Searching the Web UVA - 1597
The word “search engine” may not be strange to you. Generally speaking, a search engine searches the web pages available in the Internet, extracts and organizes the information and responds to users’ queries with the most relevant pages. World famous search engines, like GOOGLE, have become very important tools for us to use when we visit the web. Such conversations are now common in our daily life:
“What does the word like ∗ ∗ ∗ ∗ ∗∗ mean?”
“Um. . . I am not sure, just google it.”
In this problem, you are required to construct a small search engine. Sounds impossible, does it? Don’t worry, here is a tutorial teaching you how to organize large collection of texts efficiently and respond to queries quickly step by step. You don’t need to worry about the fetching process of web pages, all the web pages are provided to you in text format as the input data. Besides, a lot of queries are also provided to validate your system.
Modern search engines use a technique called inversion for dealing with very large sets of documents. The method relies on the construction of a data structure, called an inverted index, which associates terms (words) to their occurrences in the collection of documents. The set of terms of interest is called the vocabulary, denoted as V . In its simplest form, an inverted index is a dictionary where each search key is a term ω ∈ V . The associated value b(ω) is a pointer to an additional intermediate data structure, called a bucket. The bucket associated with a certain term ω is essentially a list of pointers marking all the occurrences of ω in the text collection. Each entry in each bucket simply consists of the document identifier (DID), the ordinal number of the document within the collection and the ordinal line number of the term’s occurrence within the document.
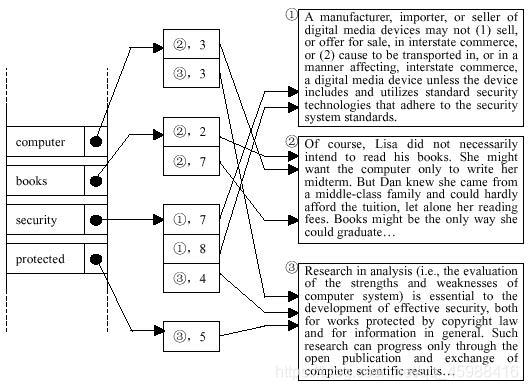
Let’s take Figure-1 for an example, which describes the general structure. Assuming that we only have three documents to handle, shown at the right part in Figure-1; first we need to tokenize the text for words (blank, punctuations and other non-alphabetic characters are used to separate words) and construct our vocabulary from terms occurring in the documents. For simplicity, we don’t need to consider any phrases, only a single word as a term. Furthermore, the terms are case-insensitive (e.g. we consider “book” and “Book” to be the same term) and we don’t consider any morphological variants (e.g. we consider “books” and “book”, “protected” and “protect” to be different terms) and hyphenated words (e.g. “middle-class” is not a single term, but separated into 2 terms “middle” and “class” by the hyphen). The vocabulary is shown at the left part in Figure-1. Each term of the vocabulary has a pointer to its bucket. The collection of the buckets is shown at the middle part in Figure-1. Each item in a bucket records the DID of the term’s occurrence.
After constructing the whole inverted index structure, we may apply it to the queries. The query is in any of the following formats:
term
term AND term
term OR term
NOT term
A single term can be combined by Boolean operators: ‘AND’, ‘OR’ and ‘NOT’ (‘term1 AND term2’ means to query the documents including term1 and term2; ‘term1 OR term2’ means to query the documents including term1 or term2; ‘NOT term1’ means to query the documents not including term1). Terms are single words as defined above. You are guaranteed that no non-alphabetic characters appear in a term, and all the terms are in lowercase. Furthermore, some meaningless stop words (common words such as articles, prepositions, and adverbs, specified to be “the, a, to, and, or, not” in our problem) will not appear in the query, either.
For each query, the engine based on the constructed inverted index searches the term in the vocabulary, compares the terms’ bucket information, and then gives the result to user. Now can you construct the engine?
Input
The input starts with integer N (0 < N < 100) representing N documents provided. Then the next N sections are N documents. Each section contains the document content and ends with a single line of ten asterisks.
**********
You may assume that each line contains no more than 80 characters and the total number of lines in the N documents will not exceed 1500.
Next, integer M (0 < M ≤ 50000) is given representing the number of queries, followed by M lines, each query in one line. All the queries correspond to the format described above.
Output
For each query, you need to find the document satisfying the query, and output just the lines within the documents that include the search term (For a ‘NOT’ query, you need to output the whole document). You should print the lines in the same order as they appear in the input. Separate different documents with a single line of 10 dashes.
----------
If no documents matching the query are found, just output a single line: ‘Sorry, I found nothing.’. The output of each query ends with a single line of 10 equal signs.
==========
Sample Input
4
A manufacturer, importer, or seller of
digital media devices may not (1) sell,
or offer for sale, in interstate commerce,
or (2) cause to be transported in, or in a
manner affecting, interstate commerce,
a digital media device unless the device
includes and utilizes standard security
technologies that adhere to the security
system standards.
**********
Of course, Lisa did not necessarily
intend to read his books. She might
want the computer only to write her
midterm. But Dan knew she came from
a middle-class family and could hardly
afford the tuition, let alone her reading
fees. Books might be the only way she
could graduate
**********
Research in analysis (i.e., the evaluation
of the strengths and weaknesses of
computer system) is essential to the
development of effective security, both
for works protected by copyright law
and for information in general. Such
research can progress only through the
open publication and exchange of
complete scientific results
**********
I am very very very happy!
What about you?
**********
6
computer
books AND computer
books OR protected
NOT security
very
slick
Sample Output
want the computer only to write her
---------
computer system) is essential to the
==========
intend to read his books. She might
want the computer only to write her
fees. Books might be the only way she
==========
intend to read his books. She might
fees. Books might be the only way she
---------
for works protected by copyright law
==========
Of course, Lisa did not necessarily
intend to read his books. She might
want the computer only to write her
midterm. But Dan knew she came from
a middle-class family and could hardly
afford the tuition, let alone her reading
fees. Books might be the only way she
could graduate
---------
I am very very very happy!
What about you?
==========
I am very very very happy!
==========
Sorry, I found nothing.
==========
HINT
题目大意(摘自紫皮书):
输入n 篇文章和m 个请求(n <100,m ≤50000),每个请求都是以下4种格式之一。
A:查找包含关键字A的文章。
A AND B:查找同时包含关键字A和B的文章。
A OR B:查找包含关键字A或B的文章。
NOT A:查找不包含关键字A的文章。
处理询问时,需要对于每篇文章输出证据。前3种询问输出所有至少包含一个关键字的行,第4种询问输出整篇文章。关键字只由小写字母组成,查找时忽略大小写。每行不超过80个字符,一共不超过1500行。
由于紫皮书上说的很简练,直接摘过来使用了。
注意:
- 查找的时候不区分大小写
- 关键词里面不包含非字母字符
- 输出时候每一个指令,输出一篇文章中所有结果后输出一行“----------”共10个,pdf上是9个!对于每一个指令输出结果的最后一行用10个等号代替减号。
解题思路:
使用map映射每一个关键字的坐标。使用set来存储每一个关键字对应的出现的地址坐标集合。
指令里面的部分内容可以使用set集合自带的函数实现:set_union()、set_intersection()。
vector<vector>text 存储文章内容
map<string, set<vector>>point 键是关键字,键值是出现的地址集合,集合的每一个元素是一个由连个元素组成的坐标数组
map<string, set>textid 用来映射每一个关键字出现过的文章编号
前三个指令按行输出,按文章判断,因此从得到的关键字的文章编号集合里面对应的每一个文章找到关键字的在文章中的行号进行输出。按整篇文章输出较简单,不解释。
本以为使用集合再带的求并集、合集的函数会更简单一些,没想到写写出来代码量一点不少,细节处理一点不少
Accepted
#include<bits/stdc++.h>
using namespace std;
#define ALL(x) x.begin(),x.end()
#define INS(x) inserter(x,x.begin())
vector<vector<string>>text; //存储文章
map<string, set<vector<int>>>point; //存储每一个关键字坐标
map<string, set<int>>textid; //存储每一个关键字的文章号
void print(set<int>p,string s1,string s2="") {
if (p.empty())cout << "Sorry, I found nothing." << endl<<"=========="<<endl;//如果存储文章编号的集合是空的
else {
for (auto i = p.begin();i != p.end();) {
int flag = 0;
set<vector<int>>p1, p2, p3;
if (point.count(s1))p1 = point[s1]; //将两个关键得到的集合进行合并成一个,目的是为了消除一行中出现连个关键词
if (point.count(s2))p2 = point[s2]; //并且也可以将两个集合真和到一个集合中进行排序
set_union(ALL(p1), ALL(p2), INS(p3));
for (auto j = p3.begin();j != p3.end();j++) //输出是一个文章一个文章进行输出,但关键词对应的集合里面可能还有其他文章的
if ((*j).front() == (*i)){ //因此需要进行判断
cout << text[(*i)][(*j).back()] << endl;
flag++; //如果没有输出就输出Sorry
}
if (!flag)cout << "Sorry, I found nothing." << endl;
cout << ((++i) == p.end() ? "==========" : "----------") << endl;
}
}
}
int main() {
int sum,num, c = 0; //文章总数、关键字在文章中的行号
string s,s1,s2;
cin >> sum;getchar(); //吃掉回车
for (int i = 0;i < sum;i++) {//循环录入
vector<string> temp;c = 0;//初始化,temp用来存储文章
while (getline(cin, s) && s != "**********") {
temp.push_back(s); //录入文章的每一行
for (int j = 0;j < s.size();j++)
if (!isalpha(s[j]))s[j] = ' ';//将每一行进行转化,吃掉非字母并将大写字母转化未小写
else if(isupper(s[j]))s[j] = s[j] - 'A' + 'a';
stringstream ss(s);
vector<int>id;
id.push_back(i);id.push_back(c); //记录坐标
while (ss >> s) {
textid[s].insert(i);//将每一个关键字的文章号记录下来
point[s].insert(id); //将坐标录入map
}
c++; //行号++
}
text.push_back(temp); //将文章入栈
}
cin >> num;getchar(); //指令数量
set<int>p1, p2, p;
for (int i = 0;i < num;i++) {
getline(cin, s);
p1.clear();p2.clear();p.clear();s1.clear();s2.clear();
if (s.find("AND") ==-1&& s.find("OR") ==-1&& s.find("NOT") ==-1) { //如果仅仅包含关键字
for (int i = 0;i < s.size();i++) if (isupper(s[i]))s[i] = s[i] - 'A' + 'a';//转化未小写
if (textid.count(s))p = textid[s]; //将关键字的文章号取出来
s1 = s;
}
else{ //如果包含指令
stringstream ss(s);
if (s.find("NOT") != -1) { //如果是NOT
ss >> s >> s1;
for (int j = 0;j < s1.size();j++)if (isupper(s1[j]))s1[j] = s1[j] - 'A' + 'a';
if (textid.count(s1))p = textid[s1]; //获取文章编号
if (p.size() == sum) { cout << "Sorry, I found nothing." << endl << "==========" << endl;continue; }
int flag = 0;
for (int j = 0;j < text.size();j++) {
if (!p.count(j)) { //如果集合里面没有此文章的下标编号就输出
cout << (0 != flag ? "----------\n" : "");
for (int h = 0;h < text[j].size();h++)
cout << text[j][h] << endl;
flag++;
}
}
cout << "==========" << endl;
continue;
}
else {
ss >> s1 >> s >> s2;
for (int j = 0;j < s1.size();j++)if (isupper(s1[j]))s1[j] = s1[j] - 'A' + 'a';//转化大写
for (int j = 0;j < s2.size();j++)if (isupper(s2[j]))s2[j] = s2[j] - 'A' + 'a';
if (textid.count(s1))p1 = textid[s1]; //获取集合
if (textid.count(s2))p2 = textid[s2];
if(s=="AND")set_intersection(ALL(p1), ALL(p2), INS(p)); //求并集
if(s=="OR") set_union(ALL(p1), ALL(p2), INS(p)); //求和
}
}
print(p,s1,s2); //打印结果
}
}
Searching the Web UVA - 1597的更多相关文章
- [刷题]算法竞赛入门经典(第2版) 5-10/UVa1597 - Searching the Web
题意:不难理解,照搬题意的解法. 代码:(Accepted,0.190s) //UVa1597 - Searching the Web //#define _XIENAOBAN_ #include&l ...
- Searching the Web论文阅读
Searching the Web (Arvind Arasu etc.) 1. 概述 2000年,23%网页每天更新,.com域内网页40%每天更新.网页生存半衰期是10天.描述方法可用Pois ...
- uva 1597 Searching the Web
The word "search engine" may not be strange to you. Generally speaking, a search engine se ...
- POJ 2050 Searching the Web
题意简述:做一个极其简单的搜索系统,对以下四种输入进行分析与搜索: 1. 只有一个单词:如 term, 只需找到含有这个单词的document,然后把这个document的含有这个单词term的那些行 ...
- 【习题 5-10 UVA-1597】Searching the Web
[链接] 我是链接,点我呀:) [题意] 在这里输入题意 [题解] 用map < string,vector < int > >mmap[100];来记录每一个数据段某个字符串 ...
- Multiple actions were found that match the request in Web Api
https://stackoverflow.com/questions/14534167/multiple-actions-were-found-that-match-the-request-in-w ...
- 基于STL的字典生成模块-模拟搜索引擎算法的尝试
该课题来源于UVA中Searching the Web的题目:https://vjudge.net/problem/UVA-1597 按照题目的说法,我对按照特定格式输入的文章中的词语合成字典,以满足 ...
- zz A list of open source C++ libraries
A list of open source C++ libraries < cpp | links http://en.cppreference.com/w/cpp/links/libs Th ...
- 5.HBase In Action 第一章-HBase简介(1.1.3 HBase的兴起)
Pretend that you're working on an open source project for searching the web by crawling websites and ...
随机推荐
- AForge实现拍照
记得先引用DLL private FilterInfoCollection videoDevices; private VideoCaptureDevice videoSource; BLL.AWBL ...
- Qt update刷新之源码分析(二)
大家好,我是IT文艺男,来自一线大厂的一线程序员 上次视频给大家从源码层面剖析了Qt update刷新机制的异步事件投递过程,这次视频主要从源码层面剖析Qt刷新事件(QEvent::UpdateReq ...
- Mac电脑管理员密码丢失解决办法
1.重新启动电脑,并长按 Command (Win)+ S,并进入命令终端. 2.进入命令终端输入一下命令 /sbin/mount -uaw rm var/db/ .applesetupdone re ...
- C++入门(2):为何还学C++?
本文首发 | 公众号:lunvey 提及编程语言,最近很火的当属Python和Java,似乎C++没落了,真的是这样吗? 转行做程序员,掌握一门编程语言,也就是职业技能,我相信更多的是在乎未来发展而不 ...
- js导出execl 兼容ie Chrome Firefox各种主流浏览器(js export execl)
第一种导出table布局的表格 1 <html> 2 3 <head> 4 <meta charset="utf-8"> 5 <scrip ...
- Java的特性和优势以及不同版本的分类,jdk,jre,jvm的联系与区别,javadoc的生成
Java 1.Java的特性和优势 Write Once,Run Anywhere 简单性 面向对象 可移植性 高性能 分布式 动态性 多线程 安全性 健壮性 2.Java的三大版本 JavaSE:标 ...
- 2020年12月-第02阶段-前端基础-CSS Day07
CSS Day07 CSS高级技巧 理解 能说出元素显示隐藏最常见的写法 能说出精灵图产生的目的 能说出去除图片底侧空白缝隙的方法 应用 能写出最常见的鼠标样式 能使用精灵图技术 能用滑动门做导航栏案 ...
- django Form 效验
Django 登入效验 .py from django import forms from student import models from django.core.exceptions impo ...
- Flink实时计算topN热榜
TopN的常见应用场景,最热商品购买量,最高人气作者的阅读量等等. 1. 用到的知识点 Flink创建kafka数据源: 基于 EventTime 处理,如何指定 Watermark: Flink中的 ...
- 03-Spring默认标签解析
默认标签的解析 上一篇分析了整体的 xml 文件解析,形成 BeanDefinition 并注册到 IOC 容器中,但并没有详细的说明具体的解析,这一篇主要说一下 默认标签的解析,下一篇主要说自定义标 ...