Haproxy 构建负载均衡集群
1、HAPROXY简介
 HAProxy提供高可用性、负载均衡以及基于TCP和HTTP应用的代理,支持虚拟主机,它是免费、快速并且可靠的一种负载均衡解决方案。HAProxy特别适用于那些负载特大的web站点,这些站点通常又需要会话保持或七层处理。HAProxy运行在当前的硬件上,完全可以支持数以万计的并发连接。并且它的运行模式使得它可以很简单安全的整合进您当前的架构中,同时可以保护你的web服务器不被暴露到网络上。
HAProxy提供高可用性、负载均衡以及基于TCP和HTTP应用的代理,支持虚拟主机,它是免费、快速并且可靠的一种负载均衡解决方案。HAProxy特别适用于那些负载特大的web站点,这些站点通常又需要会话保持或七层处理。HAProxy运行在当前的硬件上,完全可以支持数以万计的并发连接。并且它的运行模式使得它可以很简单安全的整合进您当前的架构中,同时可以保护你的web服务器不被暴露到网络上。
官网:http://www.haproxy.com
2、HAProxy的特点是:
1、HAProxy支持虚拟主机。
2、HAProxy的优点能够补充Nginx的一些缺点,比如支持Session的保持,Cookie的引导;同时支持通过获取指定的url来检测后端服务器的状态。
3、HAProxy跟LVS类似,本身就只是一款负载均衡软件;单纯从效率上来讲HAProxy会比Nginx有更出色的负载均衡速度,在并发处理上也是优于Nginx的。
4、HAProxy支持TCP协议的负载均衡转发,可以对MySQL读进行负载均衡,对后端的MySQL节点进行检测和负载均衡,可以用LVS+Keepalived对MySQL主从做负载均衡。
5、HAProxy负载均衡策略非常多,HAProxy的负载均衡算法现在具体有如下8种:
① roundrobin,表示简单的轮询,这个不多说,这个是负载均衡基本都具备的;
② static-rr,表示根据权重,建议关注;
③ leastconn,表示最少连接者先处理,建议关注;
④ source,表示根据请求源IP,这个跟Nginx的IP_hash机制类似,我们用其作为解决session问题的一种方法,建议关注;
⑤ ri,表示根据请求的URI;
⑥ rl_param,表示根据请求的URl参数’balance url_param’ requires an URL parameter name;
⑦ hdr(name),表示根据HTTP请求头来锁定每一次HTTP请求;
⑧ rdp-cookie(name),表示根据据cookie(name)来锁定并哈希每一次TCP请求。
3、haproxy 配置中分成五部分内容详解
1、global:参数是进程级的,通常是和操作系统相关。这些参数一般只设置一次,如果配置无误,就不需要再次进行修改
2、defaults:配置默认参数,这些参数可以被用到frontend,backend,Listen组件
3、frontend:接收请求的前端虚拟节点,Frontend可以更加规则直接指定具体使用后端的backend
4、backend:后端服务集群的配置,是真实服务器,一个Backend对应一个或者多个实体服务器
5、Listen Fronted和backend的组合体
4、案例环境:
主机 操作系统 IP地址 主要的软件
----------------------------------------------------------------------------
Haproxy CentOS6.6 x86_64 192.168.200.101 haproxy-1.4.24.tar.gz
Nginx1 CentOS6.6 x86_64 192.168.200.103 nginx-1.6.2.tar.gz
Nginx2 CentOS6.6 x86_64 192.168.200.104 nginx-1.6.2.tar.gz
5、安装配置Haproxy
5.1 安装Haproxy依赖包及源码包编译安装
[root@localhost ~]# yum -y install gcc gcc-c++ make pcre-devel bzip2-devel[root@localhost ~]# tar xf haproxy-1.4.24.tar.gz -C /usr/src/[root@localhost ~]# cd /usr/src/haproxy-1.4.24/[root@localhost haproxy-1.4.24]# make TARGET=linux26 && make install |
5.2 建立haproxy的配置目录及文件
[root@localhost haproxy-1.4.24]# mkdir /etc/haproxy[root@localhost haproxy-1.4.24]# cp examples/haproxy.cfg /etc/haproxy/ |
5.3 haproxy配置项的介绍
###########全局配置#########global log 127.0.0.1 local0 #日志输出配置,所有日志都记录在本机系统日志,通过local0输出 log 127.0.0.1 local1 notice #notice为日志级别,通常有24个级别(error warringinfo debug) nbproc 1 #设置进程数量,通常是CPU核心数或者2倍 pidfile /etc/haproxy/haproxy.pid #haproxy 进程PID文件 maxconn 4096 #最大连接数(需考虑ulimit-n限制 ) #chroot /usr/share/haproxy #chroot运行路径 uid 99 #用户uid gid 99 #用户gid daemon #守护进程模式,以后台服务形式允许 #debug #haproxy 调试级别,建议只在开启单进程的时候调试 ########默认配置############ defaults log global #定义日志为global配置中的日志定义 mode http #默认的模式mode { tcp|http|health },tcp是4层,http是7层,health只会返回OK option httplog #日志类别,采用http日志格式记录日志 #option dontlognull #不记录健康检查日志信息 retries 3 #检查节点服务器失败次数,连续达到三次失败,则认为节点不可用 #option forwardfor #如果后端服务器需要获得客户端真实ip需要配置的参数,可以从Http Header中获得客户端i #option httpclose #每次请求完毕后主动关闭http通道,haproxy不支持keep-alive,只能模拟这种模式的实现 maxconn 4096 #最大连接数 contimeout 5000 #连接超时时间 clitimeout 50000 #客户端超时时间 srvtimeout 50000 #服务器超时时间 #timeout check 2000 #心跳检测超时 #timeout http-keep-alive10s #默认持久连接超时时间 #timeout http-request 10s #默认http请求超时时间 #timeoutqueue 1m #默认队列超时时间 ########统计页面配置######## listen admin_stats bind 0.0.0.0:1080 #设置Frontend和Backend的组合体,监控组的名称,按需要自定义名称 mode http #http的7层模式 option httplog #采用http日志格式 #log 127.0.0.1 local0 err #错误日志记录 maxconn 10 #默认的最大连接数 stats refresh 30s #统计页面自动刷新时间 stats uri /stats #统计页面url stats realm Crushlinux\ Haproxy #统计页面密码框上提示文本 stats auth admin:admin #设置监控页面的用户和密码:admin,可以设置多个用户名 stats hide-version #隐藏统计页面上HAProxy的版本信息 #stats admin if TRUE #设置手工启动/禁用,后端服务器(haproxy-1.4.9以后版本) ########设置haproxy 错误页面##### errorfile 403 /home/haproxy/haproxy/errorfiles/403.http errorfile 500 /home/haproxy/haproxy/errorfiles/500.http errorfile 502 /home/haproxy/haproxy/errorfiles/502.http errorfile 503 /home/haproxy/haproxy/errorfiles/503.http errorfile 504 /home/haproxy/haproxy/errorfiles/504.http ########frontend前端配置############## bibind *:80 #这里建议使用bind *:80的方式,要不然做集群高可用的时候有问题,vip切换到其他机器就不能访问了。 acl web hdr(host) -i www.abc.com #acl后面是规则名称,-i是要访问的域名, acl img hdr(host) -i img.abc.com #如果访问www.abc.com这个域名就分发到下面的webserver 的作用域。 #如果访问img.abc.com.cn就分发到imgserver这个作用域。 use_backend webserver if web use_backend imgserver if img ########backend后端配置############## backend webserver #webserver作用域 mode http balance roundrobin #banlance roundrobin 轮询,balance source 保存session值,支持static-rr,leastconn,first,uri等参数 option httpchk /index.html HTTP/1.0 #健康检查,检测文件,如果分发到后台index.html访问不到就不再分发给它 server web1 192.168.200.103:80 cookie 1 weight 1 check inter 2000 rise 2 fall 3 server web2 192.168.200.104:80 cookie 2 weight 1 check inter 2000 rise 2 fall 3 #cookie 1表示serverid为1,check inter 1500 是检测心跳频率 #rise 2是2次正确认为服务器可用,fall 3是3次失败认为服务器不可用,weight代表权重 backend imgserver mode http option httpchk /index.php balance roundrobin server img01 192.168.200.105:80 check inter 2000 fall 3 server img02 192.168.200.106:80 check inter 2000 fall 3 ########tcp配置################# listen test1 bind 0.0.0.0:90 mode tcp option tcplog #日志类别,采用tcplog maxconn 4086 #log 127.0.0.1 local0 debug server s1 192.168.200.107:80 weight 1 server s2 192.168.200.108:80 weight 1 |
5.4 haproxy 配置文件修改
[root@localhost ~]# vim /etc/haproxy/haproxy.cfg# this config needs haproxy-1.1.28 or haproxy-1.2.1global# log 127.0.0.1 local0# log 127.0.0.1 local1 notice log /dev/log local0 info log /dev/log local0 notice maxconn 4096 uid 99 gid 99 daemondefaults log global mode http option httplog retries 3 maxconn 4096 contimeout 5000 clitimeout 50000 srvtimeout 50000listen webcluster 0.0.0.0:80 option httpchk GET /index.html balance roundrobin server inst1 192.168.200.103:80 check inter 2000 fall 3 server inst1 192.168.200.104:80 check inter 2000 fall 3listen admin_stats bind 0.0.0.0:8000 mode http option httplog maxconn 100 stats refresh 30s stats uri /stats stats realm Crushlinux\ Haproxy stats auth admin:admin stats hide-version |
5.5 准备服务自启动脚本
[root@localhost ~]# cp /usr/src/haproxy-1.4.24/examples/haproxy.init /etc/init.d/haproxy[root@localhost ~]# ln -s /usr/local/sbin/haproxy /usr/sbin/haproxy[root@localhost ~]# chmod +x /etc/init.d/haproxy [root@localhost ~]# /etc/init.d/haproxy startStarting haproxy: [确定] |
6、安装配置Web服务Nginx
6.1 首先搭建Nginx1,
|
1
2
3
4
5
6
7
8
9
10
|
[root@localhost ~]# yum -y install gcc gcc-c++ make pcre-devel zlib-devel openssl-devel[root@localhost ~]# useradd -M -s /sbin/nologin nginx[root@localhost ~]# tar xf nginx-1.6.2.tar.gz -C /usr/src[root@localhost ~]# cd /usr/src/nginx-1.6.2[root@localhost nginx-1.6.2]# ./configure --prefix=/usr/local/nginx --user=nginx --group=nginx && make && make install[root@localhost nginx-1.6.2]# cd /usr/local/nginx/html/[root@localhost html]# echo "server 192.168.200.103" > index.html[root@localhost html]# /usr/local/nginx/sbin/nginx[root@localhost html]# netstat -anpt |grep nginxtcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 4503/nginx |
6.2 搭建nginx2, 同nginx1搭建方式是一样的。
与6.1唯一不同的是:
[root@localhost html]# echo "server 192.168.200.104" > index.html |
注意:nginx服务控制方式
/usr/local/nginx/sbin/nginx 启动服务
killall -s HUP nginx 重新加载服务
killall -s QUIT nginx 退出服务
7、客户端访问测试:
用浏览器打开 http://192.168.200.101
打开一个新的浏览器再次访问 http://192.168.200.101
可以验证两次访问到的结果分别为:
server 192.168.200.103
server 192.168.200.104
8、Haproxy 日志
Haproxy 的日志默认输出到系统的syslog中,为了更好的管理Haproxy 的日志,在生产环境中一般单独定义出来。
8.1 修改Haproxy配置文件中关于日志配置选项,
[root@localhost ~]# vim /etc/haproxy/haproxy.cfg # this config needs haproxy-1.1.28 or haproxy-1.2.1global #log 127.0.0.1 local0 #log 127.0.0.1 local1 notice log /dev/log local0 info log /dev/log local0 notice[root@localhost ~]# service haproxy restartShutting down haproxy: [确定]Starting haproxy: [确定] |
这两行配置放到global选项中,主要是将Haproxy的info和notice日志分别记录到不同的日志文件中
8.2 修改rsyslog配置
为了便于管理,将Haproxy相关的配置独立定义到haproxy.conf 并放到/etc/rsyslog.d/ 下,rsyslog启动时会自动加载此目录下的所有配置文件。
[root@localhost ~]# vim /etc/rsyslog.d/haproxy.confif ($programname == 'haproxy' and $syslogserverity-text == 'info') then -/var/log/haproxy/haproxy-info.log&~if ($programname == 'haproxy' and $syslogserverity-text == 'notice') then -/var/log/haproxy/haproxy-notice.log&~ |
将haproxy的info日志记录到/var/log/haproxy/haproxy-info.log中,将notice日志记录到/var/log/haproxy/haproxy-notice.log中,将notice日志记录到/var/log/haproxy/haproxy-notice
&~ 表示当写入到日志文件后,rsyslog停止处理这个信息,(rainerscript 脚本语言)
重启rsyslog服务
[root@localhost ~]# service rsyslog restart
关闭系统日志记录器: [确定]
启动系统日志记录器: [确定]
8.3 查看日志文件是否创建成功
[root@localhost ~]# ls -l /var/log/haproxy/haproxy-info.log[root@localhost ~]# ls -l /var/log/haproxy/haproxy-notice.logSep 20 23:39:26 localhost haproxy[2674]: 192.168.200.1:51629 [20/Sep/2015:23:38:27.256] web-cluster web-cluster/inst2 0/0/0/1/59740 200 1648 - - CD-- 0/0/0/0/0 0/0 "GET / HTTP/1.1"Sep 20 23:40:06 localhost haproxy[2674]: 192.168.200.1:51693 [20/Sep/2015:23:39:34.423] web-cluster web-cluster/inst2 0/0/0/0/32120 200 580 - - ---- 1/1/1/1/0 0/0 "GET / HTTP/1.1" |
8.4 状态统计功能测试
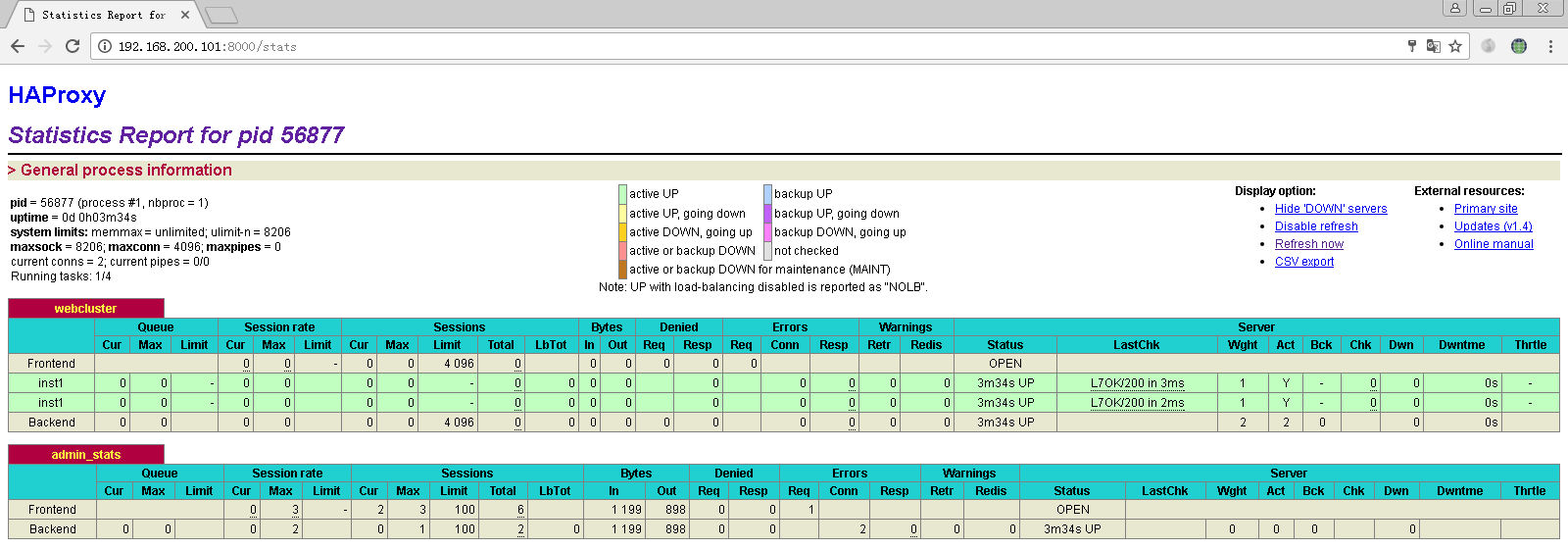
Haproxy 构建负载均衡集群的更多相关文章
- 基于 Haproxy 构建负载均衡集群
1.HAPROXY简介 HAProxy提供高可用性.负载均衡以及基于TCP和HTTP应用的代理,支持虚拟主机,它是免费.快速并且可靠的一种负载均衡解决方案.HAProxy特别适用于那些负载特大的web ...
- 使用haproxy实现负载均衡集群
一.HAProxy概述: HAProxy提供高可用性.负载均衡以及基于TCP和HTTP应用的代理,支持虚拟主机,它是免费.快速并且可靠的一种解决方案.根据官方数据,其最高极限支持10G的并发. HAP ...
- 高性能Linux服务器 第11章 构建高可用的LVS负载均衡集群
高性能Linux服务器 第11章 构建高可用的LVS负载均衡集群 libnet软件包<-依赖-heartbeat(包含ldirectord插件(需要perl-MailTools的rpm包)) l ...
- RabbitMQ(四):使用Docker构建RabbitMQ高可用负载均衡集群
本文使用Docker搭建RabbitMQ集群,然后使用HAProxy做负载均衡,最后使用KeepAlived实现集群高可用,从而搭建起来一个完成了RabbitMQ高可用负载均衡集群.受限于自身条件,本 ...
- Haproxy+Keepalived搭建Weblogic高可用负载均衡集群
配置环境说明: KVM虚拟机配置 用途 数量 IP地址 机器名 虚拟IP地址 硬件 内存3G 系统盘20G cpu 4核 Haproxy keepalived 2台 192.168.1.10 192 ...
- Dubbo入门到精通学习笔记(二十):MyCat在MySQL主从复制的基础上实现读写分离、MyCat 集群部署(HAProxy + MyCat)、MyCat 高可用负载均衡集群Keepalived
文章目录 MyCat在MySQL主从复制的基础上实现读写分离 一.环境 二.依赖课程 三.MyCat 介绍 ( MyCat 官网:http://mycat.org.cn/ ) 四.MyCat 的安装 ...
- 负载均衡集群企业级应用实战—LVS
一.负载均衡集群介绍 1.集群 ① 集群(cluster)技术是一种较新的技术,通过集群技术,可以在付出较低成本的情况下获得在性能.可靠性.灵活性方面的相对较高的收益,其任务调度则是集群系统中的核心技 ...
- 实现基于LVS负载均衡集群的电商网站架构
背景 上一期我们搭建了小米网站,随着业务的发展,网站的访问量越来越大,网站访问量已经从原来的1000QPS,变为3000QPS,网站已经不堪重负,响应缓慢,面对此场景,单纯靠单台LNMP的架构已经无法 ...
- 项目实战:负载均衡集群企业级应用实战—LVS详解
目录 一.负载均衡集群介绍 二.lvs 的介绍 三.LVS负载均衡四种工作模式 1.NAT工作模式 2.DR工作模式 3.TUN工作模式 4.full-nat 工作模式 5.四者的区别 四.LVS i ...
随机推荐
- 【洛谷5298】[PKUWC2018] Minimax(树形DP+线段树合并)
点此看题面 大致题意: 有一棵树,给出每个叶节点的点权(互不相同),非叶节点\(x\)至多有两个子节点,且其点权有\(p_x\)的概率是子节点点权较大值,有\(1-p_x\)的概率是子节点点权较小值. ...
- 模拟ssh远程执行命令
目录 一.服务端 二.客户端 一.服务端 from socket import * import subprocess server = socket(AF_INET, SOCK_STREAM) se ...
- 再一次生产 CPU 高负载排查实践
前言 前几日早上打开邮箱收到一封监控报警邮件:某某 ip 服务器 CPU 负载较高,请研发尽快排查解决,发送时间正好是凌晨. 其实早在去年我也处理过类似的问题,并记录下来:<一次生产 CPU 1 ...
- linux学习之Ubuntu
查看自己的ubuntu版本,输入以下命令(我的都是在root用户下的,在普通用户要使用sudo)第一行的lsb是因为没有安装LSB,安装之后就不会出现这个东西.LSB(Linux Standards ...
- Redis for OPS 04:主从复制
写在前面的话 Redis 的主从其实和 MySQL 类似,更多的还是作为备份的功能存在,在复杂的 Rediis 集群架构中,主从也是不可或缺的. 主从复制 主从复制原理: 1. 从库通过命令连接到主库 ...
- C# 通过反射调用 Func 委托
C# 通过反射调用 Func 委托 Intro 最近我的 NPOI 扩展库增加了,自定义输出的功能,可以自定义一个 Func 委托来设置要导出的内容,详细介绍请查看 https://www.cnblo ...
- 致Python初学者的六点建议
Python是最容易学习的编程语言之一,其语法近似英语.通常,初学者只会遇到一些小麻烦,如强制缩进.在函数中使用self等. 然而,当开始阅读.复制和编辑他人代码时,麻烦就接踵而至了. 这里,我将解释 ...
- python:王思聪究竟上了多少次热搜?
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 朱小五 凹凸玩数据 PS:如有需要Python学习资料的小伙伴可以加 ...
- vuepress1.x入门使用
要点: 1.用npm操作会有各种问题,用yarn取代之; 2.yarn可以用npm全局安装,而npm是node环境自带,node环境去官网下载安装; 3.没有必要全局安装vuepress 操作: 1. ...
- 异常处理类-Throwable源码详解
package java.lang; import java.io.*; /** * * Throwable是所有Error和Exceptiong的父类 * 注意它有四个构造函数: * Throwab ...