Python爬虫基础——XPath语法的学习与lxml模块的使用
XPath与正则都是用于数据的提取,二者的区别是:
- 正则:功能相对强大,写起来相对复杂;
- XPath:语法简单,可以满足绝大部分的需求,但不能爬取注释代码(下一篇会讲到);
所以,如果你可以根据自己的需要进行选择。
一、首先,我们需要为Google浏览器配置XPath插件:
请自行学习,效果如下:

二、XPath的语法:
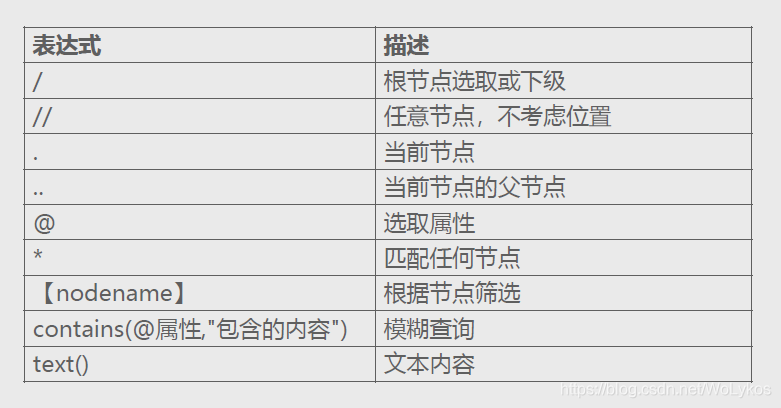
注意:
XPath的索引从1开始。
三、XPath的案例:
一级分类:
//h3[@class="classify_c_h3"]/a/text()

二级分类:
//div[@class="classify_list"]/span/a/text()

模糊查询:
//div[contains(@class,"classify_list")]/span/a/text()

四、lxml模块的使用
import lxml.etree as le
with open('edu.html', 'r', encoding='utf-8') as f:
html = f.read()
# print(html)
# 转换为XPath对象
html_x = le.HTML(html)
# print(html_x)
# 匹配一二级分类的父标签
div_x_s = html_x.xpath('//div[@class="classify_cList"]') # 直接从HTML中取则不用加.
data_s = []
for div_x in div_x_s:
# 一级分类
category1 = div_x.xpath('./h3/a/text()')[0] # 记得加.
# 二级分类
category2_s = div_x.xpath('./div/span/a/text()') # 表示从当前节点进行筛选
data_s.append(
dict(
category1=category1,
category2_s=category2_s
)
)
print(data_s)
for data in data_s:
print(data.get('category1'))
for category2 in data.get('category2_s'):
print(' ', category2)
为我心爱的女孩~~
Python爬虫基础——XPath语法的学习与lxml模块的使用的更多相关文章
- python爬虫:XPath语法和使用示例
python爬虫:XPath语法和使用示例 XPath(XML Path Language)是一门在XML文档中查找信息的语言,可以用来在XML文档中对元素和属性进行遍历. 选取节点 XPath使用路 ...
- Python爬虫之xpath语法及案例使用
Python爬虫之xpath语法及案例使用 ---- 钢铁侠的知识库 2022.08.15 我们在写Python爬虫时,经常需要对网页提取信息,如果用传统正则表达去写会增加很多工作量,此时需要一种对数 ...
- Python爬虫:Xpath语法笔记
一.选取节点 常用的路劲表达式: 表达式 描述 实例 nodename 选取nodename节点的所有子节点 xpath(‘//div’) 选取了div节点的所有子节点 / 从根节点选取 xpat ...
- Python爬虫基础
前言 Python非常适合用来开发网页爬虫,理由如下: 1.抓取网页本身的接口 相比与其他静态编程语言,如java,c#,c++,python抓取网页文档的接口更简洁:相比其他动态脚本语言,如perl ...
- python爬虫-基础入门-爬取整个网站《2》
python爬虫-基础入门-爬取整个网站<2> 描述: 开场白已在<python爬虫-基础入门-爬取整个网站<1>>中描述过了,这里不在描述,只附上 python3 ...
- 非常全的一份Python爬虫的Xpath博文
非常全的一份Python爬虫的Xpath博文 Xpath 是 python 爬虫过程中非常重要的一个用来定位的一种语法. 一.开始使用 首先我们需要得到一个 HTML 源代码,用来模拟爬取网页中的源代 ...
- python爬虫-基础入门-python爬虫突破封锁
python爬虫-基础入门-python爬虫突破封锁 >> 相关概念 >> request概念:是从客户端向服务器发出请求,包括用户提交的信息及客户端的一些信息.客户端可通过H ...
- python爬虫-基础入门-爬取整个网站《3》
python爬虫-基础入门-爬取整个网站<3> 描述: 前两章粗略的讲述了python2.python3爬取整个网站,这章节简单的记录一下python2.python3的区别 python ...
- python爬虫-基础入门-爬取整个网站《1》
python爬虫-基础入门-爬取整个网站<1> 描述: 使用环境:python2.7.15 ,开发工具:pycharm,现爬取一个网站页面(http://www.baidu.com)所有数 ...
随机推荐
- 使用Docker搭建maven私服 及常规使用方法
安装-登录-配置 下载镜像 docker pull sonatype/nexus3 运行 docker run -d -p 9998:8081 --name nexus --restart=alway ...
- 看完这篇还不会用Git,那我就哭了!
你使用过 Git 吗?也许你已经使用了一段时间,但它的许多奥秘仍然令人困惑. Git 是一个版本控制系统,是任何软件开发项目中的主要内容.通常有两个主要用途:代码备份和代码版本控制.你可以逐步处理代码 ...
- 2019-10-16:渗透测试,基础学习,burpsuit学习,爆破的四种方式学习
Burp Suite 是用于攻击web 应用程序的集成平台,包含了许多工具.Burp Suite为这些工具设计了许多接口,以加快攻击应用程序的过程.所有工具都共享一个请求,并能处理对应的HTTP 消息 ...
- 每天复现一个漏洞--vulhub
phpmyadmin scripts/setup.php 反序列化漏洞(WooYun-2016-199433) 漏洞原理:http://www.polaris-lab.com/index.php/ar ...
- Selenium WebDriver 中鼠标事件
鼠标点击操作 鼠标点击事件有以下几种类型: 清单 1. 鼠标左键点击 Actions action = new Actions(driver);action.click();// 鼠标左键在当 ...
- JavaScript算法实现之汉诺塔(Hanoi)
目前前端新手,看到的不喜勿喷,还望大神指教. 随着Node.js,Angular.js,JQuery的流行,点燃了我学习JavaScript的热情!以后打算每天早上跟晚上抽2小时左右时间将经典的算法都 ...
- flask实现验证码并验证
效果图: 点击图片.刷新页面.输入错误点击登录时都刷新验证码 实现步骤: 第一步:先定义获取验证码的接口 verificationCode.py #验证码 @api.route('/imgCode') ...
- 实战webpack系列02
02. 开始使用webpack 1.1.安装 Webpack可以使用npm安装,新建一个空的练习文件夹(此处命名为webpack sample project),在终端中转到该文件夹后执行下述指令就可 ...
- vsftpd架设(配置pam模块)
Vsftpd 是很安全的ftp软件 VSFTPD的目录结构 /usr/sbin/vsftpd: VSFTPD的可执行文件 /etc/rc.d/init.d/vsftpd:启动脚本 /etc/vsftp ...
- 机器学习实战书-第二章K-近邻算法笔记
本章介绍第一个机器学习算法:A-近邻算法,它非常有效而且易于掌握.首先,我们将探讨女-近邻算法的基本理论,以及如何使用距离测量的方法分类物品:其次我们将使用?7««^从文本文件中导人并解析数据: 再次 ...