Pytorch Dataset和Dataloader 学习笔记(二)
Pytorch Dataset & Dataloader
Pytorch框架下的工具包中,提供了数据处理的两个重要接口,Dataset 和 Dataloader,能够方便的使用和加载自己的数据集。
数据的预处理,加载数据并转化为tensor格式
使用Dataset构建自己的数据
使用Dataloader装载数据
【数据】链接:https://pan.baidu.com/s/1gdWFuUakuslj-EKyfyQYLA
提取码:10d4
复制这段内容后打开百度网盘手机App,操作更方便哦
数据的预处理与加载
import torch
import numpy as np
from torch.utils.data import DataLoader, Dataset
## 1. 数据的处理,加载转化为tensor
x_data = 'X.csv'
y_data = 'y.csv'
x = np.loadtxt(x_data, delimiter=' ', dtype=np.float32)
y = np.loadtxt(y_data, delimiter=' ', dtype=np.float32).reshape(-1, 1)
x = torch.from_numpy(x[:, :])
y = torch.from_numpy(y[:, :])
torch.utils.data.Dataset
Dataset抽象类,用于包装构建自己的数据集,该类包括三个基本的方法:
- __init__ 进行数据的读取操作
- __getitem__ 数据集需支持索引访问
- __len__ 返回数据集的长度
## 2. 构建自己的数据集
class Mydataset(Dataset):
def __init__(self, train_data, label_data):
self.train = train_data
self.label = label_data
self.len = len(train_data)
def __getitem__(self, item):
return self.train[item], self.label[item]
def __len__(self):
return self.len
dataset = Mydataset(x, y)
samples = dataset.__len__()
print("总样本数:",samples)
torch.utils.data.Dataloader
Dataloader抽象类,构建可迭代的数据集装载器,从Dataset实例对象中按batch_size装载数据以送入训练。包含以下几个参数:
- batch_size 批大小
- shuffle 装载的batch是否乱序
- drop_last 不足batch大小的最后部分是否舍去
- num_workers 是否多进程读取数据
## 3. 创建数据集装载器
train_loader = DataLoader(dataset=dataset,
batch_size=64,
shuffle=True,
drop_last=True,
num_workers=4)
测试
if __name__ == "__main__":
iteration = 0
for train_data, train_label in train_loader:
print("x: ", train_data, "\ny: ", train_label)
iteration += 1
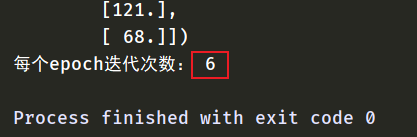
### 这里dataloader中drop_last为True,所以迭代次数应为 samples/batch_size = 6
print("每个epoch迭代次数:",iteration)

完整代码
import torch
import numpy as np
from torch.utils.data import DataLoader, Dataset
## 1. 数据的处理,加载转化为tensor
x_data = 'X.csv'
y_data = 'y.csv'
x = np.loadtxt(x_data, delimiter=' ', dtype=np.float32)
y = np.loadtxt(y_data, delimiter=' ', dtype=np.float32).reshape(-1, 1)
x = torch.from_numpy(x[:, :])
y = torch.from_numpy(y[:, :])
## 2. 构建自己的数据集
class Mydataset(Dataset):
def __init__(self, train_data, label_data):
self.train = train_data
self.label = label_data
self.len = len(train_data)
def __getitem__(self, item):
return self.train[item], self.label[item]
def __len__(self):
return self.len
dataset = Mydataset(x, y)
## 3. 创建数据集装载器
train_loader = DataLoader(dataset=dataset,
batch_size=64,
shuffle=True,
drop_last=True,
num_workers=4)
if __name__ == "__main__":
iteration = 0
samples = dataset.__len__()
print("总样本数:", samples)
for train_data, train_label in train_loader:
print("x: ", train_data, "\ny: ", train_label)
iteration += 1
### 这里dataloader中drop_last为True,所以迭代次数应为 samples/batch_size = 6
print("每个epoch迭代次数:",iteration)
Pytorch Dataset和Dataloader 学习笔记(二)的更多相关文章
- amazeui学习笔记二(进阶开发4)--JavaScript规范Rules
amazeui学习笔记二(进阶开发4)--JavaScript规范Rules 一.总结 1.注释规范总原则: As short as possible(如无必要,勿增注释):尽量提高代码本身的清晰性. ...
- 微信小程序学习笔记二 数据绑定 + 事件绑定
微信小程序学习笔记二 1. 小程序特点概述 没有DOM 组件化开发: 具备特定功能效果的代码集合 体积小, 单个压缩包体积不能大于2M, 否则无法上线 小程序的四个重要的文件 *js *.wxml - ...
- WPF的Binding学习笔记(二)
原文: http://www.cnblogs.com/pasoraku/archive/2012/10/25/2738428.htmlWPF的Binding学习笔记(二) 上次学了点点Binding的 ...
- AJax 学习笔记二(onreadystatechange的作用)
AJax 学习笔记二(onreadystatechange的作用) 当发送一个请求后,客户端无法确定什么时候会完成这个请求,所以需要用事件机制来捕获请求的状态XMLHttpRequest对象提供了on ...
- [Firefly引擎][学习笔记二][已完结]卡牌游戏开发模型的设计
源地址:http://bbs.9miao.com/thread-44603-1-1.html 在此补充一下Socket的验证机制:socket登陆验证.会采用session会话超时的机制做心跳接口验证 ...
- JMX学习笔记(二)-Notification
Notification通知,也可理解为消息,有通知,必然有发送通知的广播,JMX这里采用了一种订阅的方式,类似于观察者模式,注册一个观察者到广播里,当有通知时,广播通过调用观察者,逐一通知. 这里写 ...
- java之jvm学习笔记二(类装载器的体系结构)
java的class只在需要的时候才内转载入内存,并由java虚拟机的执行引擎来执行,而执行引擎从总的来说主要的执行方式分为四种, 第一种,一次性解释代码,也就是当字节码转载到内存后,每次需要都会重新 ...
- Java IO学习笔记二
Java IO学习笔记二 流的概念 在程序中所有的数据都是以流的方式进行传输或保存的,程序需要数据的时候要使用输入流读取数据,而当程序需要将一些数据保存起来的时候,就要使用输出流完成. 程序中的输入输 ...
- 《SQL必知必会》学习笔记二)
<SQL必知必会>学习笔记(二) 咱们接着上一篇的内容继续.这一篇主要回顾子查询,联合查询,复制表这三类内容. 上一部分基本上都是简单的Select查询,即从单个数据库表中检索数据的单条语 ...
随机推荐
- <JVM下篇:性能监控与调优篇>05-分析GC日志
笔记来源:尚硅谷JVM全套教程,百万播放,全网巅峰(宋红康详解java虚拟机) 同步更新:https://gitee.com/vectorx/NOTE_JVM https://codechina.cs ...
- PowerDesigner16安装和使用
安装 安装参考链接:PowerDesigner安装教程 因为这个博主已经操作的很详细了,这边就不做过多的赘述. 使用 新建模型 选择物理模型 调出面板Palette 建表 最终的效果(一般不在数据库层 ...
- 【死磕JVM】用Arthas排查JVM内存 真爽!我从小用到大
Arthas是啥 当我们系统遇到JVM或者内存溢出等问题的时候,如何对我们的程序进行有效的监控和排查,就发现了几个比较常用的工具,比如JDK自带的 jconsole.jvisualvm还有一个最好用的 ...
- 普里姆算法(Prim)邻接矩阵法
算法代码 C#代码 using System; namespace Prim { class Program { static void Main(string[] args) { int numbe ...
- 2Spring对象创建小结
Spring的对象创建 Spring学习笔记 周芋杉2021/5/15 原理:工厂设计模式,通过反射创建对象. Spring工厂分类 非web环境:ClassPathXmlApplicationCon ...
- [bug] conda:Segmentation fault (core dumped)
参考 https://www.jianshu.com/p/5e230ef8a14d
- Win10开启移动热点
Win10开启移动热点 禁用 无线网卡 启动 无线网卡
- Python socket 编程实验
实验内容 1.编写一个基于UDP协议的客户机与服务器程序,实现相互通讯. 2.编写一个基于TCP协议的客户机与服务器程序,实现相互通讯. 3.捕获以上两种通讯的数据包,使用Wireshark进行分析, ...
- Docker Swarm(九)资源限制
资源限制 docker run 針對限制容器資源有許多設置選項,但Swarm中的 docker service 是另一回事,目前只有cpu和memory的選項可以操作. 如果 docker 找不到足夠 ...
- 049.Python前端javascript
一 JavaScript概述 1.1 JavaScript的历史 1992年Nombas开发出C-minus-minus(C--)的嵌入式脚本语言(最初绑定在CEnvi软件中).后将其改名Script ...