spark的wordcount
在开发环境下实现第一个程序wordcount
1、下载和配置scala,注意不要下载2.13,在spark-core明确支持scala2.13前,使用2.12或者2.11比较好。
https://www.scala-lang.org/download/
2、windows环境下的scala配置,可选
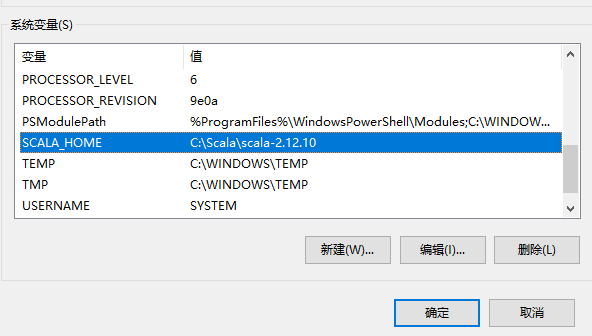

3、开发工具IDEA环境设置,全局环境添加scala的sdk,注意scala的源码要手动下载和添加
4、在IDEA中新建MAVEN项目,添加scala框架支持

5、在MAVEN工程添加spark-core依赖,注意根据自己需要选择对应的版本,版本不对很可能会出现运行期异常。
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>2.4.4</version>
</dependency>
</dependencies>
6、wordcount代码
在项目根目录(与src平级)中新建一个input目录,里面放入需要统计词频的文本文件
package com.home.spark import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext} object WordCount {
def main(args: Array[String]): Unit = {
//获取环境
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkWordCount") //获取上下文
val sc: SparkContext = new SparkContext(conf) //读取每一行
val lines: RDD[String] = sc.textFile("input") //扁平化,将每行数据拆分成单个词(自定义业务逻辑)
val words: RDD[String] = lines.flatMap(_.split(" ")) //结构转换,对每个词获得初始词频
val wordToOne: RDD[(String, Int)] = words.map((_,1)) //词频计数
val wordToSum: RDD[(String, Int)] = wordToOne.reduceByKey(_+_) //按词频数量降序排序
val wordToSorted: RDD[(String, Int)] = wordToSum.sortBy(_._2,false) //数据输出
val result: Array[(String, Int)] = wordToSorted.collect() //打印
result.foreach(println) //关闭上下文
sc.stop()
}
}
spark的wordcount的更多相关文章
- [转] 用SBT编译Spark的WordCount程序
问题导读: 1.什么是sbt? 2.sbt项目环境如何建立? 3.如何使用sbt编译打包scala? [sbt介绍 sbt是一个代码编译工具,是scala界的mvn,可以编译scala,java等,需 ...
- Spark 实现wordcount
配置完spark之后,使用spark实现wordcount,这一部分完全参考<深入理解Spark:核心思想与源码分析> 依然使用hadoop wordcountTest的那几个txt文件 ...
- 用SBT编译Spark的WordCount程序
问题导读: 1.什么是sbt? 2.sbt项目环境如何建立? 3.如何使用sbt编译打包scala? sbt介绍 sbt是一个代码编译工具,是scala界的mvn,可以编译scala,java等,需要 ...
- 编写Spark的WordCount程序并提交到集群运行[含scala和java两个版本]
编写Spark的WordCount程序并提交到集群运行[含scala和java两个版本] 1. 开发环境 Jdk 1.7.0_72 Maven 3.2.1 Scala 2.10.6 Spark 1.6 ...
- spark 例子wordcount topk
spark 例子wordcount topk 例子描述: [单词计算wordcount ] [词频排序topk] 单词计算在代码方便很简单,基本大体就三个步骤 拆分字符串 以需要进行记数的单位为K,自 ...
- 1.spark的wordcount解析
一.Eclipse(scala IDE)开发local和cluster (一). 配置开发环境 要在本地安装好java和scala. 由于spark1.6需要scala 2.10.X版本的.推荐 2 ...
- .Net for Spark 实现 WordCount 应用及调试入坑详解
.Net for Spark 实现WordCount应用及调试入坑详解 1. 概述 iNeuOS云端操作系统现在具备物联网.视图业务建模.机器学习的功能,但是缺少一个计算平台产品.最近在调研使用 ...
- Spark版wordcount,并根据词频进行排序
import org.apache.spark.{SparkConf, SparkContext}/** * Created by loushsh on 2017/10/9. */object Wor ...
- Spark开发wordcount程序
1.java版本(spark-2.1.0) package chavin.king; import org.apache.spark.api.java.JavaSparkContext; import ...
- 在IDEA中编写Spark的WordCount程序
1:spark shell仅在测试和验证我们的程序时使用的较多,在生产环境中,通常会在IDE中编制程序,然后打成jar包,然后提交到集群,最常用的是创建一个Maven项目,利用Maven来管理jar包 ...
随机推荐
- go-爬图片
go语言爬取图片 注:动态加载出来的爬取不到,或怕取出来图片出错,代码中的网页是可以正常爬取的 package main import ( "fmt" "io" ...
- SpringCloud(六):服务网关zuul-API网关(服务降级和过滤)
什么是API网关: 在微服务架构中,通常会有多个服务提供者.设想一个电商系统,可能会有商品.订单.支付.用户等多个类型的服务,而每个类型的服务数量也会随着整个系统体量的增大也会随之增长和变更.作为UI ...
- Java开发人员必备十大工具
Java世界中存在着很多工具,从著名的IDE(例如Eclipse,NetBeans和IntelliJ IDEA)到JVM profiling和监视工具(例如JConsole,VisualVM,Ecli ...
- https连接
在发送连接之前设置显示握手过程: System.setProperty("javax.net.debug", "all"); DubboServer ...
- 渗透测试学习 二十九、kali安装,信息搜集,服务器扫描
kali安装,信息搜集,服务器扫描 kali介绍 Kali Linux是基于Debian的Linux发行版, 设计用于数字取证操作系统.由Offensive Security Ltd维护和资助.最先由 ...
- java8-05-再探函数式接口
1.自定义函数式接口 MyFun 传入一个参数 返回一个参数
- 子传父flase注意点
1==>在子传递数据给父亲的时候, closeBottom(){ this.$emit("closeBottom",false) } false不加引号. 2==>
- Comet OJ - Contest #8
Comet OJ - Contest #8 传送门 A.杀手皇后 签到. Code #include <bits/stdc++.h> using namespace std; typede ...
- mysql深入学习(一)
Mysql高级学习 一.Mysql简介 1.概述 MySQL是一个关系型数据库管理系统,由瑞典MySQL AB公司开发,目前属于Oracle公司. MySQL是一种关联数据库管理系统,将数据保存在不同 ...
- 开发工具IntelliJ IDEA
开发工具概述 IDEA是一个专门针对Java的集成开发工具(IDE),由Java语言编写.所以,需要有JRE运行环境并配置好环境变量.它可以极大地提升我们的开发效率.可以自动编译,检查错误.在公司中, ...