Data Deduplication Workflow Part 1
Data deduplication provides a new approach to store data and eliminate duplicate data in chunk level.
A typical data deduplication workflow can be explained like this.
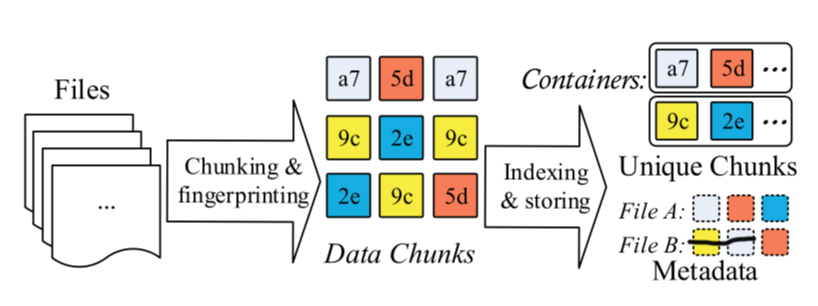
File metadata describes how to restore the file use unique chunks.
Chunk level deduplication approach has five key stages.
- Chunking
- Fingerprinting
- Indexing fringerprints
- Further compression
- Storage management
Different Stage has its own challenges, which may become the bottleneck for restoring file or compressing files.
Chunking
At the chunking stage, we should split the data stream into chunks, which can be presented at the fingerprints.
The different method splitting data streaming has different result and different efficiency.
The splitting method can be divided into two categories:
Fixed Size Chunking, which just split the data stream into fixed size chunk, simply and easily .
Content Defined Chunking, which split the data into variable size chunk, depending on the content.
Although fixed size chunking is simple and quick, the biggest problem is Boundary Shift. Boundary Shift Problem is when little part of data stream is modified, all the subsequent chunks will be changed, because of the boundary is shifted.
Content defined chunking uses a sliding-window technique on the content of data stream and computes a hash value of the window. If the hash value is satisfied some predefined conditions, it will generate a chunk.
Chunk's size can also be optimized. If we use CDC (content defined chunking), the size of chunking can not be in charge. On some extremely condition, it will generate too large or too small chunking. If a chunking is too large, the compression ratio will decrease. Because the large chunk can hide duplicates from being detected. If a chunking is too small, the file metadata will increase. What's more, it can cause indexing fingerprints problem. So we can define the max and min chunk size.
Chunking still has some problems such as how to detect the deduplicate accurately, how to accelerate computing time cost.
Data Deduplication Workflow Part 1的更多相关文章
- Data De-duplication
偶尔看到data deduplication的博客,还挺有意思,记录之 http://blog.csdn.net/liuben/article/details/5829083?reload http: ...
- 大数据去重(data deduplication)方案
数据去重(data deduplication)是大数据领域司空见惯的问题了.除了统计UV等传统用法之外,去重的意义更在于消除不可靠数据源产生的脏数据--即重复上报数据或重复投递数据的影响,使计算产生 ...
- Note: Transparent data deduplication in the cloud
What Design and implement ClearBox which allows a storage service provider to transparently attest t ...
- 论文阅读 Prefetch-aware fingerprint cache management for data deduplication systems
论文链接 https://link.springer.com/article/10.1007/s11704-017-7119-0 这篇论文试图解决的问题是在cache 环节之前,prefetch-ca ...
- Data Deduplication in Windows Server 2012
https://blogs.technet.microsoft.com/filecab/2012/05/20/introduction-to-data-deduplication-in-windows ...
- Note: File Recipe Compression in Data Deduplication Systems
Zero-Chunk Suppression 检测全0数据块,将其用预先计算的自身的指纹信息代替. Detect zero chunks and replace them with a special ...
- SharePoint 2013 create workflow by SharePoint Designer 2013
这篇文章主要基于上一篇http://www.cnblogs.com/qindy/p/6242714.html的基础上,create a sample workflow by SharePoint De ...
- Seven Python Tools All Data Scientists Should Know How to Use
Seven Python Tools All Data Scientists Should Know How to Use If you’re an aspiring data scientist, ...
- 重复数据删除(De-duplication)技术研究(SourceForge上发布dedup util)
dedup util是一款开源的轻量级文件打包工具,它基于块级的重复数据删除技术,可以有效缩减数据容量,节省用户存储空间.目前已经在Sourceforge上创建项目,并且源码正在不断更新中.该工具生成 ...
随机推荐
- Java 学习笔记之 线程Priority
线程Priority: 线程可以划分优先级,优先级较高的线程得到的CPU资源较多,也就是CPU优先执行优先级较高的线程对象中的任务. 设置线程优先级有助于帮助“线程规划器”确定在下一次选择哪个线程来优 ...
- 02-22 决策树C4.5算法
目录 决策树C4.5算法 一.决策树C4.5算法学习目标 二.决策树C4.5算法详解 2.1 连续特征值离散化 2.2 信息增益比 2.3 剪枝 2.4 特征值加权 三.决策树C4.5算法流程 3.1 ...
- java并发之synchronized详解
前言 多个线程访问同一个类的synchronized方法时, 都是串行执行的 ! 就算有多个cpu也不例外 ! synchronized方法使用了类java的内置锁, 即锁住的是方法所属对象本身. 同 ...
- asp.net mvc select用法
var statusSelectItems = new List<SelectListItem> { "}, "}, "}, "}, "} ...
- 编程杂谈——std::vector与List<T>的性能比较
昨天在比较完C++中std::vector的两个方法的性能差异并留下记录后--编程杂谈--使用emplace_back取代push_back,今日尝试在C#中测试对应功能的性能. C#中对应std:: ...
- python中函数调用---可变对象以及不可变对象
# 定义函数 def demo(obj): print("原值: ",obj) obj += obj #调用函数 print("========值传递=======&qu ...
- unittest中HTMLTestRunner模块生成
unittest里面是不能生成html格式报告的,需要导入一个第三方的模块:HTMLTestRunner 一.导入HTMLTestRunner 方法1.这个模块下载不能通过pip安装了,只能下载后手动 ...
- 代码审计-phpcms9任意文件读取
漏洞文件: /phpcms/modules/content/down.php download函数 这个函数开始几行代码的作用和init函数中的几乎一样,都是从parse_str 解析传入的a_k参数 ...
- ssh隧道代理连接
0x00 什么是SSH隧道 场景: 假设有两台主机: A主机为外网,B主机为内网通常来说外网主机A是无法直接连接到内网主机B的,这时如果要实现A主机通过ssh控制B主机,通常来说有两种方法: 1.端口 ...
- PHP get_class_vars 和 (array)
<?php class Girl { public $id = 1; public $name = 'zhy'; } $start = microtime(TRUE); var_dump(get ...