Python爬虫基础——re模块的提取和匹配
re是Python的一个第三方库。
为了能更直观的看出re的效果,我们先新建一个HTML网页文件(可直接复制):
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<footer>
<div>
<div class="email">
Email:re@qq.com
</div>
<div class="tel">
手机号:88888888
</div>
</div>
</footer>
</body>
</html>
## OK,然后我们进入主题。
re主要有三个功能:提取、匹配、替换。
1、提取findall:
re.findall(【正则表达式】, 【被提取的字符串】)
注意:返回的类型是列表
我们应如何取出上文index.html中的Email或者手机号呢:
import re
with open('index.html', 'r', encoding='utf-8') as f:
# 读取index.html
html = f.read()
# 把html中的换行符,去掉,也就是替换成空字符串,因为.不能匹配到换行符
html = re.sub('\n', '', html)
print(html)
# 定义正则表达式,注意括号
pattern_1 = '<div class="email">(.*?)</div>'
# re.findall(【正则表达式】,【被提取的字符串】),返回类型是列表
ret_1 = re.findall(pattern_1, html)
# 字符串.strip(),可以去除首位的空格和换行符
print(ret_1[0].strip())
2、匹配match:
re.match(【正则表达式】, 【被匹配的字符串】)
注意:
如果匹配成功,返回<class 're.Match'>对象;
如果匹配不成功,返回None。
我们应如何编写定义密码的正则表达式呢:
import re
# 英文字母开头,可包括应为字母,数字、下划线,总位数6-16位
password_pattern = r'^[a-zA-Z][a-zA-Z0-9_]{5,15}$'
# 定义三个密码
pass1 = '1234567'
pass2 = 'k123456'
pass3 = 'k123'
# 打印测试结果,匹配成功返回re.Match对象,不成功返回None
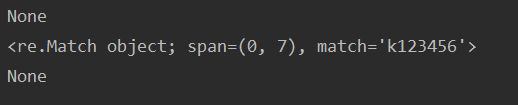
print(re.match(password_pattern, pass1))
print(re.match(password_pattern, pass2))
print(re.match(password_pattern, pass3))
输出结果为:
3、替换sub:
re.sub(【正则表达式】, 【替换成的字符串】, 【被匹配的字符串】)
觉得没看过sub的同学,那只能说明你看笔记不认真了,示范代码请看上上文~~
为我心爱的女孩~~
Python爬虫基础——re模块的提取和匹配的更多相关文章
- Python爬虫基础
前言 Python非常适合用来开发网页爬虫,理由如下: 1.抓取网页本身的接口 相比与其他静态编程语言,如java,c#,c++,python抓取网页文档的接口更简洁:相比其他动态脚本语言,如perl ...
- 孤荷凌寒自学python第六十七天初步了解Python爬虫初识requests模块
孤荷凌寒自学python第六十七天初步了解Python爬虫初识requests模块 (完整学习过程屏幕记录视频地址在文末) 从今天起开始正式学习Python的爬虫. 今天已经初步了解了两个主要的模块: ...
- Python爬虫练习(requests模块)
Python爬虫练习(requests模块) 关注公众号"轻松学编程"了解更多. 一.使用正则表达式解析页面和提取数据 1.爬取动态数据(js格式) 爬取http://fund.e ...
- Python爬虫之urllib模块2
Python爬虫之urllib模块2 本文来自网友投稿 作者:PG-55,一个待毕业待就业的二流大学生. 看了一下上一节的反馈,有些同学认为这个没什么意义,也有的同学觉得太简单,关于Beautiful ...
- Python爬虫之urllib模块1
Python爬虫之urllib模块1 本文来自网友投稿.作者PG,一个待毕业待就业二流大学生.玄魂工作室未对该文章内容做任何改变. 因为本人一直对推理悬疑比较感兴趣,所以这次爬取的网站也是平时看一些悬 ...
- python爬虫-基础入门-python爬虫突破封锁
python爬虫-基础入门-python爬虫突破封锁 >> 相关概念 >> request概念:是从客户端向服务器发出请求,包括用户提交的信息及客户端的一些信息.客户端可通过H ...
- python爬虫-基础入门-爬取整个网站《3》
python爬虫-基础入门-爬取整个网站<3> 描述: 前两章粗略的讲述了python2.python3爬取整个网站,这章节简单的记录一下python2.python3的区别 python ...
- python爬虫-基础入门-爬取整个网站《2》
python爬虫-基础入门-爬取整个网站<2> 描述: 开场白已在<python爬虫-基础入门-爬取整个网站<1>>中描述过了,这里不在描述,只附上 python3 ...
- python爬虫-基础入门-爬取整个网站《1》
python爬虫-基础入门-爬取整个网站<1> 描述: 使用环境:python2.7.15 ,开发工具:pycharm,现爬取一个网站页面(http://www.baidu.com)所有数 ...
随机推荐
- Linux下安装和使用WPS,体验良好
最近,我在ubuntu18.04.3下面使用LibreOffice,感觉良好. 正值政府机关在进行2019年度正版软件使用情况整改,保护知识产权,我表示热烈欢迎并强烈支持. 通过摸底,因为以前采购的w ...
- 优秀的github项目学习
优秀的github项目学习 后期会陆续添加遇到的优秀项目 https://github.com/chaijunkun
- AntDeploy一键发布netcore3.0Windows服务到远程服务器
*:first-child { margin-top: 0 !important; } .markdown-body>*:last-child { margin-bottom: 0 !impor ...
- 01_Numpy基本使用
1.Numpy读取txt/csv文件 读取数据 import numpy as np # numpy打开本地txt文件 world_alcohol = np.genfromtxt("D:\\ ...
- Kotlin实战案例:带你实现RecyclerView分页查询功能(仿照主流电商APP,可切换列表和网格效果)
随着Kotlin的推广,一些国内公司的安卓项目开发,已经从Java完全切成Kotlin了.虽然Kotlin在各类编程语言中的排名比较靠后(据TIOBE发布了 19 年 8 月份的编程语言排行榜,Kot ...
- Lambda入门,看这一篇幅就够了
jdk1.8中的lambda表达式学习笔记 一.引入一个例子 我们写一个多线程的例子,如下:采用实现Runable接口的方式 package cn.lyn4ever.lambda; public cl ...
- Prometheus PromQL 基础
目录 时序 4 种类型 Counter Gauge Histogram Summary Histogram vs Summary 操作符 时序 4 种类型 Prometheus 时序数据分为 Coun ...
- 小白学 Python 爬虫(12):urllib 基础使用(二)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- [ch04-04] 多样本单特征值计算
系列博客,原文在笔者所维护的github上:https://aka.ms/beginnerAI, 点击star加星不要吝啬,星越多笔者越努力. 4.4 多样本单特征值计算 在前面的代码中,我们一直使用 ...
- 挑战10个最难的Java面试题(附答案)【下】【华为云技术分享】
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/devcloud/article/detai ...