(读论文)推荐系统之ctr预估-NFM模型解析
本系列的第六篇,一起读论文~
本人才疏学浅,不足之处欢迎大家指出和交流。
今天要分享的是另一个Deep模型NFM(串行结构)。NFM也是用FM+DNN来对问题建模的,相比于之前提到的Wide&Deep(Google)、DeepFM(华为+哈工大)、PNN(上交)和之后会分享的的DCN(Google)、DIN(阿里)等,NFM有什么优点呢,下面就走进模型我们一起来看看吧。
原文:Neural Factorization Machines for Sparse Predictive Analytics
地址:https://arxiv.org/pdf/1708.05027.pdf
1、问题由来
老生常谈,再聊数据特点:对于广告中的大量的类别特征,特征组合也是非常多的。传统的做法是通过人工特征工程或者利用决策树来进行特征选择,选择出比较重要的特征。但是这样的做法都有一个缺点,就是:无法学习训练集中没有出现的特征组合。
最近几年,Embedding-based方法开始成为主流,通过把高维稀疏的输入_embed_到低维度的稠密的隐向量空间中,模型可以学习到训练集中没有出现过的特征组合。
Embedding-based大致可以分为两类:
1.factorization machine-based linear models
2.neural network-based non-linear models
(具体就不再展开了)
* * *
FM:以线性的方式学习二阶特征交互,对于捕获现实数据非线性和复杂的内在结构表达力不够;
深度网络:例如Wide&Deep 和DeepCross,简单地拼接特征embedding向量不会考虑任何的特征之间的交互, 但是能够学习特征交互的非线性层的深层网络结构又很难训练优化;
而NFM摒弃了直接把嵌入向量拼接输入到神经网络的做法,在嵌入层之后增加了_Bi-Interaction_操作来对二阶组合特征进行建模。这使得low level的输入表达的信息更加的丰富,极大的提高了后面隐藏层学习高阶非线性组合特征的能力。
2、NFM
2.1 NFM Model
与FM(因式分解机)相似,NFM使用实值特征向量。给定一个稀疏向量x∈Rn作为输入,其中特征值为xi=0表示第i个特征不存在,NFM预估的目标为:

其中第一项和第二项是线性回归部分,与FM相似,FM模拟数据的全局偏差和特征权重。第三项f(x)是NFM的核心组成部分,用于建模特征交互。它是一个多层前馈神经网络。如图2所示,接下来,我们一层一层地阐述f(x)的设计。
模型整体结构图如下所示:
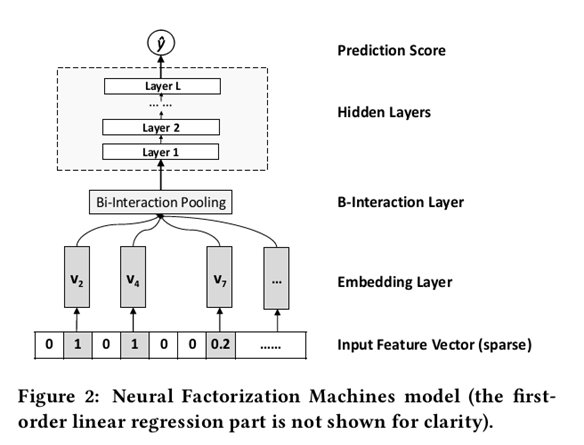
2.1.1 Embedding Layer
和其他的DNN模型处理稀疏输入一样,Embedding将输入转换到低维度的稠密的嵌入空间中进行处理。这里做稍微不同的处理是,使用原始的特征值乘以Embedding vector,使得模型也可以处理real valued feature。
2.1.2 Bi-Interaction Layer
Bi是Bi-linear的缩写,这一层其实是一个pooling层操作,它把很多个向量转换成一个向量,形式化如下:
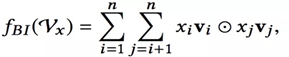
fbi的输入是整个的嵌入向量,xi ,xj是特征取值,vi, vj是特征对应的嵌入向量。中间的操作表示对应位置相乘。所以原始的嵌入向量任意两个都进行组合,对应位置相乘结果得到一个新向量;然后把这些新向量相加,就得到了Bi-Interaction的输出。这个输出只有一个向量。
注:Bi-Interaction并没有引入额外的参数,而且它的计算复杂度也是线性的,参考FM的优化方法,化简如下:

2.1.3 Hidden Layer
这个跟其他的模型基本一样,堆积隐藏层以期来学习高阶组合特征。一般选用constant的效果要好一些。
2.1.4 Prediction Layer
最后一层隐藏层Zl到输出层最后预测结果形式化如下:
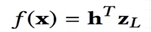
其中h是中间的网络参数。考虑到前面的各层隐藏层权重矩阵,f(x)形式化如下:

这里相比于FM其实多出的参数其实就是隐藏层的参数,所以说FM也可以看做是一个神经网络架构,就是去掉隐藏层的NFM。
2.2 NFM vs Wide&Deep、DeepCross
实质:
NFM最重要的区别就在于Bi-Interaction Layer。Wide&Deep和DeepCross都是用拼接操作(concatenation)替换了Bi-Interaction。
Concatenation操作的最大缺点就是它并没有考虑任何的特征组合信息,所以就全部依赖后面的MLP去学习特征组合,但是很不幸,MLP的学习优化非常困难。
使用Bi-Interaction考虑到了二阶特征组合,使得输入的表示包含更多的信息,减轻了后面MLP部分的学习压力,所以可以用更简单的模型(实验中只一层隐层),取得更好的效果。
3、总结(具体的对比实验和实现细节等请参阅原论文)
NFM主要的特点如下:
1. NFM核心就是在NN中引入了Bilinear Interaction(Bi-Interaction) pooling操作。基于此,NN可以在low level就学习到包含更多信息的组合特征。
2. 通过deepen FM来学习高阶的非线性的组合特征。
3. NFM相比于上面提到的DNN模型,模型结构更浅、更简单(shallower structure),但是性能更好,训练和调整参数更加容易。
所以,依旧是FM+DNN的组合套路,不同之处在于如何处理Embedding向量,这也是各个模型重点关注的地方。现在来看业界就如何用DNN来处理高维稀疏的数据并没有一个统一普适的方法,依旧在摸索中。
实现DeepFM的一个Demo,感兴趣的童鞋可以看下我的github。
(读论文)推荐系统之ctr预估-NFM模型解析的更多相关文章
- (读论文)推荐系统之ctr预估-DeepFM模型解析
今天第二篇(最近更新的都是Deep模型,传统的线性模型会后面找个时间更新的哈).本篇介绍华为的DeepFM模型 (2017年),此模型在 Wide&Deep 的基础上进行改进,成功解决了一些问 ...
- 计算广告之CTR预估-FNN模型解析
原论文:Deep learning over multi-field categorical data 地址:https://arxiv.org/pdf/1601.02376.pdf 一.问题由来 基 ...
- CTR预估经典模型总结
计算广告领域中数据特点: 1 正负样本不平衡 2 大量id类特征,高维,多领域(一个类别型特征就是一个field,比如上面的Weekday.Gender.City这是三个field),稀疏 ...
- 主流CTR预估模型的演化及对比
https://zhuanlan.zhihu.com/p/35465875 学习和预测用户的反馈对于个性化推荐.信息检索和在线广告等领域都有着极其重要的作用.在这些领域,用户的反馈行为包括点击.收藏. ...
- CTR预估的常用方法
1.CTR CTR预估是对每次广告的点击情况做出预测,预测用户是点击还是不点击. CTR预估和很多因素相关,比如历史点击率.广告位置.时间.用户等. CTR预估模型就是综合考虑各种因素.特征,在大量历 ...
- 闲聊DNN CTR预估模型
原文:http://www.52cs.org/?p=1046 闲聊DNN CTR预估模型 Written by b manongb 作者:Kintocai, 北京大学硕士, 现就职于腾讯. 伦敦大学张 ...
- 深度CTR预估模型中的特征自动组合机制演化简史 zz
众所周知,深度学习在计算机视觉.语音识别.自然语言处理等领域最先取得突破并成为主流方法.但是,深度学习为什么是在这些领域而不是其他领域最先成功呢?我想一个原因就是图像.语音.文本数据在空间和时间上具有 ...
- CTR预估模型演变及学习笔记
[说在前面]本人博客新手一枚,象牙塔的老白,职业场的小白.以下内容仅为个人见解,欢迎批评指正,不喜勿喷![握手][握手] [再啰嗦一下]如果你对智能推荐感兴趣,欢迎先浏览我的另一篇随笔:智能推荐算法演 ...
- 微软的一篇ctr预估的论文:Web-Scale Bayesian Click-Through Rate Prediction for Sponsored Search Advertising in Microsoft’s Bing Search Engine。
周末看了一下这篇论文,觉得挺难的,后来想想是ICML的论文,也就明白为什么了. 先简单记录下来,以后会继续添加内容. 主要参考了论文Web-Scale Bayesian Click-Through R ...
随机推荐
- 分布式数据库中间件 MyCat 搞起来!
关于 MyCat 的铺垫文章已经写了三篇了: MySQL 只能做小项目?松哥要说几句公道话! 北冥有 Data,其名为鲲,鲲之大,一个 MySQL 放不下! What?Tomcat 竟然也算中间件? ...
- Spring_One
Spring_01 Spring概述 Spring是分层的Java2E应用full-stack轻量级开源框架,,以IoC(Inverse Of Control:反转控制)和AOP(Aspect Ori ...
- 曹工说Tomcat3:深入理解 Tomcat Digester
一.前言 我写博客主要靠自己实战,理论知识不是很强,要全面介绍Tomcat Digester,还是需要一定的理论功底.翻阅了一些介绍 Digester 的书籍.博客,发现不是很系统,最后发现还是官方文 ...
- 【JVM】01虚拟机内存模型
学习链接:https://blog.csdn.net/u010425776/article/details/51170118 博主整理的条理清晰,在这里先感谢博主分享 去年看视频学习写过一篇JVM的博 ...
- (数据科学学习手札62)详解seaborn中的kdeplot、rugplot、distplot与jointplot
一.简介 seaborn是Python中基于matplotlib的具有更多可视化功能和更优美绘图风格的绘图模块,当我们想要探索单个或一对数据分布上的特征时,可以使用到seaborn中内置的若干函数对数 ...
- Demo小细节
(1) 程序如下: public class Example { static int i = 1, j = 2; static { display(i); i = i + j; } static v ...
- docker命令总结
用 docker pull 拉取镜像 root@lishichao-virtual-machine:~# docker pull hello-world Using default tag: late ...
- zabbix2.4汉化
zabbix的2.4版本安装完后,这里的语言界面选择没有中文,其实是这个版本把中文的屏蔽了. [root@zabbix-server opt]# vim /var/www/html/include/l ...
- easyui close的最大化的dialog 切换 tab 再次出现
今天发现一个神奇的bug,easyui中的dialog在经历了d.panel('close');之后,当前的tab仍然未关闭,切换了另一tab,然后回去刚才的tab,发现已经close的dialog又 ...
- docker-compose一键部署redis一主二从三哨兵模式(含密码,数据持久化)
本篇基于centos7服务器进行部署开发 一.拉取redis镜像,使用如下命令 docker pull redis 1.查看镜像是否拉取成功,使用如下命令 docker images 显示如下则证明拉 ...