jieba分词原理-DAG(NO HMM)
最近公司在做一个推荐系统,让我给论坛上的帖子找关键字,当时给我说让我用jieba分词,我周末回去看了看,感觉不错,还学习了一下具体的原理
首先,通过正则表达式,将文章内容切分,形成一个句子数组,这个比较好理解
然后构造出句子的有向无环图(DAG)
def get_DAG(self, sentence):
self.check_initialized()
DAG = {}
N = len(sentence)
for k in xrange(N):
tmplist = []
i = k
frag = sentence[k]
while i < N and frag in self.FREQ:#对每一个字从这个字开始搜索成词位置
if self.FREQ[frag]:
tmplist.append(i)#如果可以成词就加入到DAG中
i += 1
frag = sentence[k:i + 1]
if not tmplist:
tmplist.append(k)#如果找不到词语,就将自己加入DAG
DAG[k] = tmplist
return DAG
- 对句子中的每个字进行分析,从右边一位开始,看sentence[k:i+1]这个词语是否在预设的字典中,这个字典保存了常用的词语(和词语的一部分,但权重为0)和其权重.如果有,并且如果字典中的这个词的权值不等于0,那么就将i放到tmplist里,然后i+=1,继续下一轮循环,如果没有这个词,那就停下来,然后移动k,让k=k+1,找下一个字的成词位置
- 比如有这样一个句子:'我从海淀区搬到了朝阳区',一共11个字
- 通过上面的计算,得到一个字典:<class 'dict'>: {0: [0], 1: [1], 2: [2, 3, 4], 3: [3, 4], 4: [4], 5: [5, 6], 6: [6], 7: [7], 8: [8, 9, 10], 9: [9], 10: [10]},字典键代表每个字在字符串中的位置,比如,0代表'我',1代表'从',而每个键对应一个数组,比如2对应[2,3,4],这个表示:'海'(2)/'海淀'(2-3)/'海淀区'(2-4),这三个字符串可以成为词语
- 这样,我们就得到了所有可以成词的位置了
选出成词概率最大的位置
def calc(self, sentence, DAG, route):
N = len(sentence)
route[N] = (0, 0)
logtotal = log(self.total)#常数值
for idx in xrange(N - 1, -1, -1):#从后往前分析
route[idx] = max((log(self.FREQ.get(sentence[idx:x + 1]) or 1) -
logtotal + route[x + 1][0], x) for x in DAG[idx])
- 对于句子中的每一个字,计算候选位置中,哪个成词概率最大
- 比如2:[2,3,4],分别对2/3/4进行计算,计算公式:log(词的概率)-常数+下一个字的成词概率
- 词语的概率还是用之前保存了所有常用词的字典(也可以自己定义字典),下一个字的成词概率是上一个循环计算出来的,我们要从末尾开始计算,得到的结果作为下一个循环的参数,这样我们就找到了最大成词概率的切分位置
- 为什么要加上下一个字的成词概率的呢?因为下一个词的成词概率高的话,我们做出的切分就越正确,越有可能切成两个正确的词语,而不是左边的词语概率高,而右边根本不是一个正确的词语
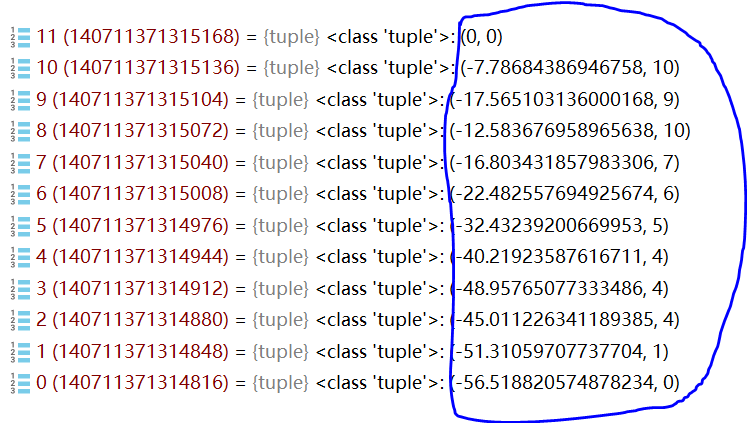
如上图,蓝色圈中的部分,括号右边代表了成词的位置,比如2,括号的右边是4,说明2-4这个词的成词概率高,我们就切成'海淀区'
切分的过程是这样的
- 从头开始,寻找每个位置对应的成词位置,取出来
- 跳到成词位置的下一个位置开始循环
这样,我们就能得到:0/1/2-4/5/6/7/8-10
具体为:我/从/海淀区/搬/到/了/朝阳区
到此为止整个过程就结束了
不过,官方默认算法还有个hmm,这次先不说了,请听下回分解
jieba分词原理-DAG(NO HMM)的更多相关文章
- Jieba分词原理与解析
https://www.jianshu.com/p/dfdfeaa7d01f 1 HMM模型 image.png 马尔科夫过程: image.png image.png 以天气判断为例:引 ...
- jieba分词原理解析:用户词典如何优先于系统词典
目标 查看jieba分词组件源码,分析源码各个模块的功能,找到分词模块,实现能自定义分词字典,且优先级大于系统自带的字典等级,以医疗词语邻域词语为例. jieba分词地址:github地址:https ...
- 自然语言处理课程(二):Jieba分词的原理及实例操作
上节课,我们学习了自然语言处理课程(一):自然语言处理在网文改编市场的应用,了解了相关的基础理论.接下来,我们将要了解一些具体的.可操作的技术方法. 作为小说爱好者的你,是否有设想过通过一些计算机工具 ...
- python环境jieba分词的安装
我的python环境是Anaconda3安装的,由于项目需要用到分词,使用jieba分词库,在此总结一下安装方法. 安装说明======= 代码对 Python 2/3 均兼容 * 全自动安装:`ea ...
- python结巴(jieba)分词
python结巴(jieba)分词 一.特点 1.支持三种分词模式: (1)精确模式:试图将句子最精确的切开,适合文本分析. (2)全模式:把句子中所有可以成词的词语都扫描出来,速度非常快,但是不能解 ...
- 自然语言处理之jieba分词
在处理英文文本时,由于英文文本天生自带分词效果,可以直接通过词之间的空格来分词(但是有些人名.地名等需要考虑作为一个整体,比如New York).而对于中文还有其他类似形式的语言,我们需要根据来特殊处 ...
- 自然语言处理之中文分词器-jieba分词器详解及python实战
(转https://blog.csdn.net/gzmfxy/article/details/78994396) 中文分词是中文文本处理的一个基础步骤,也是中文人机自然语言交互的基础模块,在进行中文自 ...
- python jieba分词工具
源码地址:https://github.com/fxsjy/jieba 演示地址:http://jiebademo.ap01.aws.af.cm/ 特点 1,支持三种分词模式: a,精确模式,试图将句 ...
- python jieba分词(结巴分词)、提取词,加载词,修改词频,定义词库 -转载
转载请注明出处 “结巴”中文分词:做最好的 Python 中文分词组件,分词模块jieba,它是python比较好用的分词模块, 支持中文简体,繁体分词,还支持自定义词库. jieba的分词,提取关 ...
随机推荐
- webservice调用天气服务
常见服务:http://www.webxml.com.cn/zh_cn/support.aspx 可能用到缺少的ArrayOfString.java文件 package com.test.wes.we ...
- 剑指offer 12:二进制中1的个数
题目描述 输入一个整数,输出该数二进制表示中1的个数.其中负数用补码表示. 解法一:设置标志为flag=1,逐个位移至不同位置,比较是否为1. C++实现 class Solution { publi ...
- 一个java的http请求的封装工具类
java实现http请求的方法常用有两种,一种则是通过java自带的标准类HttpURLConnection去实现,另一种是通过apache的httpclient去实现.本文用httpclient去实 ...
- elasticsearch的window的安装和启动
1.下载elasticserch的window和kibana的安装包 2.解压 进入elasticseach的bin目录下elasticsearch.bat 启动页面localhost:9200 3 ...
- linux系统管理-输入输出
目录 linux系统管理-输入输出 参数传递xargs linux系统管理-输入输出 重定向 将原本要输出到屏幕上的数据信息,重新定向到指定的文件中 运行程序,或者输入一个命令:默认打开4个文件描述符 ...
- OceanBase 架构初探
OceanBase 架构初探 原创衣舞晨风 发布于2018-11-13 08:44:14 阅读数 1417 收藏 展开 1.设计思路 OceanBase的目标是支持数百TB的数据量以及数十万TPS. ...
- 第十二章 WEB渗透
Web技术发展 • 静态WEB• 动态WEB • 应用程序 • 数据库 • 每个人看到的内容不同 • 根据用户输入返回不同结果 WEB攻击面• Network• OS• WEB Server• App ...
- 卷积层输出feature maps尺寸的计算
默认feature maps的宽和高相等. 常规卷积 输入的feature maps尺寸为i,卷积核的尺寸为k,stride为s,padding为p,则输出的feature maps的尺寸o为 当pa ...
- Java 种15种锁的介绍:公平锁,可重入锁,独享锁,互斥锁等等…
Java 中15种锁的介绍 1,在读很多并发文章中,会提及各种各样的锁,如公平锁,乐观锁,下面是对各种锁的总结归纳: 公平锁/非公平锁 可重入锁/不可重入锁 独享锁/共享锁 互斥锁/读写锁 乐观锁/悲 ...
- luoguP2163 [SHOI2007]园丁的烦恼
安利系列博文 https://www.cnblogs.com/tyner/p/11565348.html https://www.cnblogs.com/tyner/p/11605073.html 题 ...