多线程与高并发(五)final关键字
final可以修饰变量,方法和类,也就是final使用范围基本涵盖了java每个地方,我们先依次学习final的基础用法,然后再研究final关键字在多线程中的语义。
一、变量
变量,可以分为成员变量以及方法局部变量,我们再依次进行学习。
1.1 成员变量
成员变量可以分为类变量(static修饰的变量)以及实例变量,这两种类型的变量赋初值的时机是不同的,类变量可以在声明变量的时候直接赋初值或者在静态代码块中给类变量赋初值,实例变量可以在声明变量的时候给实例变量赋初值,在非静态初始化块中以及构造器中赋初值。
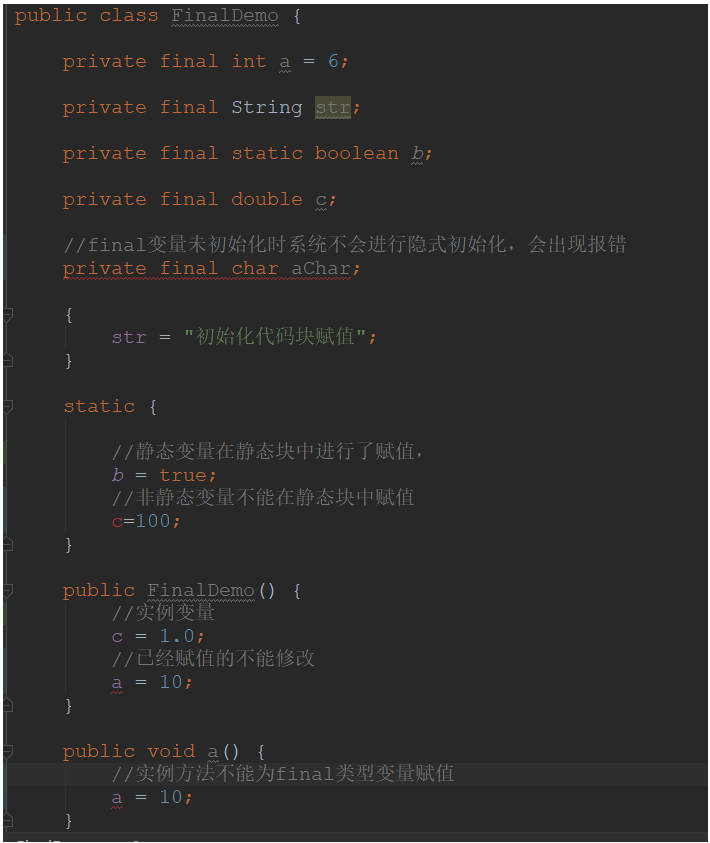
这里面要注意,在final变量未初始化时系统不会进行隐式初始化,会出现报错。
归纳总结:
类变量:必须要在静态初始化块中指定初始值或者声明该类变量时指定初始值,而且只能在这两个地方之一进行指定;
实例变量:必要要在非静态初始化块,声明该实例变量或者在构造器中指定初始值,而且只能在这三个地方进行指定。
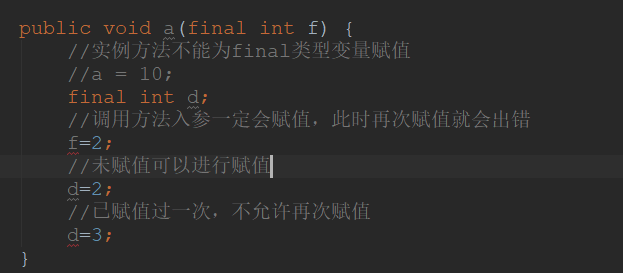
1.2 局部变量
对于局部变量使用final,理解就更简单,局部变量的仅有一次赋值,一旦赋值之后再次赋值就会出错:
1.3 基本数据类型 VS 引用数据类型
上面讨论的基本都是基本数据类型,基本数据类型一旦赋值之后,就不允许修改,那引用类型呢?
public class FinalDemo1 {
//在声明final实例成员变量时进行赋值
private final static Person person = new Person(24, 170);
public static void main(String[] args) {
//对final引用数据类型person进行更改
person.age = 22;
Person p = new Person(50, 160);
//对引用类型变量直接修改会报错
//person = p;
System.out.println(person.toString());
}
static class Person {
private int age;
private int height;
public Person(int age, int height) {
this.age = age;
this.height = height;
}
@Override
public String toString() {
return "Person{" +
"age=" + age +
", height=" + height +
'}';
}
}
}
上面的例子可以看出,我们可以对引用数据类型的属性进行更改,但是不能直接对引用类型的变量进行修改,
final只保证这个引用类型变量所引用的地址不会发生改变
二、方法
当一个方法被final关键字修饰时,说明此方法不能被子类重写
public class FinalDemoParent {
//final修饰的方法不能被子类重载
public final void test() {
}
}
子类不能重写该方法
在Object中,getClass()方法就是final的,我们就不能重写该方法,但是hashCode()方法就不是被final所修饰的,我们就可以重写hashCode()方法。
三、类
当一个类被final修饰时,表示该类是不能被子类继承的,当我们想避免由于子类继承重写父类的方法和改变父类属性,带来一定的安全隐患时,就可以使用final修饰。
扩展思考,为什么String类为什么是final的?先看下源码

final修饰的String,代表了String的不可继承性,final修饰的char[]代表了被存储的数据不可更改性。但是:我们知道引用类型的不可变仅仅是引用地址不可变,不代表了数组本身不会变,这个时候,起作用的还有private,正是因为两者保证了String的不可变性。
那么为什么保证String不可变呢,因为只有当字符串是不可变的,字符串池才有可能实现。字符串池的实现可以在运行时节约很多heap空间,因为不同的字符串变量都指向池中的同一个字符串。但如果字符串是可变的,那么字符串池将不能实现,因为这样的话,如果变量改变了它的值,那么其它指向这个值的变量的值也会一起改变。
因为字符串是不可变的,所以是多线程安全的,同一个字符串实例可以被多个线程共享。这样便不用因为线程安全问题而使用同步。字符串自己便是线程安全的。
因为字符串是不可变的,所以在它创建的时候HashCode就被缓存了,不需要重新计算。这就使得字符串很适合作为Map中的键,字符串的处理速度要快过其它的键对象。这就是HashMap中的键往往都使用字符串。
四、final的重排序规则
对于final域,编译器和处理器要遵守两个重排序规则。
- 在构造函数内对一个final域的写入,与随后把这个被构造对象的引用赋值给一个引用变量,这两个操作之间不能重排序。
- 初次读一个包含final域的对象的引用,与随后初次读这个final域,这两个操作之间不能重排序。
我们通过下面的例子来看:
public class FinalDemo3 {
private int i;// 普通变量
private final int j;// final变量
private static FinalDemo3 obj;
public FinalDemo3() { // 构造函数
i = 1; // 写普通域
j = 2;// 写final域
}
public static void writer() {// 写线程A执行
obj = new FinalDemo3();
}
public static void reader() {// 读线程B执行
FinalDemo3 object = obj; // 读对象引用
int a = object.i; // 读普通域
int b = object.j; // 读final域
}
}
这里假设一个线程A执行writer()方法,随后另一个线程B执行reader()方法。下面我们通过这两个线程的交互来说明这两个规则。
4.1 写final域的重排序规则
写final域的重排序规则禁止对final域的写重排序到构造函数之外,这个规则的实现主要包含了两个方面:
JMM禁止编译器把final域的写重排序到构造函数之外;
编译器会在final域写之后,构造函数return之前,插入一个storestore屏障。这个屏障可以禁止处理器把final域的写重排序到构造函数之外。
我们分析writer()方法,writer方法虽然只有一行代码,但其实是做了两件事情的:
构造了一个FinalDemo3对象;
把这个对象赋值给成员变量obj。
我们先假设线程B读对象引用与读对象的成员域之间没有重排序,那以下是一种可能的执行时序:
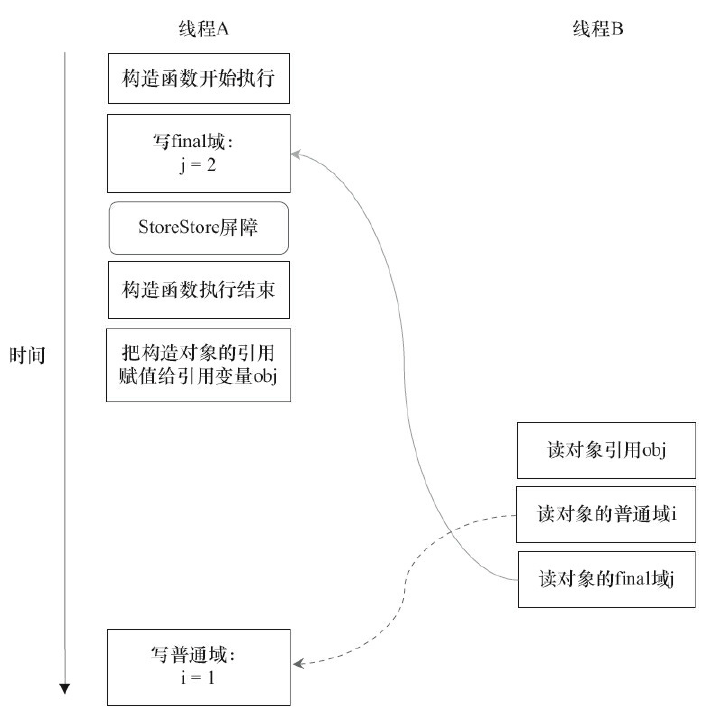
这里可以看出, 写普通域的操作被编译器重排序到了构造函数之外,读线程B错误地读取了普通变量i初始化之前的值。而写final域的操作,被写final域的重排序规则“限定”在了构造函数之内,读线程B正确地读取了final变量初始化之后的值。
写final域的重排序规则可以确保:在对象引用为任意线程可见之前,对象的final域已经被正确初始化过了,而普通域不具有这个保障。
要得到这个效果,还需要一个保证:在构造函数内部,不能让这个被构造对象的引用为其他线程所见,也就是对象引用不能在构造函数中“逸出”。
4.2 读final域的重排序规则
读final域的重排序规则是,在一个线程中,初次读对象引用与初次读该对象包含的final域,JMM禁止处理器重排序这两个操作(注意,这个规则仅仅针对处理器)。编译器会在读final域操作的前面插入一个LoadLoad屏障。
初次读对象引用与初次读该对象包含的final域,这两个操作之间存在间接依赖关系。由于编译器遵守间接依赖关系,因此编译器不会重排序这两个操作。大多数处理器也会遵守间接依赖,也不会重排序这两个操作。但有少数处理器允许对存在间接依赖关系的操作做重排序(比如alpha处理器),这个规则就是专门用来针对这种处理器的。
reader()方法包含3个操作。
初次读引用变量obj。
初次读引用变量obj指向对象的普通域j。
初次读引用变量obj指向对象的final域i。
假设写线程A没有发生任何重排序,同时程序在不遵守间接依赖的处理器上执行,那以下一种可能的执行时序:
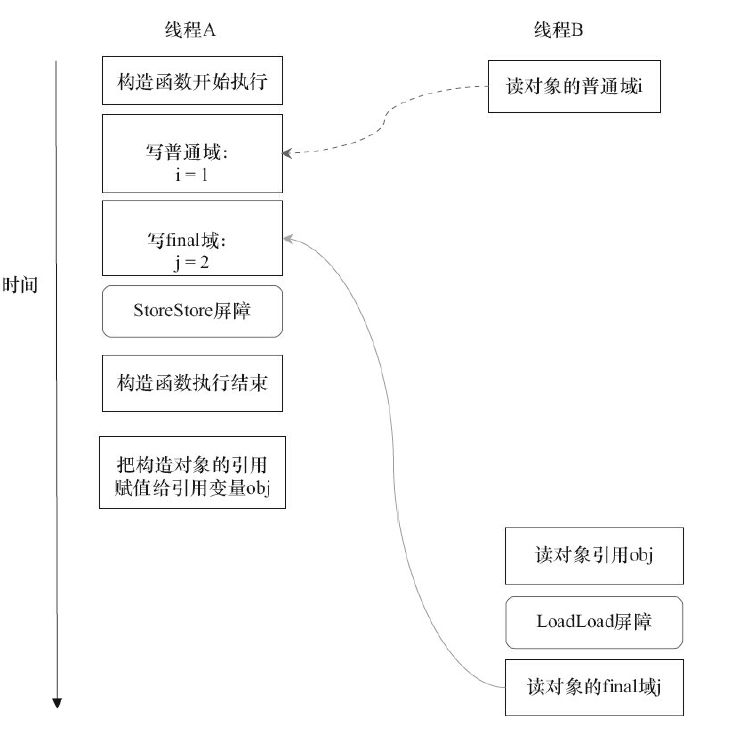
读对象的普通域的操作被处理器重排序到读对象引用之前。读普通域时,该域还没有被写线程A写入,这是一个错误的读取操作。而读final域的重排序规则会把读对象final域的操作“限定”在读对象引用之后,此时该final域已经被A线程初始化过了,这是一个正确的读取操作。
读final域的重排序规则可以确保:在读一个对象的final域之前,一定会先读包含这个final域的对象的引用。在这个示例程序中,如果该引用不为null,那么引用对象的final域一定已经被A线程初始化过了。
4.3 final域为引用类型
上面看到的final域是基础数据类型,如果final域是引用类型,将会有什么效果?请看下列示例代码:
public class FinalDemo4 {
final int[] intArray; // final是引用类型
static FinalDemo4 obj;
public FinalDemo4() { // 构造函数
intArray = new int[1]; //
intArray[0] = 1; //
}
public static void writerOne() { // 写线程A执行
obj = new FinalDemo4(); //
}
public static void writerTwo() { // 写线程B执行
obj.intArray[0] = 2; //
}
public static void reader() { // 读线程C执行
if (obj != null) { //
int temp1 = obj.intArray[0]; //
}
}
}
final域为一个引用类型,它引用一个int型的数组对象。对于引用类型,写final域的重排序规则对编译器和处理器增加了如下约束:在构造函数内对一个final引用的对象的成员域的写入,与随后在构造函数外把这个被构造对象的引用赋值给一个引用变量,这两个操作之间不能重排序。
对上面的示例程序,假设首先线程A执行writerOne()方法,执行完后线程B执行writerTwo()方法,执行完后线程C执行reader()方法。那下面就可能是一种时序:
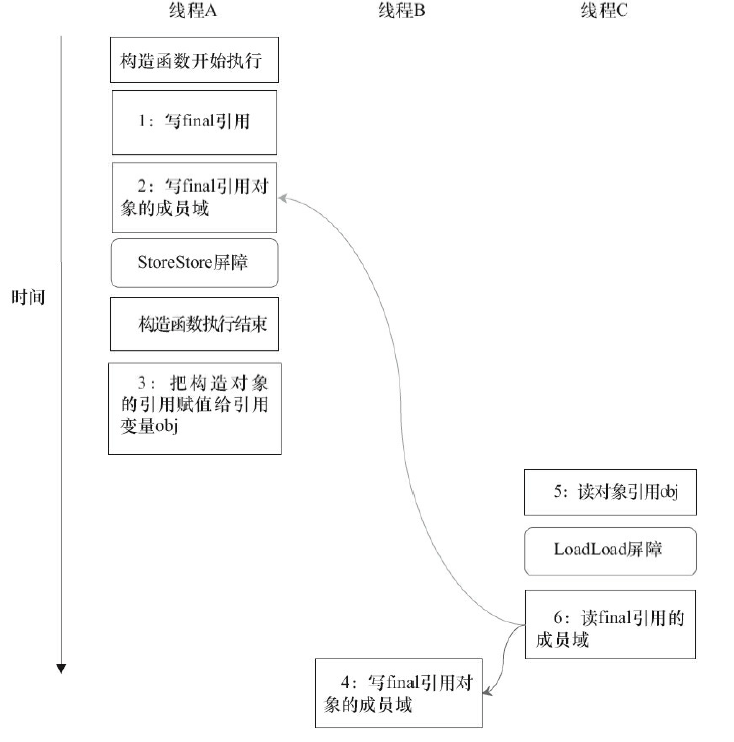
1是对final域的写入,2是对这个final域引用的对象的成员域的写入,3是把被构造的对象的引用赋值给某个引用变量。这里除了前面提到的1不能和3重排序外,2和3也不能重排序。 JMM可以确保读线程C至少能看到写线程A在构造函数中对final引用对象的成员域的写入。即C至少能看到数组下标0的值为1。而写线程B对数组元素的写入,读线程C可能看得到,也可能看不到。JMM不保证线程B的写入对读线程C可见,因为写线程B和读线程C之间存在数据竞争,此时的执行结果不可预知。 如果想要确保读线程C看到写线程B对数组元素的写入,写线程B和读线程C之间需要使用同步原语(lock或volatile)来确保内存可见性。
多线程与高并发(五)final关键字的更多相关文章
- 多线程与高并发(三)synchronized关键字
上一篇中学习了线程安全相关的知识,知道了线程安全问题主要来自JMM的设计,集中在主内存和线程的工作内存而导致的内存可见性问题,及重排序导致的问题.上一篇也提到共享数据会出现可见性和竞争现象,如果多线程 ...
- 多线程与高并发(五) Lock
之前学习了如何使用synchronized关键字来实现同步访问,Java SE 5之后,并发包中新增了Lock接口(以及相关实现类)用来实现锁功能,它提供了与synchronized关键字类似的同步功 ...
- 多线程与高并发(四)volatile关键字
上一篇学习了synchronized的关键字,synchronized是阻塞式同步,在线程竞争激烈的情况下会升级为重量级锁,而volatile是一个轻量级的同步机制. 前面学习了Java的内存模型,知 ...
- 多线程与高并发(一)—— 自顶向下理解Synchronized实现原理
一. 什么是锁? 在多线程中,多个线程同时对某一个资源进行访问,容易出现数据不一致问题,为保证并发安全,通常会采取线程互斥的手段对线程进行访问限制,这个互斥的手段就可以称为锁.锁的本质是状态+指针,当 ...
- 互联网大厂高频重点面试题 (第2季)JUC多线程及高并发
本期内容包括 JUC多线程并发.JVM和GC等目前大厂笔试中会考.面试中会问.工作中会用的高频难点知识.斩offer.拿高薪.跳槽神器,对标阿里P6的<尚硅谷_互联网大厂高频重点面试题(第2季) ...
- 使用Redis中间件解决商品秒杀活动中出现的超卖问题(使用Java多线程模拟高并发环境)
一.引入Jedis依赖 可以新建Spring或Maven工程,在pom文件中引入Jedis依赖: <dependency> <groupId>redis.clients< ...
- java后端知识点梳理——多线程与高并发
进程与线程 进程是一个"执行中的程序",是系统进行资源分配和调度的一个独立单位 线程是进程的一个实体,一个进程中一般拥有多个线程. 线程和进程的区别 进程是操作系统分配资源的最小单 ...
- 一篇博客带你轻松应对java面试中的多线程与高并发
1. Java线程的创建方式 (1)继承thread类 thread类本质是实现了runnable接口的一个实例,代表线程的一个实例.启动线程的方式start方法.start是一个本地方法,执行后,执 ...
- Java基础(五) final关键字浅析
前面在讲解String时提到了final关键字,本文将对final关键字进行解析. static和final是两个我们必须掌握的关键字.不同于其他关键字,他们都有多种用法,而且在一定环境下使用,可以提 ...
随机推荐
- Qt 5.6.2 静态编译(VS2013 x86 target xp openssl icu webkit)
在去年4月份的时候,我写过一篇动态编译Qt5.6.0的文章,当时是为了解决webkit不能在winxp下面跑的问题,动态编译有一个缺点,就是发布的时候,要携带一大堆dll,使安装包的体积增大.而静态编 ...
- Ionic Framework 4 介绍
Ionic Framework 4是一个开源UI工具包,用于使用Web技术(HTML,CSS和JavaScript)构建高性能的高质量移动和桌面应用程序.Ionic Framework专注于前端用户体 ...
- CentOS7 Vim自动补全插件----YouCompleteMe安装与配置
最近刚装了新系统CentOS7,想要把编码环境配置一下,使用Vim编写程序少不了使用自动补全插件,我以前用的是neocomplcache+code_complete+omnicppcomplete.但 ...
- Zookeeper详解-Cli(五)
ZooKeeper命令行界面(CLI)用于与ZooKeeper集合进行交互以进行开发.它有助于调试和解决不同的选项. 要执行ZooKeeper CLI操作,首先打开ZooKeeper服务器(“bin/ ...
- Hadoop 学习之路(三)—— 分布式计算框架 MapReduce
一.MapReduce概述 Hadoop MapReduce是一个分布式计算框架,用于编写批处理应用程序.编写好的程序可以提交到Hadoop集群上用于并行处理大规模的数据集. MapReduce作业通 ...
- K8s集群部署(三)------ Node节点部署
之前的docker和etcd已经部署好了,现在node节点要部署二个服务:kubelet.kube-proxy. 部署kubelet(Master 节点操作) 1.二进制包准备 [root@k8s-m ...
- shell写的俄罗斯方块
共享一下. #!/bin/bash # Tetris Game # xhchen<[email]xhchen@winbond.com.tw[/email]> #APP declaratio ...
- python 基础学习笔记(1)
声明: 本人是在校学生,自学python,也是刚刚开始学习,写博客纯属为了让自己整理知识点和关键内容,当然也希望可以通过我都博客来提醒一些零基础学习python的人们.若有什么不对,请大家及时指出, ...
- 小白开学Asp.Net Core 《五》
小白开学Asp.Net Core<五> —— 使用.Net Core MVC Filter 一.简介 今天在项目(https:/ ...
- Hive入门(三)分桶
1 什么是分桶 上一篇说到了分区,分区中的数据可以被进一步拆分成桶,bucket.不同于分区对列直接进行拆分,桶往往使用列的哈希值进行数据采样.在分区数量过于庞大以至于可能导致文件系统崩溃时,建议使用 ...