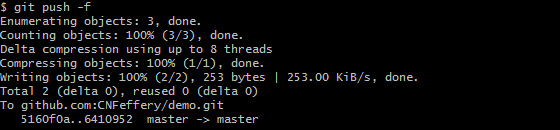
这时再查看远程仓库中的内容,可以发现操作已同步:
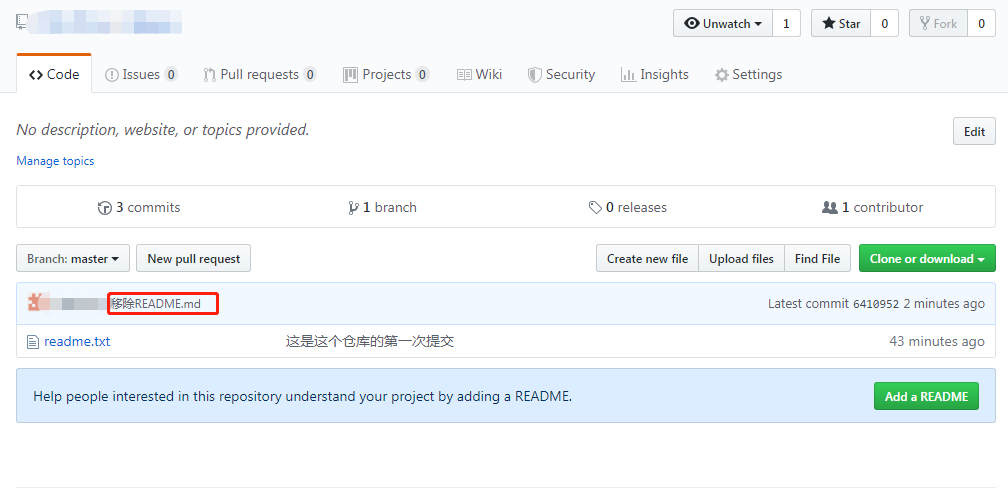
以上就是本文的全部内容,如有笔误望指出!
(数据科学学习手札67)使用Git管理Github仓库的更多相关文章
- (数据科学学习手札75)基于geopandas的空间数据分析——坐标参考系篇
本文对应代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 在上一篇文章中我们对geopandas中的数据结 ...
- (数据科学学习手札55)利用ggthemr来美化ggplot2图像
一.简介 R中的ggplot2是一个非常强大灵活的数据可视化包,熟悉其绘图规则后便可以自由地生成各种可视化图像,但其默认的色彩和样式在很多时候难免有些过于朴素,本文将要介绍的ggthemr包专门针对原 ...
- (数据科学学习手札50)基于Python的网络数据采集-selenium篇(上)
一.简介 接着几个月之前的(数据科学学习手札31)基于Python的网络数据采集(初级篇),在那篇文章中,我们介绍了关于网络爬虫的基础知识(基本的请求库,基本的解析库,CSS,正则表达式等),在那篇文 ...
- (数据科学学习手札49)Scala中的模式匹配
一.简介 Scala中的模式匹配类似Java中的switch语句,且更加稳健,本文就将针对Scala中模式匹配的一些基本实例进行介绍: 二.Scala中的模式匹配 2.1 基本格式 Scala中模式匹 ...
- (数据科学学习手札47)基于Python的网络数据采集实战(2)
一.简介 马上大四了,最近在暑期实习,在数据挖掘的主业之外,也帮助同事做了很多网络数据采集的内容,接下来的数篇文章就将一一罗列出来,来续写几个月前开的这个网络数据采集实战的坑. 二.马蜂窝评论数据采集 ...
- (数据科学学习手札44)在Keras中训练多层感知机
一.简介 Keras是有着自主的一套前端控制语法,后端基于tensorflow和theano的深度学习框架,因为其搭建神经网络简单快捷明了的语法风格,可以帮助使用者更快捷的搭建自己的神经网络,堪称深度 ...
- (数据科学学习手札42)folium进阶内容介绍
一.简介 在上一篇(数据科学学习手札41)中我们了解了folium的基础内容,实际上folium在地理信息可视化上的真正过人之处在于其绘制图像的高度可定制化上,本文就将基于folium官方文档中的一些 ...
- (数据科学学习手札40)tensorflow实现LSTM时间序列预测
一.简介 上一篇中我们较为详细地铺垫了关于RNN及其变种LSTM的一些基本知识,也提到了LSTM在时间序列预测上优越的性能,本篇就将对如何利用tensorflow,在实际时间序列预测任务中搭建模型来完 ...
- (数据科学学习手札36)tensorflow实现MLP
一.简介 我们在前面的数据科学学习手札34中也介绍过,作为最典型的神经网络,多层感知机(MLP)结构简单且规则,并且在隐层设计的足够完善时,可以拟合任意连续函数,而除了利用前面介绍的sklearn.n ...
随机推荐
- perspective transform透视矩阵快速求法+矩形矫正
算了半天一直在思考如何快速把矩阵算出来,网上基本都是在说边长为1的正方形的变换方式=.= 不怎么用得上…… 公式推导推半天,计算还麻烦.... ++++++++++++++++++++++++++ ...
- 【iOS】设备系统版本
判断 iOS 系统的版本号,示例代码如下: NSLog(@"version--%d", [[[UIDevice currentDevice] systemVersion] floa ...
- Mac环境下升级gcc版本--rocksdb
前言 在mac环境下编译rocksdb,需要配置依赖的编译环境,其中有一项比较麻烦:c++编译要支持C++11,但是在mac环境安装xcode-select --install之后,已经安装有了gcc ...
- ASP.NET Core Web API 跨域(CORS) Cookie问题
身为一个Web API,处理来自跨域不同源的请求,是一件十分合理的事情. 先上已有的文章,快速复制粘贴,启用CORS: Microsoft:启用 ASP.NET Core 中的跨域请求 (CORS) ...
- Altium Designer16绘制51单片机的一些经验总结
制作这块51单片机的还是蛮艰辛的,应该是我水平太差,现在这块51板已经稳定了,也把这块板子制作过程中的一些问题及经验总结记录下来.这块板子制作出了很大问题很大原因是因为我对Altium Designe ...
- 佳木斯集训Day5
今天是ACM赛制...本来可以400的,结果毒瘤T2模拟硬生生卡掉了我90分 T1是个大水题,找规律,5分钟AC没啥压力 #include <bits/stdc++.h> #define ...
- 佳木斯集训Day4
Day4的出题人好毒瘤啊!!! T1我打表过的,正解现在也不会 #include <bits/stdc++.h> #define MAXN 10050 #define ll long lo ...
- java支付宝app支付-代码实现
1.我们需要在支付宝商户平台配置好,取到四个参数如下(这是支付宝官方配置地址):https://www.cnblogs.com/fuzongle/p/10217144.html 合作身份者ID:123 ...
- 科普向 + 折腾向 ——你了解磁盘、分区、文件系统、GPT、UEFI吗?在笔记本上安装五个系统是怎样的体验?
[Windows 7 + Windows 8 (PE) + Windows 10 + deepin-Linux + MacOS X] 前言:随着软硬件技术的发展UEFI引导逐渐取代传统BIOS引导,最 ...
- Salesforce LWC学习(四) 父子component交互 / component声明周期管理 / 事件处理
我们在上篇介绍了 @track / @api的区别.在父子 component中,针对api类型的变量,如果声明以后就只允许在parent修改,son component修改便会导致报错. sonIt ...