Data Deduplication Workflow Part 1
Data deduplication provides a new approach to store data and eliminate duplicate data in chunk level.
A typical data deduplication workflow can be explained like this.
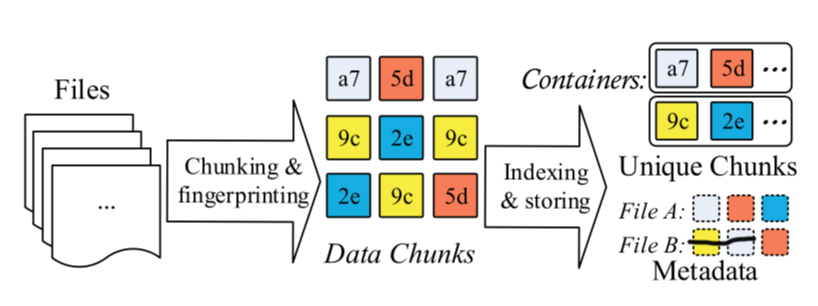
File metadata describes how to restore the file use unique chunks.
Chunk level deduplication approach has five key stages.
- Chunking
- Fingerprinting
- Indexing fringerprints
- Further compression
- Storage management
Different Stage has its own challenges, which may become the bottleneck for restoring file or compressing files.
Chunking
At the chunking stage, we should split the data stream into chunks, which can be presented at the fingerprints.
The different method splitting data streaming has different result and different efficiency.
The splitting method can be divided into two categories:
Fixed Size Chunking, which just split the data stream into fixed size chunk, simply and easily .
Content Defined Chunking, which split the data into variable size chunk, depending on the content.
Although fixed size chunking is simple and quick, the biggest problem is Boundary Shift. Boundary Shift Problem is when little part of data stream is modified, all the subsequent chunks will be changed, because of the boundary is shifted.
Content defined chunking uses a sliding-window technique on the content of data stream and computes a hash value of the window. If the hash value is satisfied some predefined conditions, it will generate a chunk.
Chunk's size can also be optimized. If we use CDC (content defined chunking), the size of chunking can not be in charge. On some extremely condition, it will generate too large or too small chunking. If a chunking is too large, the compression ratio will decrease. Because the large chunk can hide duplicates from being detected. If a chunking is too small, the file metadata will increase. What's more, it can cause indexing fingerprints problem. So we can define the max and min chunk size.
Chunking still has some problems such as how to detect the deduplicate accurately, how to accelerate computing time cost.
Data Deduplication Workflow Part 1的更多相关文章
- Data De-duplication
偶尔看到data deduplication的博客,还挺有意思,记录之 http://blog.csdn.net/liuben/article/details/5829083?reload http: ...
- 大数据去重(data deduplication)方案
数据去重(data deduplication)是大数据领域司空见惯的问题了.除了统计UV等传统用法之外,去重的意义更在于消除不可靠数据源产生的脏数据--即重复上报数据或重复投递数据的影响,使计算产生 ...
- Note: Transparent data deduplication in the cloud
What Design and implement ClearBox which allows a storage service provider to transparently attest t ...
- 论文阅读 Prefetch-aware fingerprint cache management for data deduplication systems
论文链接 https://link.springer.com/article/10.1007/s11704-017-7119-0 这篇论文试图解决的问题是在cache 环节之前,prefetch-ca ...
- Data Deduplication in Windows Server 2012
https://blogs.technet.microsoft.com/filecab/2012/05/20/introduction-to-data-deduplication-in-windows ...
- Note: File Recipe Compression in Data Deduplication Systems
Zero-Chunk Suppression 检测全0数据块,将其用预先计算的自身的指纹信息代替. Detect zero chunks and replace them with a special ...
- SharePoint 2013 create workflow by SharePoint Designer 2013
这篇文章主要基于上一篇http://www.cnblogs.com/qindy/p/6242714.html的基础上,create a sample workflow by SharePoint De ...
- Seven Python Tools All Data Scientists Should Know How to Use
Seven Python Tools All Data Scientists Should Know How to Use If you’re an aspiring data scientist, ...
- 重复数据删除(De-duplication)技术研究(SourceForge上发布dedup util)
dedup util是一款开源的轻量级文件打包工具,它基于块级的重复数据删除技术,可以有效缩减数据容量,节省用户存储空间.目前已经在Sourceforge上创建项目,并且源码正在不断更新中.该工具生成 ...
随机推荐
- Linux kail安装及查看命令
Linux kail安装及查看命令 apt-get update //更新源 apt-get install package ...
- JNA的步骤、简单实例以及资料整理
1.步骤 1.编写dll文件,放入项目的bin目录(在window上是dll文件,在Linux上是so文件,dll和so都是由C程序生成) 2.新建接口继承Library 3.加载对应的dll或者 ...
- 【windows】远程桌面 把远程服务器的explorer.exe进程关掉了,咋办?
在操作windows2008R2服务器时不小心把explorer.exe进程关闭了,瞬间整个界面就蓝色了. 重启,做不到,各种快捷键用不了,最后发现Alt+Tab可以用,刚好打开了IIS, 打开其中一 ...
- 小程序webview调用微信扫一扫的“曲折”思路
自上一篇遇到webview中没有返回按钮之后,虽然跳出坑了.解决方案:<小程序webview跳转页面后没有返回按钮完美解决方案> 但是,小程序踩坑之路并没有结束.在公众号网页中通过配置AP ...
- pycharm 激活码 2019/11最新福利(2)
812LFWMRSH-eyJsaWNlbnNlSWQiOiI4MTJMRldNUlNIIiwibGljZW5zZWVOYW1lIjoi5q2j54mIIOaOiOadgyIsImFzc2lnbmVlT ...
- win10家庭版升级专业版
在网上随便百度一个产品密钥,记得一定要先断网(这个很重要),否则很难升级. 升级之后发现产品未激活,下载KMS激活一下就可以了.
- MongoDB 走马观花(全面解读篇)
目录 一.简介 二.基本模型 BSON 数据类型 分布式ID 三.操作语法 四.索引 索引特性 索引分类 索引评估.调优 五.集群 分片机制 副本集 六.事务与一致性 一致性 小结 一.简介 Mong ...
- bugku 很普通的数独
下载下是一个没有后缀的文件,使用winhex打开,头文件为50 4b 03 为zip文件,修改后缀,打开压缩包,是一大堆数独图片. 仔细看了好久,发现这几张图片像二维码,而且1 5 21这三张图的位置 ...
- python基础一(运算符/变量定义/数据类型)
一.运算符 1.算数运算符 (1)加(+) 注意:字符串与整数之间不能进行相加,需要通过str()或int()进行转换数据类型 整数与整数相加 >>> 1 + 1 2 >> ...
- windows显示文件后缀名
win+E 进入到计算机 点击组织 点击文件夹和搜索选项 先点击查看,然后去掉勾选隐藏已知文件类型的扩展名