Python自学day-2
一、模块
1.sys模块
import sys
print(sys.path)
['D:\\pycharm_workspace\\FirstProject\\day2',
import sys
print(sys.argv)
sys.argv保存参数,第一个参数为该模块文件的相对路径,后面的参数加在一起形成一个列表。
2.os模块
import os
os.system("dir") #只执行命令,不保存结果
os.system()执行一条系统命令。直接输出到屏幕,不能存到变量里,该方法返回状态码(0为成功)。
import os
cmd_res = os.popen("dir").read()
print(cmd_res)
import os
os.mkdir("new_dir")
os.mkdir("new_dir"),在当前路径创建一个新目录。当目录已经存在时,会抛出异常。
3.第三方模块
二、pyc
三、Python执行过程
四、数据类型初识
五、三元运算
a,b,c = 1,3,5
result = a if a>b else c
print(result)
六、bytes和str
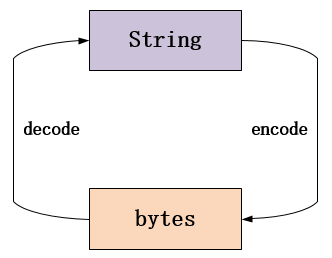
msg = "我爱北京天安门".encode("utf-8")
print(msg)
msg = msg.decode("utf-8")
print(msg)
七、列表
names = []
names = ["Leo","Alex","Jack","Leno"]
index=1
names[index] #取出Alex。
names = [1,2,3,['a','b'],4,5]
names2 = names.copy()
names2[2] = 10
names2[3][1] = 'c'
print(names)
print(names2)
第一层的数据完全copy。第二层的数据未copy,copy的是内存地址。共同指向同一块内存区域。
import copy
names = [1,2,3,['a','b'],4,5]
names2 = copy.copy(names) #和list中的copy是一摸一样的
names3 = copy.deepcopy(names) #深度copy,真正意义上的copy。但用得少,占两份完整的内存空间。
num = [0,1,2,3,4,5,6,7,8,9,10]
for i in num[0:-1:2]:
print(i)
八、元组
names = ("192.168.1.100","admin","passwd")
九、判断值是否为数值
num = input("please input a num")
if num.isdigit():
num = int(num)
十、字符串操作
name = "leo zheng leokale"
name = "my name is {name},I am {year} years old."
print(name.format(name = "Leokale",year = 32))
name = "my name is {name},I am {year} years old."
print(name.format_map({"name":"leokale","year":32}))
判断是否是阿拉伯数字和字符(isalnum):
print("".isalnum()) #输出True
print("123abc".isalnum()) #输出True
print("123abc*".isalnum()) #输出False
判断是否为纯英文字符(isalpha):包含大小写
print("abcABC".isalpha()) #返回True
print("abcABC123".isalpha()) #返回False
判断是否为十进制(isdecimal)
print("my_name".isidentifier()) #输出True
print("--my_name".isidentifier()) #输出false
判断是否全为小写(islower)
print("+".join(["my","name",'is','leokale'])) #输出my+name+is+leokale
print("name".ljust(20,'*')) #输出name****************
在前面使用字符填充(rjust):
print("name".rjust(20,'*'))
全部转换为小写(lower)
name = " name \n"
print(name.strip())
name = "leokale good day is today"
ppp = str.maketrans("leokalgdys","123456789*") #数量要对应
print(name.translate(ppp))
替换(replace):
print("namea".replace("a","*",2)) #输出 n*me*
从右边开始查找返回索引(rfind):
print("leokale".rfind('l')) #输出5
按某个字符分割(split):
print("my name is leo".split()) #输出['my', 'name', 'is', 'leo']
print("my+name+is+leo".split('+'))
print("Name".swapcase()) #输出 nAME
转换为Title(title):
print("good thing".title()) #输出 Good Thing
用0在前面补位(zfill):主要用于16进制前面使用0补位。
十一、字典
info = {
'id1':'Leo',
'id2':'Jack',
'id3':'Alex',
'id4':'Song'
}
- dict是无序的,没有下标索引。打印出来,顺序是乱的。
- key必须是唯一的,天生去重。
print(info)
print(info['id1']) #输出 leo
info['id1'] = 'Kale'
print(info['id1']) #输出 Kale
添加一条:id5不存在时,则为添加。
info['id5'] = 'Lily'
删除:
del info['id2']
print(info)
info.pop('id2')
print(info)
info.popitem() #随机删除一个
print(info)
if 'id1' in info: #'id1' in info,若存在返回True,不存在返回False。列表和元组也可以这样判断。
print("id1存在")
info = {
'id1':{
'name':'Leo',
'age':32
},
'id2':{
'name':'Boob',
'age':12
},
'id3':{
'name':'Alex',
'age':22
},
'id4':{
'name':'Jack',
'age':56
}
}
修改id2中的年龄:
info['id2']['age'] = 44
print(info)
info.setdefault('id5',{'name':"武藤兰"})
print(info) #添加了id5,name为武藤兰
info.setdefault('id5',{'name':"藤原爱"})
print(info) #已经存在id5,则返回{'name':'武藤兰'}
更新(update):若info与info2之间的key有交叉,则使用info2中的内容替代。没交叉的部分,在info里创建。
info2 = {
'id1':{
1:2,
2:3
}
}
info.update(info2)
把字典转换为列表,每一个key-value转换为元组:
print(info.items()) #输出dict_items([('id1', {1: 2, 2: 3}), ('id2', {'name': 'Boob', 'age': 12}), ('id3', {'name': 'Alex', 'age': 22}), ('id4', {'name': 'Jack', 'age': 56})])
info_list = list(info.items())
dict1 = dict.fromkeys([1,2,3,4],"test")
print(dict1)
在这里,若fromkeys的第二个参数为二层以上结构。则dict1每个key对应的value为一个引用。修改其中一个,全部都会变化。
dict1 = dict.fromkeys([1,2,3,4],{'name':'leo'})
dict1[1]['name'] = "Jack"
print(dict1) #输出 {1: {'name': 'Jack'}, 2: {'name': 'Jack'}, 3: {'name': 'Jack'}, 4: {'name': 'Jack'}}
for key in info: #建议使用这种,高效。
print(key,info[key])
for k,v in info.items(): #有一个把字典转换为列表的过程,效率比较低,数据量大的时候体现明显。
print(k,v)
Python自学day-2的更多相关文章
- python自学笔记
python自学笔记 python自学笔记 1.输出 2.输入 3.零碎 4.数据结构 4.1 list 类比于java中的数组 4.2 tuple 元祖 5.条件判断和循环 5.1 条件判断 5.2 ...
- Python - 自学django,上线一套资产管理系统
一.概述 终于把公司的资产管理网站写完,并通过测试,然后上线.期间包括看视频学习.自己写前后端代码,用时两个多月.现将一些体会记录下来,希望能帮到想学django做web开发的人.大牛可以不用看了,小 ...
- 拎壶冲冲冲专业砸各种培训机构饭碗篇----python自学(一)
本人一直从事运维工程师,热爱运维,所以从自学的角度站我还是以python运维为主. 一.python自学,当然少不了从hello world开始,话不多说,直接上手练习 1.这个可以学会 print( ...
- [Python自学] day-21 (2) (Cookie、FBV|CBV装饰器)
一.什么是Cookie 1.什么是Cookie? Cookie是保存在客户端浏览器中的文件,其中记录了服务器让浏览器记录的一些键值对(类似字典). 当Cookie中存在数据时,浏览器在访问网站时会读取 ...
- [Python自学] day-21 (1) (请求信息、html模板继承与导入、自定义模板函数、自定义分页)
一.路由映射的参数 1.映射的一般使用 在app/urls.py中,我们定义URL与视图函数之间的映射: from django.contrib import admin from django.ur ...
- [Python自学] day-20 (Django-ORM、Ajax)
一.外键跨表操作(一对多) 在 [Python自学] day-19 (2) (Django-ORM) 中,我们利用外键实现了一对多的表操作. 可以利用以下方式来获取外键指向表的数据: def orm_ ...
- [Python自学] day-19 (2) (Django-ORM)
一.ORM的分类 ORM一般分为两类: 1.DB first:先在DB中创建数据库.表结构,然后自动生成代码中的类.在后续操作中直接在代码中操作相应的类即可. 2.Code first:直接在代码中实 ...
- [Python自学] day-19 (1) (FBV和CBV、路由系统)
一.获取表单提交的数据 在 [Python自学] day-18 (2) (MTV架构.Django框架)中,我们使用过以下方式来获取表单数据: user = request.POST.get('use ...
- [Python自学] day-18 (2) (MTV架构、Django框架、模板语言)
一.实现一个简单的Web服务器 使用Python标准库提供的独立WSGI服务器来实现MVC架构. 首先,实现一个简单的Web服务器: from wsgiref.simple_server import ...
- Python自学之路---Day13
目录 Python自学之路---Day13 常用的三个方法 匹配单个字符 边界匹配 数量匹配 逻辑与分组 编译正则表达式 其他方法 Python自学之路---Day13 常用的三个方法 1.re.ma ...
随机推荐
- Android中WebView的相关使用
近期做的项目中,遇到个非常棘手的问题: 客户给我的数据是有限制的,因此,在返回某条详细页面内容的时候,他仅仅能给我一个html片段,里面包括 文字,图片以及附件的下载地址.假设网页模版规范的爱比較好说 ...
- 【 D3.js 入门系列 --- 9.3 】 弦图生产
我个人的博客: www.ourd3js.com csdn博客为: blog.csdn.net/lzhlzz 转载请注明出处,谢谢. 弦图( Chord ),主要用于表示两个节点之间的联系.例如以下图: ...
- 创建一个显示所有预定义系统颜色的ListBox
原文 Creating a ListBox that Shows All Predefined System Colors 该System.Windows.SystemColors类包含了一系列揭露当 ...
- JDBC学习笔记——简单的连接池
1.使用LinkedList保存连接 即使是最简单的JDBC操作,也需要包含 ...
- Android 位置服务——BaiduLocation的使用
原文:Android 位置服务--BaiduLocation的使用 版权声明:本文为博主原创文章,欢迎转载,转载请在文章显眼处说明文章出处并给出连接. https://blog.csdn.net/To ...
- C++该typeid和dynamic_cast
1.typeid在没有虚拟函数的(不相关的动态绑定),typeid它只返回操作对象的实际类型 2.typeid涉及到动态联编问题时(使用基类指针p或者引用p操作派生类对象),typeid(p)返回基类 ...
- jquery通过索引获取元素
<!DOCTYPE html><html><head><meta http-equiv="Content-Type" content=&q ...
- linuxC动态内存泄漏追踪方法
C里面没有垃圾回收机制,有时候你申请了动态内存却忘记释放,这就尴尬了(你的程序扮演了强盗角色,有借有还才是好孩子).当你想找出内存泄露的地方时,有的投入海量的代码中,头痛不已.还好GNU C库提供了些 ...
- WPF DataGrid自定义列DataGridTextColumn.ElementStyle和DataGridTemplateColumn.CellTemplate
<Window x:Class="DataGridExam.MainWindow" xmlns="http://schemas.microsoft.c ...
- XML Serialize/Deserialize
using System; using System.Collections.Generic; using System.Globalization; using System.IO; using S ...