scrapy爬取迅雷电影天堂最新电影ed2k
前言
几天没用scrapy爬网站了,正好最近在刷电影,就想着把自己常用的一个电影分享网站给爬取下来保存到本地mongodb中
项目开始
第一步仍然是创建scrapy项目与spider文件
切换到工作目录两条命令依次输入
- scrapy startproject xunleidianying
- scrapy genspider xunleiBT https://www.xl720.com/thunder/years/2019
内容分析
打开目标网站(分类是2019年上映的电影),分析我们需要的数据
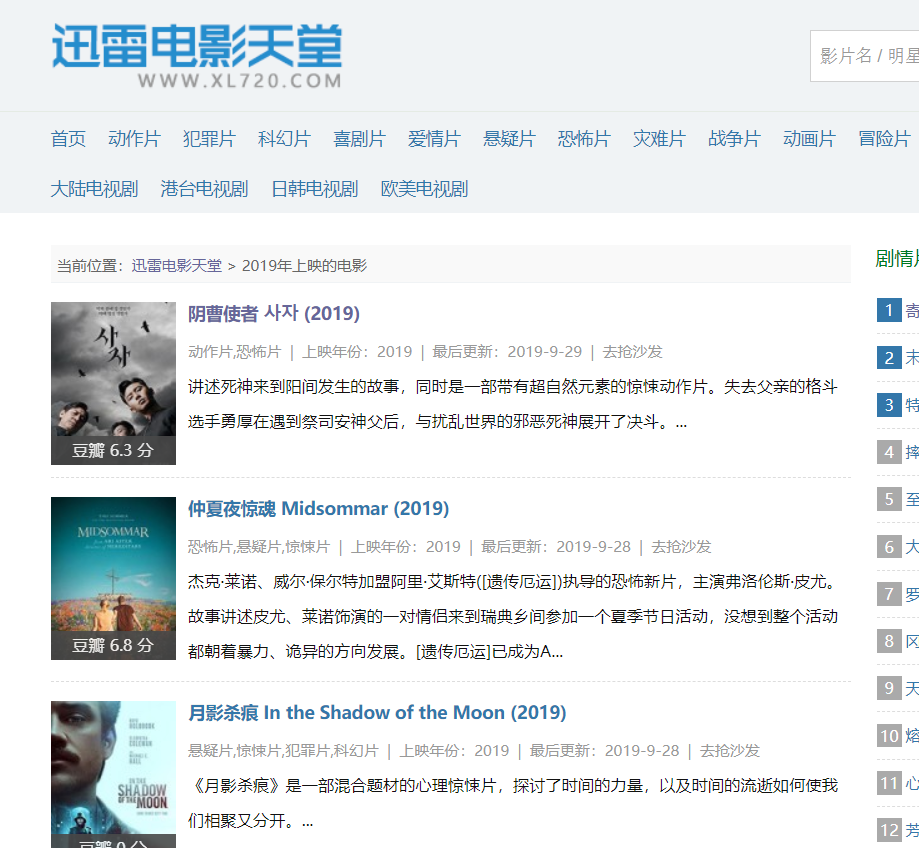
进入页面是列表的形式就像豆瓣电影一样,然后我们点进去具体页面看看
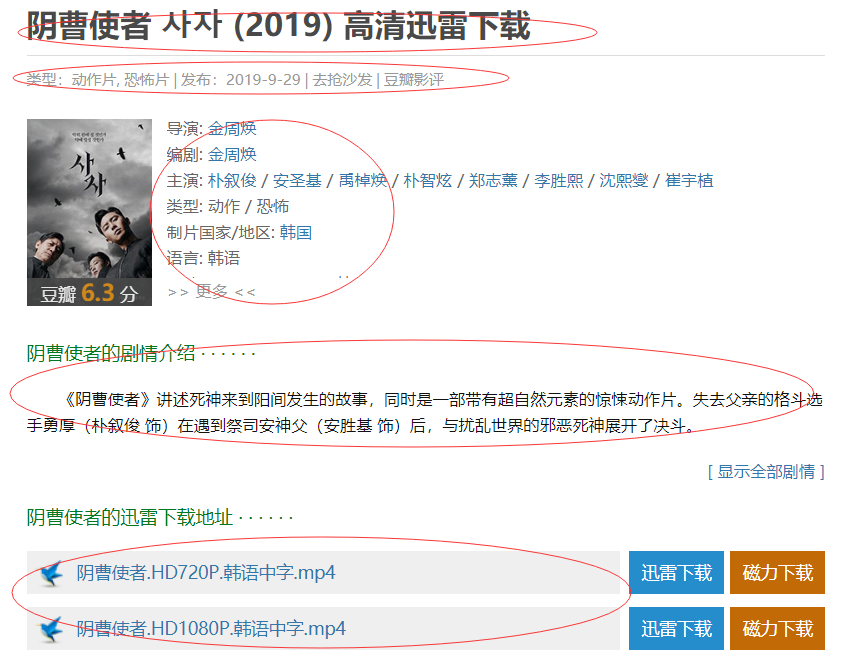
这个页面就是我们需要拿到的内容页面,我们来看我们需要哪些数据(某些数据从第一个页面就可以获得,但是下载地址必须到第二个页面)
- 电影名称
- 电影信息
- 电影内容剧情
- 电影下载地址
分析完成之后就可以首先编写 items.py文件
import scrapy class XunleidianyingItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
information = scrapy.Field()
content = scrapy.Field()
downloadurl = scrapy.Field()
pass
另外别忘了去settings.py中开启 ITEM_PIPELINES 选项
爬虫文件编写
老样子,为了方便测试我们的爬虫,首先编写一个main.py的文件方便IDE调用
main.py:
import scrapy.cmdline
scrapy.cmdline.execute('scrapy crawl xunleiBT'.split())
首先我们先测试直接向目标发送请求是否可以得到响应
爬虫文件 xunleiBT.py编写如下:
# -*- coding: utf-8 -*-
import scrapy class XunleibtSpider(scrapy.Spider):
name = 'xunleiBT'
allowed_domains = ['https://www.xl720.com/thunder/years/2019']
start_urls = ['https://www.xl720.com/thunder/years/2019/'] def parse(self, response):
print(response.text)
pass
运行 main.py 看看会出现什么
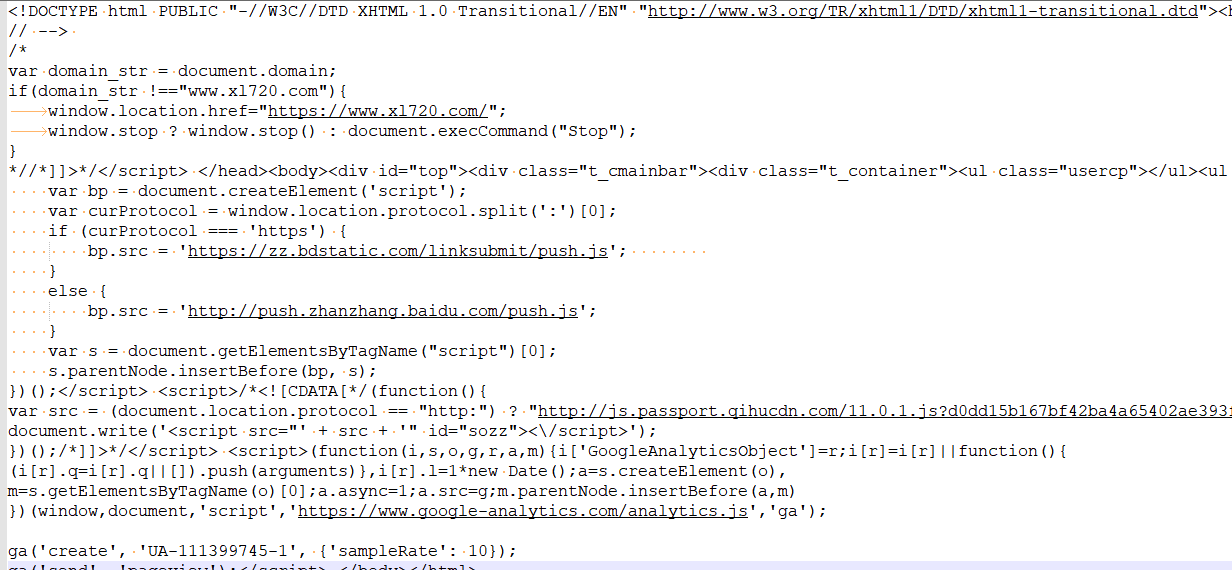
好的,发现直接返回正常的网页也就是我们要的网页,说明该网站没有反爬机制,这样我们就更容易爬取了
然后通过xpath定位页面元素,具体就不再赘述,之前的scarpy教程中都有 继续编写爬虫文件
# -*- coding: utf-8 -*-
import scrapy
#导入编写的 item
from xunleidianying.items import XunleidianyingItem class XunleibtSpider(scrapy.Spider):
name = 'xunleiBT'
allowed_domains = ['www.xl720.com']
start_urls = ['https://www.xl720.com/thunder/years/2019/'] def parse(self, response):
url_list = response.xpath('//h3//@href').getall()
for url in url_list:
yield scrapy.Request(url,callback=self.detail_page)
nextpage_link = response.xpath('//a[@class="nextpostslink"]/@href').get()
if nextpage_link:
yield scrapy.Request(nextpage_link, callback=self.parse) def detail_page(self,response):
# 切记item带括号
BT_item = XunleidianyingItem()
BT_item['name'] = response.xpath('//h1/text()').get()
BT_item['information'] = ''.join(response.xpath('//div[@id="info"]//text()').getall())
BT_item['content'] = response.xpath('//div[@id="link-report"]/text()').get()
BT_item['downloadurl'] = response.xpath('//div[@class="download-link"]/a/text() | //div[@class="download-link"]/a/@href').getall()
yield BT_item
ITEM爬取完成后该干什么?当然是入库保存了,编写pipelines.py文件进行入库保存
再次提醒别忘了去settings.py中开启 ITEM_PIPELINES 选项
pipelines.py文件代码如下:
import pymongo
#连接本地数据库
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
#数据库名称
mydb = myclient["movie_BT"]
#数据表名称
mysheet = mydb["movie"] class XunleidianyingPipeline(object):
def process_item(self, item, spider):
data = dict(item)
mysheet.insert(data)
return item
再次运行main.py 等待运行完成后打开数据库查询
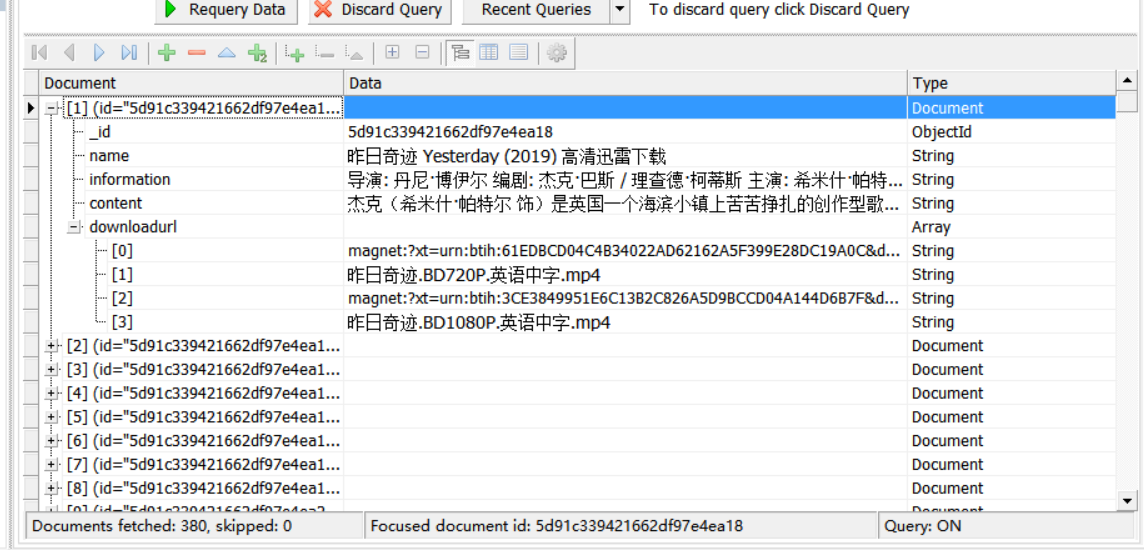
数据保存完成,这次我们一共导入了380个数据,可以愉快的查看电影了
scrapy爬取迅雷电影天堂最新电影ed2k的更多相关文章
- python利用requests和threading模块,实现多线程爬取电影天堂最新电影信息。
利用爬到的数据,基于Django搭建的一个最新电影信息网站: n1celll.xyz (用的花生壳动态域名解析,服务器在自己的电脑上,纯属自娱自乐哈.) 今天想利用所学知识来爬取电影天堂所有最新电影 ...
- scrapy爬取豆瓣电影top250
# -*- coding: utf-8 -*- # scrapy爬取豆瓣电影top250 import scrapy from douban.items import DoubanItem class ...
- Python爬虫爬取BT之家找电影资源
一.写在前面 最近看新闻说圣城家园(SCG)倒了,之前BT天堂倒了,暴风影音也不行了,可以说看个电影越来越费力,国内大厂如企鹅和爱奇艺最近也出现一些幺蛾子,虽然目前版权意识虽然越来越强,但是很多资源在 ...
- scrapy 动态网页处理——爬取鼠绘海贼王最新漫画
简介 scrapy是基于python的爬虫框架,易于学习与使用.本篇文章主要介绍如何使用scrapy爬取鼠绘漫画网海贼王最新一集的漫画. 源码参见:https://github.com/liudaol ...
- 以豌豆荚为例,用 Scrapy 爬取分类多级页面
本文转载自以下网站:以豌豆荚为例,用 Scrapy 爬取分类多级页面 https://www.makcyun.top/web_scraping_withpython17.html 需要学习的地方: 1 ...
- scrapy爬取海量数据并保存在MongoDB和MySQL数据库中
前言 一般我们都会将数据爬取下来保存在临时文件或者控制台直接输出,但对于超大规模数据的快速读写,高并发场景的访问,用数据库管理无疑是不二之选.首先简单描述一下MySQL和MongoDB的区别:MySQ ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- 小说免费看!python爬虫框架scrapy 爬取纵横网
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 风,又奈何 PS:如有需要Python学习资料的小伙伴可以加点击下方 ...
- Scrapy爬取美女图片 (原创)
有半个月没有更新了,最近确实有点忙.先是华为的比赛,接着实验室又有项目,然后又学习了一些新的知识,所以没有更新文章.为了表达我的歉意,我给大家来一波福利... 今天咱们说的是爬虫框架.之前我使用pyt ...
随机推荐
- 使用Eclipse开发动态Javaweb项目
使用Eclipse开发动态Javaweb项目 一.Eclipse的使用 1. 把开发选项切换到 JavaEE 2. 可以在 Window -> Show View 中找到 Package Exp ...
- Bootstrap如何禁止响应式布局
Bootstrap 会自动帮你针对不同的屏幕尺寸调整你的页面,使其在各个尺寸的屏幕上表现良好.下面我们列出了如何禁用这一特性,就像这个非响应式布局实例页面一样. 禁止响应式布局有如下几步: 移除 此 ...
- ZYNQ Block Design中总线位宽的截取与合并操作
前言 在某些需求下,数据的位宽后级模块可能不需要原始位宽宽度,需要截位,而某些需求下,需要进行多个数据的合并操作. 在verilog下,截位操作可如下所示: wire [7:0] w_in; wire ...
- 探索JAVA并发 - 终于搞懂了sleep/wait/notify/notifyAll
> sleep/wait/notify/notifyAll分别有什么作用?它们的区别是什么?wait时为什么要放在循环里而不能直接用if? ## 简介 首先对几个相关的方法做个简单解释,Obje ...
- dmg文件转iso格式
1. 简介 dmg是MAC苹果机上的压缩镜像文件,相当于在Windows上常见的iso文件. dmg格式在苹果机上可以直接运行加载,在Windows平台上需要先转换为iso格式. 2. 转换工具 本文 ...
- kick start 2019 round D T3题解
---恢复内容开始--- 题目大意:共有N个房子,每个房子都有各自的坐标X[i],占据每个房子需要一定花费C[i].现在需要选择K个房子作为仓库,1个房子作为商店(与题目不同,概念一样),由于仓库到房 ...
- 【Offer】[59-1] 【滑动窗口的最大值】
题目描述 思路分析 测试用例 Java代码 代码链接 题目描述 给定一个数组和滑动窗口的大小,请找出所有滑动窗口里的最大值.例如,如果输入数组{2,3,4,2,6,2, 5,1}及滑动窗口的大小3,那 ...
- 【LeetCode】55-跳跃游戏
题目描述 给定一个非负整数数组,你最初位于数组的第一个位置. 数组中的每个元素代表你在该位置可以跳跃的最大长度. 判断你是否能够到达最后一个位置. 示例 1: 输入: [2,3,1,1,4] 输出: ...
- Go 语言基础——变量常量的定义
go语言不支持隐式类型转换,别名和原有类型也不能进行隐式类型转换 go语言不支持隐式转换 变量 变量声明 var v1 int var v2 string var v3 [10]int // 数组 v ...
- 史上最全面的SignalR系列教程-目录汇总
1.引言 最遗憾的不是把理想丢在路上,而是理想从未上路. 每一个将想法变成现实的人,都值得称赞和学习. 致正在奔跑的您! 2.SignalR介绍 SignalR实现服务器与客户端的实时通信 ,她是一个 ...