每天3分钟操作系统修炼秘籍(13):两个缓冲空间Kernel Buffer和IO Buffer
两个缓冲空间:kernel buffer和io buffer
先看一张图,稍后将围绕这张图展开描述。图中的fd table、open file table以及两个inode table都可以不用理解,只需要知道它们体现出来的文件描述符和磁盘文件之间的对应关系:文件描述符fd(例如图中的fd=3)是对应磁盘上文件的。
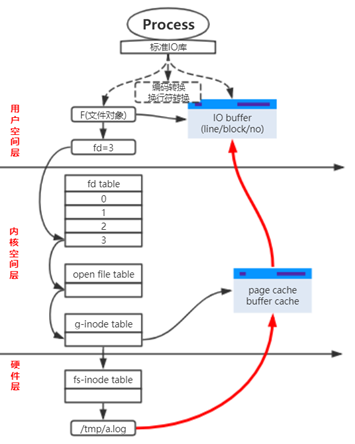
在Linux下,我们经常会在IO操作时不可避免的涉及到文件描述符,因为Linux下的所有IO操作都是通过文件描述符来完成的。但是,文件描述符是一个非常底层的概念,通过它操作的数据,都是二进制数据,所以通过文件描述符完成IO的模式通常也称为裸IO(Raw IO)。而且,直接通过底层的文件描述符进行编程会比较麻烦,因为是二进制数据,它缺少很多功能,比如无法指定编码,无法指定换行符(换行符有多种:\n、\n\r、\r)等等。注意fd是用户空间的,它仅仅是一个数值而已,并不是想象中感觉比较底层就在内核空间。
所以,现代高级语言(比如C、Python、Java、Golang)都提供了比文件描述符更高一层次的标准IO库,比如C的标准IO库是stdio,Python的标准IO库是IO模块,等等。使用这些标准IO库中的函数进行IO操作时,都会使用比文件描述符更高一层次的对象,例如C中称为IO流(io stream),其它面向对象的语言中一般称为IO对象,为了方便说明,这里统称为IO对象。上图中的F就是文件对象。
标准IO库可以看作是文件描述符的更高层次的封装,提供了比文件描述符操作IO更多的功能。例如,可以在IO对象上指定编码、指定换行符,此外还在用户空间提供了一个标准IO库的缓冲空间,通常可称为stdio buffer或IO buffer,而这些功能在文件描述符上都是没有的。另外,标准IO库既然是高层封装,当然也会提供用户不使用这些功能(比如不使用IO Buffer),而是直接使用文件描述符,那么这时候的文件对象就相当于是文件描述符了,这时候的IO操作模式也就是裸IO模式。

所有从硬件读取或写入到硬件的数据,默认都会经过操作系统维护的这个Kernel Buffer。正如上图中描述的是读数据过程。
例如,cat进程想要读取a.log文件,cat进程是用户空间进程,它自身没有权限打开文件以及读文件数据,它只能通过系统调用的方式陷入内核,请求操作系统帮助读取数据,操作系统读取数据后会将数据放入到page cache(刚才已说明,对于普通文件维护的Kernel buffer称为page cache或buffer cache)。然后还要将内核空间page cache中的数据拷贝到用户空间的IO Buffer缓冲空间(因为cat程序的源代码中使用了标准IO库stdio),然后cat进程从自己的IO Buffer中读取数据。这就是整个读数据的过程。
需要注意的是,虽然这两段缓冲空间都在内存中,但仍然有拷贝操作,因为内核的内存空间和用户进程的虚拟内存空间是隔离的,用户空间进程没有权限访问到内核空间的内存,但是内核具有最高权限,允许访问任何内存地址。换句话说,在将Kernel Buffer的数据拷贝到IO Buffer空间的过程中,需要陷入到内核,OS需要掌控CPU。
此外,Linux也提供了所谓的直接IO模式,只需使用一个称为O_DIRECT的标记即可,这时会绕过Kernel Buffer,直接将硬件数据拷贝到用户空间。虽然看上去直接IO少了一个层次的参与感觉性能会更优秀,但实际上并非如此,操作系统为内核缓冲空间做了非常多的优化,使得并不会因此而降低性能。最典型且常见的一个优化是预读功能,它表示在读数据时,会比所请求要读取的数据量多读一点放入到Kernel Buffer,这样在下次读取接下来的一段数据时可以直接从Kernel Buffer中取数据,而无需再和硬件IO交互。所以,使用直接IO模式的场景是非常少的,一般只会在自带了完整缓冲模型的大型软件(比如数据库系统)上可能会使用直接IO模式。
上面所描述的都是读操作,关于写操作,这里不再多花篇幅去描述,整体过程和读是类似的,都会经过IO Buffer和Kernel Buffer,只是其中一些细节有所不同,如果感兴趣,可以阅读《Linux/Unix系统编程手册》的第13章。
每天3分钟操作系统修炼秘籍(13):两个缓冲空间Kernel Buffer和IO Buffer的更多相关文章
- 每天3分钟操作系统修炼秘籍(14):IO操作和DMA、RDMA
点我查看秘籍连载 I/O操作和DMA.RDMA 用户进程想要执行IO操作时(例如想要读磁盘数据.向磁盘写数据.读键盘的输入等等),由于用户进程工作在用户模式下,它没有执行这些操作的权限,只能通过发起对 ...
- 每天3分钟操作系统修炼秘籍(12):OOM和swap分区
点我查看秘籍连载 OOM和swap分区 进程的虚拟内存空间是映射到整个物理内存空间的,所以在进程自身看来它拥有了整个物理内存,它也能使用整个物理内存,只需在使用的时候请求操作系统帮忙分配更多空间即可. ...
- 每天3分钟操作系统修炼秘籍(6):Idle进程
点我查看秘籍连载 CPU的归属:Idle进程 操作系统并不总是繁忙.例如个人PC上任务比较轻,多数时候都无法充分利用CPU,导致CPU处于空闲状态.但CPU既然通电了,它就得运行,那么在它没有任务需要 ...
- Vim修炼秘籍之语法篇
前言 少年,我看你骨骼精奇,是万中无一的武学奇才,维护世界和平就靠你了,我这有本秘籍<Vim修炼秘籍>,见与你有缘,就十块卖给你了! 如果你是一名 Vimer,那么恭喜你,你的 Vim 技 ...
- MySQL Innodb的两种表空间方式
要说表空间,MySQL的表空间管理远远说不上完善.换句话说,事实上MySQL根本没有真正意义上的表空间管理.MySQL的Innodb包含两种表空间文件模式,默认的共享表空间和每个表分离的独立表空间.只 ...
- 在编写wpf界面时候中出现如下错误: 类型引用不明确。至少有两个名称空间(“System.Windows”和“System.Windows”)中已出现名为“VisualStateManager”的类型。请考虑调整程序集 XmlnsDefinition 特性。
wpf中类型引用不明确.至少有两个名称空间(“System.Windows”和“System.Windows”)中已出现名为“VisualState 你是不是用了WPFToolKit?如果是的,那原因 ...
- java io系列13之 BufferedOutputStream(缓冲输出流)的认知、源码和示例
本章内容包括3个部分:BufferedOutputStream介绍,BufferedOutputStream源码,以及BufferedOutputStream使用示例. 转载请注明出处:http:// ...
- 9.11排序与查找(一)——给定两个排序后的数组A和B,当中A的末端有足够的缓冲空间容纳B。将B合并入A并排序
/** * 功能:给定两个排序后的数组A和B,当中A的末端有足够的缓冲空间容纳B.将B合并入A并排序. */ /** * 问题:假设将元素插入数组A的前端,就必须将原有的元素向后移动,以腾出空间. ...
- 操作系统开发系列—13.g.操作系统的系统调用 ●
在我们的操作系统中,已经存在的3个进程是运行在ring1上的,它们已经不能任意地使用某些指令,不能访问某些权限更高的内存区域,但如果一项任务需要这些使用指令或者内存区域时,只能通过系统调用来实现,它是 ...
随机推荐
- Python之装饰器(二)
以前你有没有这样一段经历:很久之前你写过一个函数,现在你突然有了个想法就是你想看看,以前那个函数在你数据集上的运行时间是多少,这时候你可以修改之前代码为它加上计时的功能,但是这样的话是不是还要大体读读 ...
- BeetleX服务网关之服务发现与泛域名路由
在新版本的服务网关中提供了服务发现和泛域名路由解决功能,服务发现可以在无须配置的情况下实现服务自动注册到网关中解脱对服务配置的繁琐工作:而泛域名路由则可以针对不同的域名制定不同的负载规则. 使用con ...
- 聊聊缓存淘汰算法-LRU 实现原理
前言 我们常用缓存提升数据查询速度,由于缓存容量有限,当缓存容量到达上限,就需要删除部分数据挪出空间,这样新数据才可以添加进来.缓存数据不能随机删除,一般情况下我们需要根据某种算法删除缓存数据.常用淘 ...
- 【MongoDB详细使用教程】五、MongoDB的数据库管理
目录 1.数据库安全 1.1.创建管理员账号和密码 1.2.设置服务状态为需要验证用户 1.3.创建用户账户和密码 1.4.忘记密码/修改密码 2.主从服务器 2.1.创建服务器目录,用于分别存放主从 ...
- web常用知识
Html 1.打电话,发短信和发邮件 <a href="tel:0755-10086">打电话给:0755-10086</a> <a href=&qu ...
- ArangoDB简单实例介绍
数据介绍: 2008美国国内航班数据 airports.csv flights.csv 数据下载地址:https://www.arangodb.com/graphcourse_demodata_ara ...
- python实现输入任意一个大写字母生成金字塔的示例
输入任意一个大写字母,生成金字塔图形 def GoldTa(input): L = [chr(i) for i in range(65, 91)] # 大写字母A--Z idA = 65 # 从A开始 ...
- [apue] 如何处理 tcp 紧急数据(OOB)?
在上大学的时候,我们可能就听说了OOB(Out Of Band 带外数据,又称紧急数据)这个概念. 当时老师给的解释就是在当前处理的数据流之外的数据,用于紧急的情况.然后就没有然后了…… 毕业这么多年 ...
- access技巧 access源码 这里都可找到哦
这个网站不错,有很多access技巧 access源码 还有access公开课 access免费培训 access教程 大家要多看看哦: http://www.office-cn.net access ...
- MySql数据库优化必须注意的四个细节(方法)
MySQL 数据库性能的优化是 MySQL 数据库发展的必经之路, MySQL 数据库性能的优化也是 MySQL 数据库前进的见证,下文中将从从4个方面给出了 MySQL 数据库性能优化的方法. 1. ...