ML.NET 示例:图像分类模型训练-首选API(基于原生TensorFlow迁移学习)
| ML.NET 版本 | API 类型 | 状态 | 应用程序类型 | 数据类型 | 场景 | 机器学习任务 | 算法 |
|---|---|---|---|---|---|---|---|
| Microsoft.ML 1.5.0 | 动态API | 最新 | 控制台应用程序和Web应用程序 | 图片文件 | 图像分类 | 基于迁移学习的TensorFlow模型再训练进行图像分类 | DNN架构:ResNet、InceptionV3、MobileNet等 |
问题
图像分类是深度学习学科中的一个常见问题。此示例演示如何通过基于迁移学习方法训练模型来创建您自己的自定义图像分类器,该方法基本上是重新训练预先训练的模型(如InceptionV3或ResNet架构),这样您就可以在自己的图像上训练自定义模型。
在这个示例应用程序中,您可以创建自己的自定义图像分类器模型,方法是使用自己的图像从ML.NET API本机训练TensorFlow模型。
图像分类器场景–使用ML.NET训练您自己的定制深度学习模型
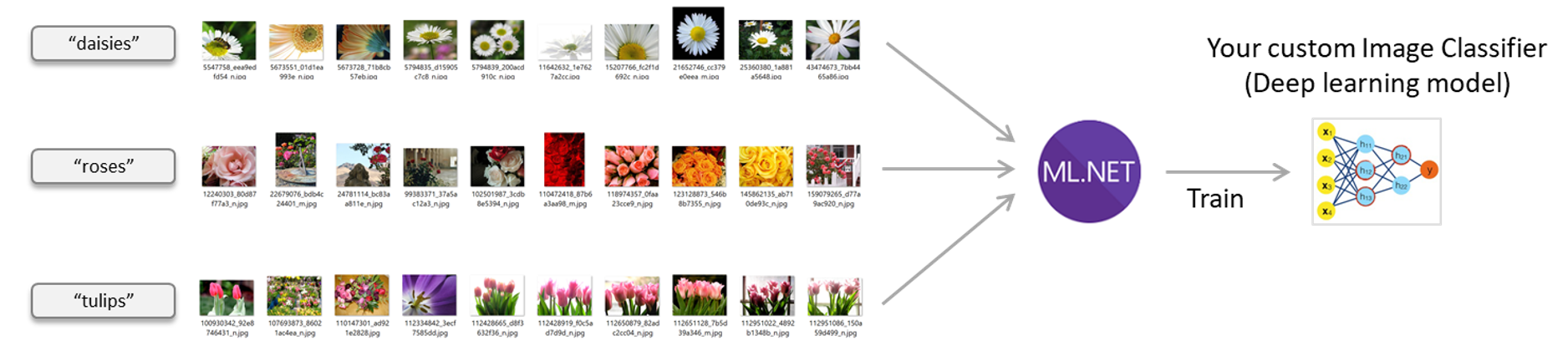
数据集(图像集)
图像集许可证
此示例的数据集基于Tensorflow提供的“flower_photosimageset”,下载地址。
此存档中的所有图像均获得Creative Commons By Attribution许可证的许可,网址为:
https://creativecommons.org/licenses/by/2.0/完整的许可证信息在license.txt文件中提供,该文件包含在作为.zip文件下载的同一图像集中。
默认情况下,示例下载的imageset有200个图像,平均分布在5个flower类中:
Images --> flower_photos_small_set -->
|
daisy
|
dandelion
|
roses
|
sunflowers
|
tulips
每个子文件夹的名称很重要,因为它将是模型用于分类图像的每个类/标签的名称。
机器学习任务-图像分类
为了解决这个问题,我们首先要建立一个ML模型。然后我们将在现有数据上训练模型,评估它有多好,最后我们将使用模型对新图像进行分类。

1. 将项目配置为使用GPU或CPU
默认情况下,此解决方案使用CPU进行训练和评分。
但是,如果您的机器有一个兼容的GPU可用(基本上大多数NVIDIA GPU显卡),您可以配置该项目使用GPU。
:警告:请确保使用下面列出的NuGet包的正确版本。其他版本可能与Nvidia CUDA v10.0不兼容
使用CPU进行训练或推断/评分
当使用CPU时,您的项目必须引用以下redist库:
SciSharp.TensorFlow.Redist (1.15.0)(CPU training)
使用CPU的训练项目中的示例参考屏幕截图:

使用GPU进行训练或推断/评分
使用GPU时,项目必须引用以下redist库(并删除CPU版本引用):
SciSharp.TensorFlow.Redist-Windows-GPU (1.14.0)(GPU training on Windows)SciSharp.TensorFlow.Redist-Linux-GPU (1.14.0)(GPU training on Linux)
使用GPU的训练项目中的示例参考屏幕截图:

2. 构建模型
构建模型包括以下步骤:
- 将图像文件(本例中为文件路径)加载到IDataView中
- 使用ImageClassification评估器进行图像分类(高级API)
定义数据架构,并在从files文件夹加载图像时引用该类型。
public class ImageData
{
public ImageData(string imagePath, string label)
{
ImagePath = imagePath;
Label = label;
}
public readonly string ImagePath;
public readonly string Label;
}
由于API使用内存图像,因此稍后您可以使用内存图像对模型进行评分,因此需要定义一个包含“byte[]image”类型中图像位的类,如下所示:
public class InMemoryImageData
{
public InMemoryImageData(byte[] image, string label, string imageFileName)
{
Image = image;
Label = label;
ImageFileName = imageFileName;
}
public readonly byte[] Image;
public readonly string Label;
public readonly string ImageFileName;
}
使用LoadImagesFromDirectory()和LoadFromEnumerable()下载imageset并加载其信息。
// 1. Download the image set and unzip
string finalImagesFolderName = DownloadImageSet(imagesDownloadFolderPath);
string fullImagesetFolderPath = Path.Combine(imagesDownloadFolderPath, finalImagesFolderName);
var mlContext = new MLContext(seed: 1);
// 2. Load the initial full image-set into an IDataView and shuffle so it'll be better balanced
IEnumerable<ImageData> images = LoadImagesFromDirectory(folder: fullImagesetFolderPath, useFolderNameAsLabel: true);
IDataView fullImagesDataset = mlContext.Data.LoadFromEnumerable(images);
IDataView shuffledFullImageFilePathsDataset = mlContext.Data.ShuffleRows(fullImagesDataset);
将数据加载到IDataView后,将对这些行进行混洗,以便在拆分为训练/测试数据集之前更好地平衡数据集。。
下一步非常重要。因为我们希望ML模型能够处理内存中的图像,所以我们需要将图像加载到数据集中,并通过调用fit()和ttransform()来实现。
需要在初始且分离的管道中执行此步骤,以便在训练时,管道和模型不会使用文件路径来创建。
// 3. Load Images with in-memory type within the IDataView and Transform Labels to Keys (Categorical)
IDataView shuffledFullImagesDataset = mlContext.Transforms.Conversion.
MapValueToKey(outputColumnName: "LabelAsKey", inputColumnName: "Label", keyOrdinality: KeyOrdinality.ByValue)
.Append(mlContext.Transforms.LoadRawImageBytes(
outputColumnName: "Image",
imageFolder: fullImagesetFolderPath,
inputColumnName: "ImagePath"))
.Fit(shuffledFullImageFilePathsDataset)
.Transform(shuffledFullImageFilePathsDataset);
此外,在分割数据集之前,我们还将标签转换为键(分类)。如果您不想在第二个管道(训练管道)中转换标签时处理/匹配KeyOrdinality,那么在拆分之前执行此操作也很重要。
现在,让我们将数据集分成两个数据集,一个用于训练,另一个用于测试/验证模型的质量。
// 4. Split the data 80:20 into train and test sets, train and evaluate.
var trainTestData = mlContext.Data.TrainTestSplit(shuffledFullImagesDataset, testFraction: 0.2);
IDataView trainDataView = trainTestData.TrainSet;
IDataView testDataView = trainTestData.TestSet;
作为最重要的步骤,您可以定义模型的训练管道,在这里您可以看到如何轻松地训练一个新的TensorFlow模型,该模型基于默认体系结构(预先训练的模型)的迁移学习,例如Resnet V2 500。
// 5. Define the model's training pipeline using DNN default values
//
var pipeline = mlContext.MulticlassClassification.Trainers
.ImageClassification(featureColumnName: "Image",
labelColumnName: "LabelAsKey",
validationSet: testDataView)
.Append(mlContext.Transforms.Conversion.MapKeyToValue(outputColumnName: "PredictedLabel",
inputColumnName: "PredictedLabel"));
上面代码中的重要一行是使用mlContext.MulticlassClassification.Trainers.ImageClassification分类训练器的行,正如您所看到的,这是一个高级API,您只需要提供哪个列包含图像,带有标签的列(要预测的列)和用于在训练时计算质量度量的验证数据集,以便模型在训练时可以自我调整(更改内部超参数)。
在本质上,此模型训练基于从默认体系结构(预先训练的模型)学习的本地TensorFlow DNN迁移,例如Resnet V2 50。还可以通过配置可选的超参数来选择要从中派生的超参数。
就这么简单,您甚至不需要进行图像变换(调整大小、规格化等)。根据所使用的DNN架构,该框架在幕后进行所需的图像转换,因此您只需使用单个API即可。
可选使用高级超参数
高级用户还有另一种重载方法,您还可以指定可选的超参数,例如epoch,batchSize,learningRate,特定的DNN架构,例如Inception v3或者Resnet v2101和其他典型的DNN参数,但大多数用户都可以从简化的API开始。
以下是如何使用高级DNN参数:
// 5.1 (OPTIONAL) Define the model's training pipeline by using explicit hyper-parameters
var options = new ImageClassificationTrainer.Options()
{
FeatureColumnName = "Image",
LabelColumnName = "LabelAsKey",
// Just by changing/selecting InceptionV3/MobilenetV2/ResnetV250
// you can try a different DNN architecture (TensorFlow pre-trained model).
Arch = ImageClassificationTrainer.Architecture.MobilenetV2,
Epoch = 50, //100
BatchSize = 10,
LearningRate = 0.01f,
MetricsCallback = (metrics) => Console.WriteLine(metrics),
ValidationSet = testDataView
};
var pipeline = mlContext.MulticlassClassification.Trainers.ImageClassification(options)
.Append(mlContext.Transforms.Conversion.MapKeyToValue(
outputColumnName: "PredictedLabel",
inputColumnName: "PredictedLabel"));
3. 训练模型
为了开始训练过程,您需要在构建的管道上运行Fit:
// 4. Train/create the ML model
ITransformer trainedModel = pipeline.Fit(trainDataView);
4. 评估模型
训练完成后,利用测试数据集对模型进行质量评价。
Evaluate函数需要一个IDataView,其中包含通过调用Transform()从测试数据集生成的预测。
// 5. Get the quality metrics (accuracy, etc.)
IDataView predictionsDataView = trainedModel.Transform(testDataset);
var metrics = mlContext.MulticlassClassification.Evaluate(predictionsDataView, labelColumnName:"LabelAsKey", predictedLabelColumnName: "PredictedLabel");
ConsoleHelper.PrintMultiClassClassificationMetrics("TensorFlow DNN Transfer Learning", metrics);
最后,保存模型:
// Save the model to assets/outputs (You get ML.NET .zip model file and TensorFlow .pb model file)
mlContext.Model.Save(trainedModel, trainDataView.Schema, outputMlNetModelFilePath);
运行项目来训练模型
您应该按照以下步骤来训练您的模型:
- 在Visual Studio中将
ImageClassification.Train设置为启动项目 - 在Visual Studio中按F5。几秒钟后,该过程将完成并保存一个新的ML.NET模型到文件
assets/outputs/imageClassifier.zip
5. “终端用户”应用中的使用模型
GPU与CPU对模型的使用/评分对比
在使用/评分模型时,您也可以在CPU/GPU之间进行选择,但是,如果使用GPU,您还需要确保运行模型的计算机/服务器支持GPU。
设置评分/使用项目以使用GPU的方法与本readme.md开头所述的方法相同,只需使用一个或另一个redist库。
用于评分的示例控制台应用程序
在示例的解决方案中,还有第二个项目名为ImageClassifcation.Predict。这个控制台应用程序只需加载您定制的ML.NET模型,并以假设的最终用户应用程序的方式执行一些样本预测。
首先要做的是将生成的assets/outputs/imageClassifier.zip文件复制/粘贴到使用项目的inputs/MLNETModel文件夹中。
关于代码,您首先需要加载在模型训练应用执行期间创建的模型。
MLContext mlContext = new MLContext(seed: 1);
ITransformer loadedModel = mlContext.Model.Load(imageClassifierModelZipFilePath, out var modelInputSchema);
然后,您可以创建一个预测器引擎对象,并最终使用文件夹assets/inputs/images-for-predictions的第一个图像进行一些样本预测,其中只有一些图像在训练模型时没有使用。
请注意,在评分时,只需要具有内存图像的InMemoryImageData类型。
该图像也可以通过任何其他通道传输,而不是从文件中加载。
例如,这个解决方案中的ImageClassification.WebApp通过HTTP获取将要用于预测的图像。
var predictionEngine = mlContext.Model.CreatePredictionEngine<InMemoryImageData, ImagePrediction>(loadedModel);
//Predict the first image in the folder
IEnumerable<InMemoryImageData> imagesToPredict = LoadInMemoryImagesFromDirectory(
imagesFolderPathForPredictions, false);
InMemoryImageData imageToPredict = new InMemoryImageData
{
Image = imagesToPredict.First().Image,
ImageFileName = imagesToPredict.First().ImageFileName
};
var prediction = predictionEngine.Predict(imageToPredict);
// Get the highest score and its index
float maxScore = prediction.Score.Max();
Console.WriteLine($"Image Filename : [{imageToPredict.ImageFileName}], " +
$"Predicted Label : [{prediction.PredictedLabel}], " +
$"Probability : [{maxScore}] "
);
预测引擎接收InMemoryImageData类型的对象作为参数(包含2个属性:Image和ImageFileName)。
该模型不使用ImageFileName。 您只需将它放在这里,以便在显示预测时可以将文件名打印出来。 预测仅使用byte[] Image字段中的图像位。
然后,模型返回类型为ImagePrediction的对象,该对象包含所有图像类/类型的PredictedLabel和所有Scores。
由于PredictedLabel已经是一个字符串,因此它将显示在控制台中。
关于预测标签的分数,我们只需要取最高的分数,即预测标签的概率。
运行“最终用户应用程序”项目以尝试预测
您应该按照以下步骤来使用您的模型:
- 在Visual Studio中将“ImageClassification.Predict”设置为启动项目
- 在Visual Studio中按F5。几秒钟后,该过程将通过加载并使用自定义的
imageClassifier.zip模型来显示预测。
用于评分/推断的ASP.NET Core web应用示例
在示例的解决方案中,还有另一个名为ImageClassification.WebApp的项目,它是一个ASP.NET Core web应用程序,允许用户通过HTTP提交图像,并使用内存中的图像进行评分/预测。
此示例还使用了PredictionEnginePool,建议用于多线程和可扩展的应用程序。
您可以在下面看到该应用的屏幕截图:

TensorFlow DNN迁移学习背景信息
这个示例应用程序正在重新训练用于图像分类的TensorFlow模型。您可能认为它与另一个示例非常相似 Image classifier using the TensorFlow Estimator featurizer。 不过,内部的实现方式却有很大的不同。在上述示例中,它使用的是“模型合成方法”,其中初始TensorFlow模型(即InceptionV3或ResNet)仅用于对图像进行特征化,并生成每个图像的二进制信息,以供添加在顶部的另一个ML.NET分类器训练器使用(例如LbfgsMaximumEntropy)。因此,即使该示例使用的是TensorFlow模型,您也只能使用ML.NET trainer进行训练,您不会重新训练新的TensorFlow模型,而是训练ML.NET模型。这就是为什么该示例的输出只是一个ML.NET模型(.zip文件)。
与此相反,本例在本地基于迁移学习方法对新的TensorFlow模型进行重新训练,再从指定的预训练模型(Inception V3或ResNet)派生的新TensorFlow模型进行了训练。
重要的区别在于,这种方法使用TensorFlowAPI进行内部再训练,并创建一个新的TensorFlow模型(.pb)。然后,您使用的ML.NET.zip文件模型就像是新的重新训练的TensorFlow模型的包装器。这就是为什么您还可以看到训练后生成的新.pb文件的原因:

在下面的屏幕截图中,您可以看到如何在Netron中看到重新训练的TensorFlow模型(custom_retrained_model_based_on_InceptionV3.meta.pb),因为它是本机TensorFlow模型:

好处:
使用GPU进行训练和推断:
当使用基于TensorFlow的本机DNN方法时,您可以使用CPU或GPU(如果可用)来获得更好的性能(减少训练和评分所需的时间)。跨多个框架和平台重用:
由于您本机训练了Tensorflow模型,除了能够使用ML.NET 'wrapper'模型(.zip文件)运行/使用该模型之外,您还可以使用.pb Tensorflow冻结模型并在任何其他框架(如Python/Keras/Tensorflow)上运行它,或者Java/Android应用程序或任何支持TensorFlow的框架。灵活性和性能:
由于ML.NET是在Tensorflow层上进行内部再训练的,因此ML.NET团队将能够进一步优化并采取多种方法,如在最后一层上进行训练或跨Tensorflow模型在多个层上进行训练,并获得更好的质量水平。

ML.NET 示例:图像分类模型训练-首选API(基于原生TensorFlow迁移学习)的更多相关文章
- ML.NET 示例:推荐之场感知分解机
写在前面 准备近期将微软的machinelearning-samples翻译成中文,水平有限,如有错漏,请大家多多指正. 如果有朋友对此感兴趣,可以加入我:https://github.com/fei ...
- 学习ML.NET(2): 使用模型进行预测
训练模型 在上一篇文章中,我们已经通过LearningPipeline训练好了一个“鸢尾花瓣预测”模型, var model = pipeline.Train<IrisData, IrisPre ...
- 基于深度学习和迁移学习的识花实践——利用 VGG16 的深度网络结构中的五轮卷积网络层和池化层,对每张图片得到一个 4096 维的特征向量,然后我们直接用这个特征向量替代原来的图片,再加若干层全连接的神经网络,对花朵数据集进行训练(属于模型迁移)
基于深度学习和迁移学习的识花实践(转) 深度学习是人工智能领域近年来最火热的话题之一,但是对于个人来说,以往想要玩转深度学习除了要具备高超的编程技巧,还需要有海量的数据和强劲的硬件.不过 Tens ...
- 用tensorlayer导入Slim模型迁移学习
上一篇博客[用tensorflow迁移学习猫狗分类]笔者讲到用tensorlayer的[VGG16模型]迁移学习图像分类,那麽问题来了,tensorlayer没提供的模型怎么办呢?别担心,tensor ...
- [DeeplearningAI笔记]ML strategy_2_3迁移学习/多任务学习
机器学习策略-多任务学习 Learninig from multiple tasks 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.7 迁移学习 Transfer Learninig 神 ...
- 基于TensorFlow Object Detection API进行迁移学习训练自己的人脸检测模型(二)
前言 已完成数据预处理工作,具体参照: 基于TensorFlow Object Detection API进行迁移学习训练自己的人脸检测模型(一) 设置配置文件 新建目录face_faster_rcn ...
- 【机器学习PAI实践十】深度学习Caffe框架实现图像分类的模型训练
背景 我们在之前的文章中介绍过如何通过PAI内置的TensorFlow框架实验基于Cifar10的图像分类,文章链接:https://yq.aliyun.com/articles/72841.使用Te ...
- ML.NET 示例:聚类之客户细分
写在前面 准备近期将微软的machinelearning-samples翻译成中文,水平有限,如有错漏,请大家多多指正. 如果有朋友对此感兴趣,可以加入我:https://github.com/fei ...
- ML.NET 示例:目录
ML.NET 示例中文版:https://github.com/feiyun0112/machinelearning-samples.zh-cn 英文原版请访问:https://github.com/ ...
随机推荐
- Docker 一键安装及Docker管理面板Portainer中文汉化
前言 Docker接触了一段时间了,批量操作过程中感觉太繁琐,所以找到了好评率比较高的Portainer面板,使用后感觉的确不错所以准备拿出来精力来做个汉化版,过程中发现词条非常多,所以暂时先汉 ...
- Android - 利用扩展函数为Bitmap添加文字水印
<异空间>项目技术分享系列--扩展函数为Bitmap添加文字水印 对图片Bitmap绘制文字水印还是比较常见的需求,毕竟版权意识都在增强(用户可以给自己图片加上用户名),还可以为用户提供更 ...
- QuickBase64 - Android 下拉通知栏快捷base64加解密工具
Android Quick Setting Tile Base64 Encode/Decode Tool Android 下拉通知栏快捷 base64 加解密,自动将剪切板的内容进行 base64 E ...
- 🚩数分工作了三年,我干了件很酷的事情
从17年毕业来,一直都在干数据分析的工作.和很多转行的小伙伴一样,没有对口的科班学习,摸不清数据分析具体情况,起初充满着很多迷茫. 在刚开始的1年半中,都是自己从淘宝买些课程,最多时,网盘放了4-5T ...
- Apache配置 6. 访问日记切割
日志一直记录总有一天会把整个磁盘占满,所以有必要让它自动切割,并删除老的日志文件 (1)配置 (1)配置 # vim /usr/local/apache2 .4/conf/extra/httpd-vh ...
- python基础学习之描述符和装饰器
描述符的了解: 描述符协议: python描述符是一个"绑定行为"的对象属性,在描述符协议中,它可以通过方法重写属性的访问.这些方法有: __get__, __set__, 和__ ...
- Docker 一图胜千言
Docker 一图胜千言 0 为什么 Docker 比虚拟机快? 注:少了一层抽象层( Hypervisor ) 1 Docker Logo 要素: 大海 宿主机 Host 鲸鱼 Docker 集装箱 ...
- 简历求职:STAR法则
做了近2年的大学生就业辅导工作,也接触了很多即将走出校园的大学生,做个总结与大家分享,同时也是对自己的一个总结. 最近刚听说STAR法则,这也是一直我们给学生的指导思想,百度了一下: STAR法则,即 ...
- springboot系列五:springboot整合mybatisplus jsp
一.用IDEA创建项目 1.添加pom.xml <?xml version="1.0" encoding="UTF-8"?> <project ...
- python多线程参考文章
1. https://www.jianshu.com/p/c93e630d8089 2.https://www.runoob.com/python/python-multithreading.html ...