Scrapy入门到放弃05:让Item在Pipeline中飞一会儿
前言
"又回到最初的起点,呆呆地站在镜子前"。
本来这篇是打算写Spider中间件的,但是因为这一块涉及到Item,所以这篇文章先将Item讲完,顺便再讲讲Pipeline,然后再讲Spider中间件。
Item和Pipeline
依旧是先上架构图。
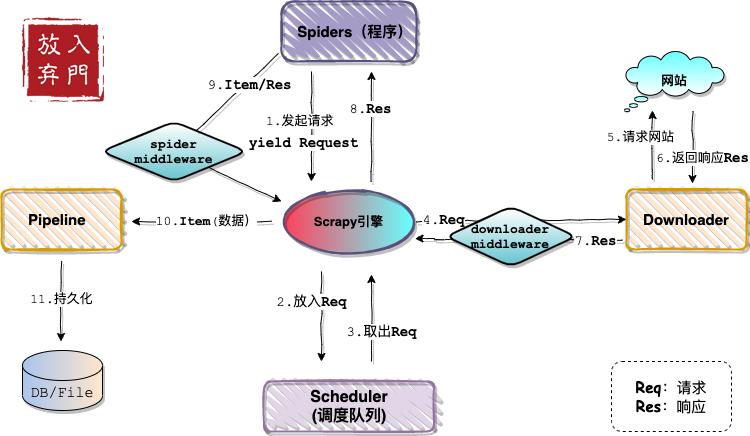
从架构图中可以看出,当下载器从网站获取了网页响应内容,通过引擎又返回到了Spider程序中。我们在程序中将响应内容通过css或者xpath规则进行解析,然后构造成Item对象。
而Item和响应内容在传递到引擎的过程中,会被Spider中间件进行处理。最后Pipeline会将引擎传递过来的Item持久化存储。
总结:Item是数据对象,Pipeline是数据管道。

Item
Item说白了就是一个类,里面包含数据字段。目的是为了让你把从网页解析出来的目标数据进行结构化。需要注意的是,我们通常要先确定Item的结构,然后再在程序中构造、在pipeline中处理。
这里依旧还是以斗罗大陆为例。
Item类定义
Item在items.py中定义。我们先看看此py文件中的Item定义模板。
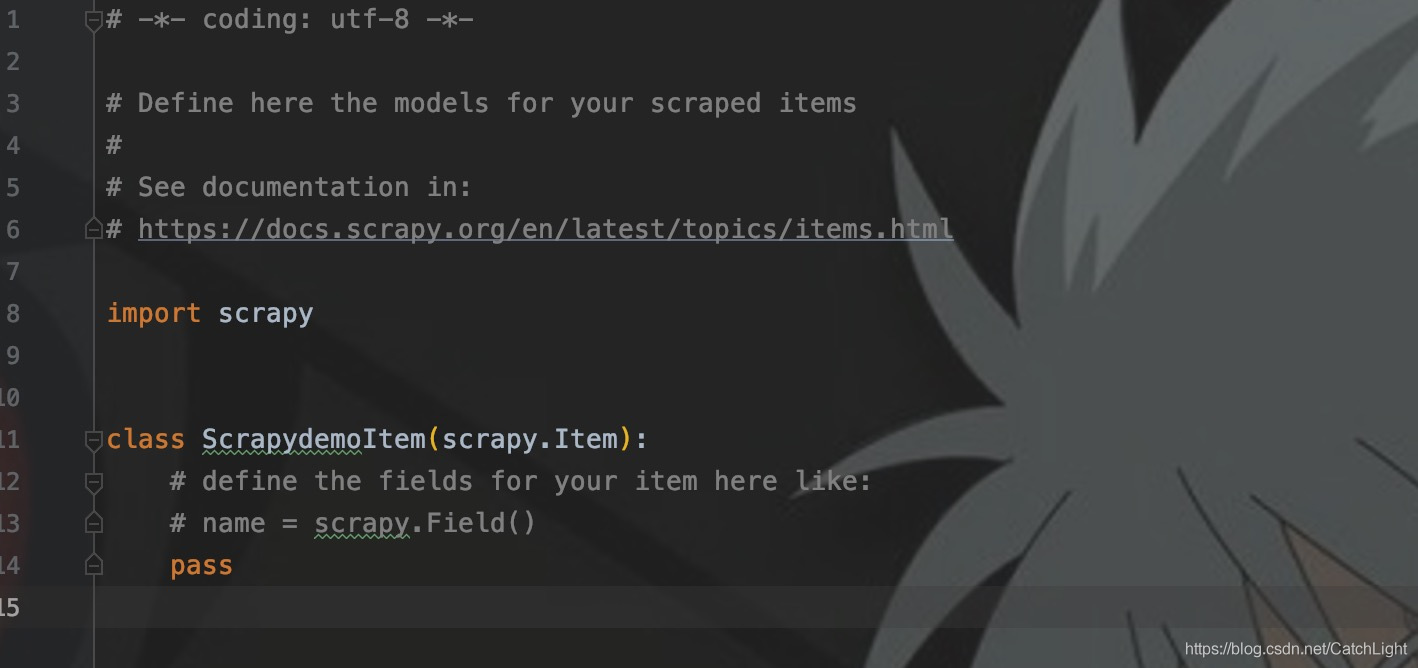
如图所示,即是模板,要点有二。
- Item类继承scrapy.Item
- 字段 = scrapy.Field()
这里根据我们在斗罗大陆页面需要采集的数据字段,进行Item定义。
class DouLuoDaLuItem(scrapy.Item):
name = scrapy.Field()
alias = scrapy.Field()
area = scrapy.Field()
parts = scrapy.Field()
year = scrapy.Field()
update = scrapy.Field()
describe = scrapy.Field()
Item数据构造
当我们将Item类定义之后,就要在spider程序中进行构造,即填充数据。
# 导入Item类,ScrapyDemo是包名
from ScrapyDemo.items import DouLuoDaLuItem
# 构造Item对象
item = DouLuoDaLuItem
item['name'] = name
item['alias'] = alias
item['area'] = area
item['parts'] = parts
item['year'] = year
item['update'] = update
item['describe'] = describe
代码如上,一个Item数据对象就被构造完成。
发射Item到Pipeline
在Item对象构造完成之后,还需要一行代码就能将Item传递到Pipeline中。
yield item
至此,Pipeline,我来了。
Pipeline
Pipeline直译就是管道,负责处理Item数据,从而实现持久化。说白了就是将数据放到各种形式的文件、数据库中。
功能
官方给出的Pipeline功能有:
- 清理HTML数据
- 验证数据(检查item包含某些字段)
- 查重(并丢弃)
- 将爬取结果保存到数据库
在实际开发中,4的场景比较多。
定义Pipeline
Pipeline定义在pipeline.py中,这里依旧先看看Pipeline给定的模板。
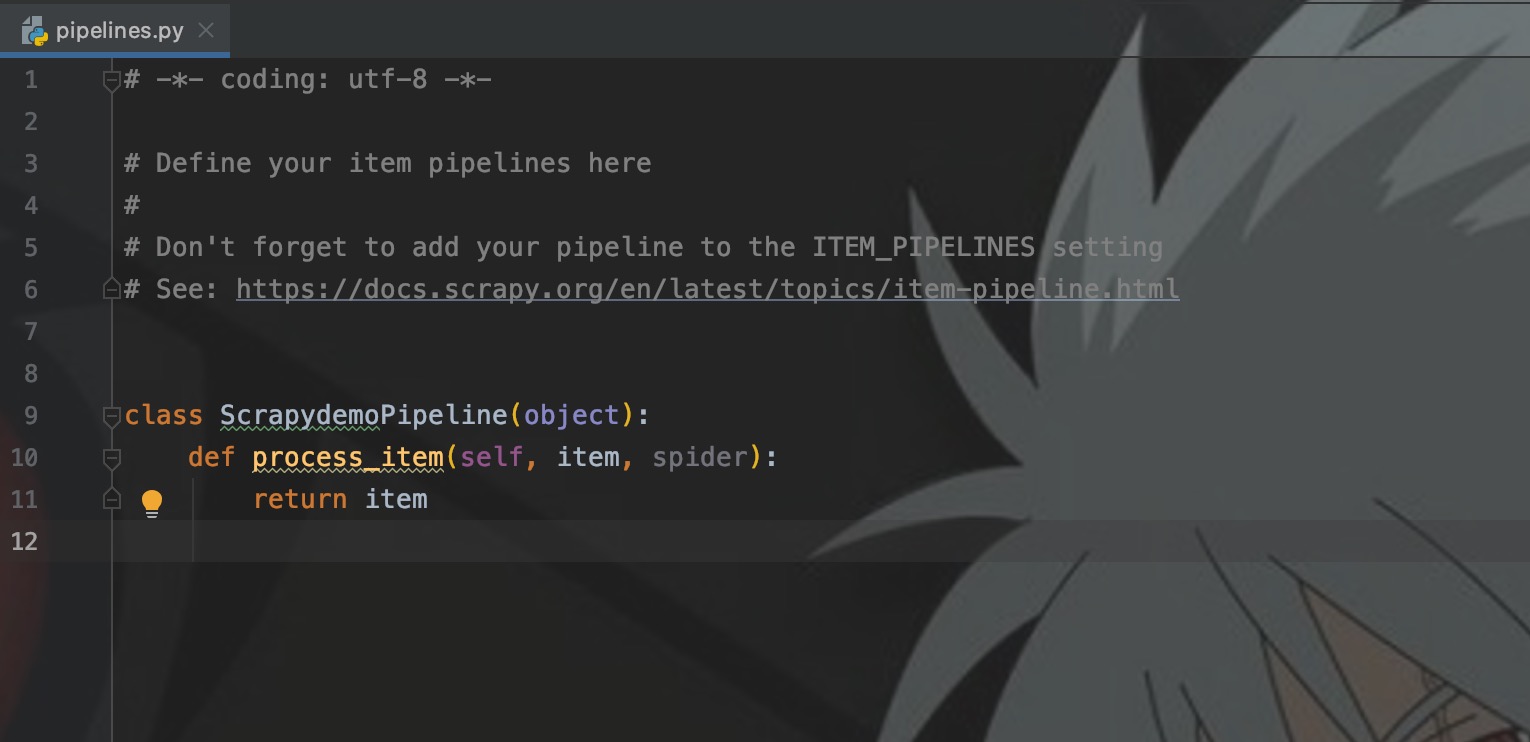
如图,只实现了process_item()方法,来处理传递过来的Item。但是在实际开发中,我们通常要实现三个方法:
- __init__:用来构造对象属性,例如数据库连接等
- from_crawler:类方法,用来初始化变量
- process_item:核心逻辑代码,处理Item
这里,我们就自定义一个Pipeline,将Item数据放入数据库。
配置Pipeline
和middleware一样在settings.py中进行配置,这里对应的是ITEM_PIPELINE参数。
ITEM_PIPELINES = {
'ScrapyDemo.pipelines.CustomDoLuoDaLuPipeline': 300
}
Key依旧对应的是类全路径,Value为优先级,数字越小,优先级越高。Item会根据优先级依此通过每个Pipeline,这样可以在每个Pipeline中对Item进行处理。
为了直观,后续我将Pipeline在代码中进行局部配置。
pipeline连接数据库
1. 配置数据库属性
我们首先在setttings.py中将数据库的IP、账号、密码、数据库名称配置,这样在pipeline中就可直接读取,并创建连接。
MYSQL_HOST = '175.27.xx.xx'
MYSQL_DBNAME = 'scrapy'
MYSQL_USER = 'root'
MYSQL_PASSWORD = 'root'
2. 定义pipeline
主要使用pymysql驱动连接数据库、twisted的adbapi来异步操作数据库,这里异步划重点,基本上异步就是效率、快的代名词。
import pymysql
from twisted.enterprise import adbapi
from ScrapyDemo.items import DouLuoDaLuItem
class CustomDoLuoDaLuPipeline(object):
def __init__(self, dbpool):
self.dbpool = dbpool
@classmethod
def from_crawler(cls, crawler):
# 读取settings中的配置
params = dict(
host=crawler.settings['MYSQL_HOST'],
db=crawler.settings['MYSQL_DBNAME'],
user=crawler.settings['MYSQL_USER'],
passwd=crawler.settings['MYSQL_PASSWORD'],
charset='utf8',
cursorclass=pymysql.cursors.DictCursor,
use_unicode=False
)
# 创建连接池,pymysql为使用的连接模块
dbpool = adbapi.ConnectionPool('pymysql', **params)
return cls(dbpool)
def process_item(self, item, spider):
if isinstance(item, DouLuoDaLuItem):
query = self.dbpool.runInteraction(self.do_insert, item)
query.addErrback(self.handle_error, item, spider)
return item
# 执行数据库操作的回调函数
def do_insert(self, cursor, item):
sql = 'insert into DLDLItem(name, alias, area, parts, year, `update`, `describe`) values (%s, %s, %s, %s, %s, %s, %s)'
params = (item['name'], item['alias'], item['area'], item['parts'], item['year'], item['update'], item['describe'])
cursor.execute(sql, params)
# 当数据库操作失败的回调函数
def handle_error(self, failue, item, spider):
print(failue)
这里要重点强调一下上面代码中的几个点。
- process_item()中为什么使用isinstance来判断item的类型?
这个是为了解决多种Item经过同一个Pipiline时,需要调用不同的方法来进行数据库操作的场景。如下图所示:
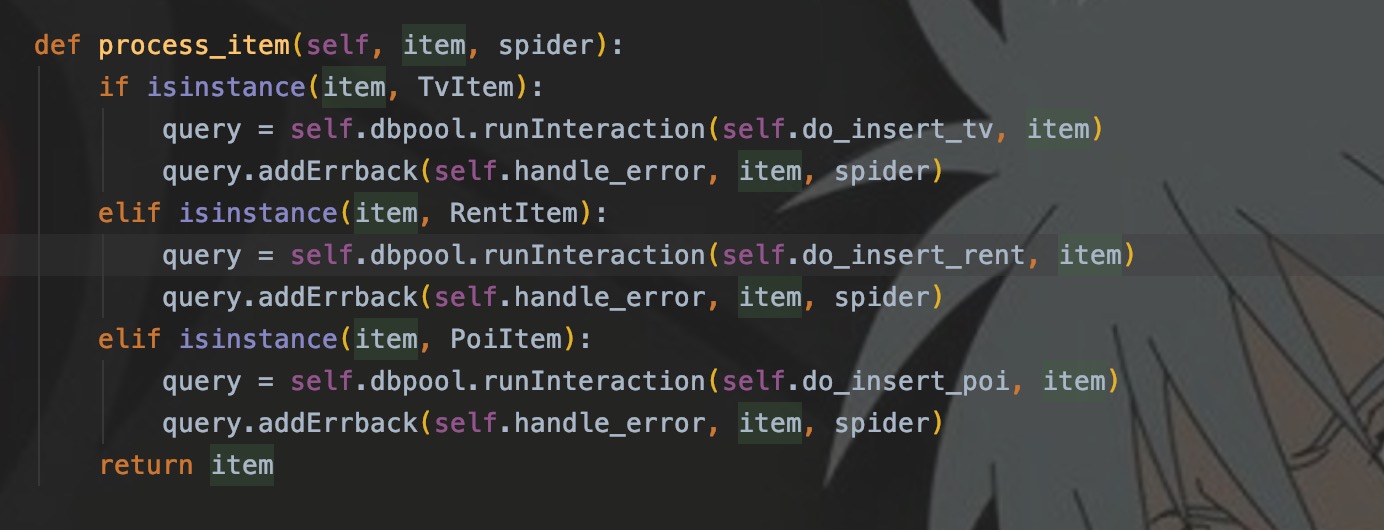
不同的Item具有不同的结构,意味着需要不同的sql来插入到数据库中,所以会先判断Item类型,再调用对应方法处理。
- sql中update、describe字段为什么要加反引号?
update、describe和select一样,都是MySQL的关键字,所以如果想要在字段中使用这些单词,在执行sql和建表语句汇总都要加上反引号,否则就会报错。
3. 生成Item放入pipeline
即将迎面而来的依旧是熟悉的代码,Item结构在上面的items.py中已经定义。pipeline也将在代码内局部配置,这个不清楚的可以看第二篇文章。
import scrapy
from ScrapyDemo.items import DouLuoDaLuItem
class DouLuoDaLuSpider(scrapy.Spider):
name = 'DouLuoDaLu'
allowed_domains = ['v.qq.com']
start_urls = ['https://v.qq.com/detail/m/m441e3rjq9kwpsc.html']
custom_settings = {
'ITEM_PIPELINES': {
'ScrapyDemo.pipelines.CustomDoLuoDaLuPipeline': 300
}
}
def parse(self, response):
name = response.css('h1.video_title_cn a::text').extract()[0]
common = response.css('span.type_txt::text').extract()
alias, area, parts, year, update = common[0], common[1], common[2], common[3], common[4]
describe = response.css('span._desc_txt_lineHight::text').extract()[0]
item = DouLuoDaLuItem()
item['name'] = name
item['alias'] = alias
item['area'] = area
item['parts'] = parts
item['year'] = year
item['update'] = update
item['describe'] = describe
print(item)
yield item
4.程序测试
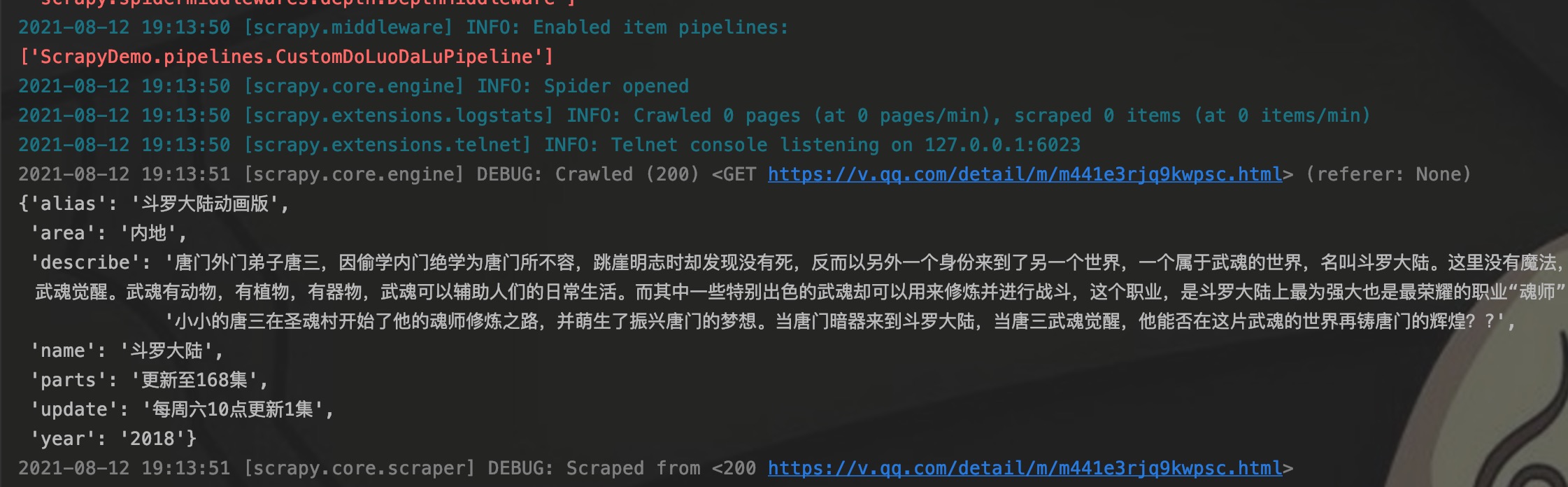
启动程序,可以看到控制台打印了已经启用的pipeline列表,同时也可以看到item的内容。程序执行结束后,我们去数据库查看数据是否已经放到数据库。

如图,在数据库的DLDLItem表中已经可以查到数据。
结语
Item和Pipeline让数据结构存储流程化,我们可以定义并配置多个Pipeline,当yield item之后,数据就会根据存储在文件里、数据库里
与之相关的还有一个ItemLoaders,我基本上没有用过,但是后面还是当做扩展来写一下。期待下一次相遇。
95后小程序员,写的都是日常工作中的亲身实践,置身于初学者的角度从0写到1,详细且认真。文章会在公众号 [入门到放弃之路] 首发,期待你的关注。

Scrapy入门到放弃05:让Item在Pipeline中飞一会儿的更多相关文章
- 小白学 Python 爬虫(38):爬虫框架 Scrapy 入门基础(六) Item Pipeline
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- Scrapy入门到放弃03:理解settings配置,监控Scrapy引擎
前言 代码未动,配置先行.本篇文章主要讲述一下Scrapy中的配置文件settings.py的参数含义,以及如何去获取一个爬虫程序的运行性能指标. 这篇文章无聊的一匹,没有代码,都是配置化的东西,但是 ...
- Scrapy入门到放弃06:Spider中间件
前言 写一写Spider中间件吧,都凌晨了,一点都不想写,主要是也没啥用...哦不,是平时用得少.因为工作上的事情,已经拖更好久了,这次就趁着半夜写一篇. Scrapy-deltafetch插件是在S ...
- Scrapy入门到放弃01:开启爬虫2.0时代
前言 Scrapy is coming!! 在写了七篇爬虫基础文章之后,终于写到心心念念的Scrapy了.Scrapy开启了爬虫2.0的时代,让爬虫以一种崭新的形式呈现在开发者面前. 在18年实习的时 ...
- scrapy入门到放弃02:整一张架构图,开发一个程序
前言 Scrapy开门篇写了一些纯理论知识,这第二篇就要直奔主题了.先来讲讲Scrapy的架构,并从零开始开发一个Scrapy爬虫程序. 本篇文章主要阐述Scrapy架构,理清开发流程,掌握基本操作. ...
- Scrapy入门到放弃04:下载器中间件,让爬虫更完美
前言 MiddleWare,顾名思义,中间件.主要处理请求(例如添加代理IP.添加请求头等)和处理响应 本篇文章主要讲述下载器中间件的概念,以及如何使用中间件和自定义中间件. MiddleWare分类 ...
- Java从入门到放弃——05.修饰符static,final,权限修饰符
本文目标 static final: 权限修饰符:public,private,protected,缺省 1.static 静态修饰符,被static修饰的变量或者方法会被加载进静态区内存,不需要创建 ...
- scrapy学习笔记(三):使用item与pipeline保存数据
scrapy下使用item才是正经方法.在item中定义需要保存的内容,然后在pipeline处理item,爬虫流程就成了这样: 抓取 --> 按item规则收集需要数据 -->使用pip ...
- Linux入门到放弃之一《在VMware虚拟机中安装Linux系统(RedHat)》
1.启动VMware: 2.新建虚拟机: 3.自定义配置(1安装客户机操作系统点击"稍后安装操作系统"2选择客户机操作系统为Linux,版本为Red Hat Enterprise ...
随机推荐
- 前端VUE基于gitlab的CI_CD
目录 CI 1.Gitlab的CI 1.1 GitLab-Runner 1.2 .gitlab-ci.yml 1.3 配置.gitlab-ci.yml 1.3.1 Pipeline概念 1.3.2 S ...
- linux 安装libreOffice
linux 安装libreOffice 第一种方式:通过yum install libreoffice* 安装,但在使用docx文档转化为pdf的过程中,发现有些表格样式出现变形,因此采用如下方式安装 ...
- 配置Internal Load balancer中VM的外网访问
当在Azure中部署SQL VM时,处于安全考虑,不会配置VM的Public IP,会禁止外网的进出站访问,只允许从内部VNET,或者特定的内部IP访问.特别是当使用Azure Internal Lo ...
- 题解 Sue的小球/名次排序问题/方块消除/奥运物流
Sue的小球 名次排序问题 方块消除 奥运物流 Sue的小球 题目大意 有 \(n\) 个小球在下落,初始位置 \((x_i,y_i)\),下落速度为 \(v_i\).你初始位置在 \(x_0\),速 ...
- 常用的SQL查询思维/场景
前言 现在大多数开发工作中,已经可以使用一些组件或框架提供的强大的条件构造器来完成查询数据了,虽然强大而且方便,但也还是存在很多业务场景需要实打实的编写传统SQL语句.特别一些测试.维护.问题排查的时 ...
- SimpleDateFormat、Date和String互转
今天在修改bug时遇到一个查询异常:根据时间段查询的时候,如果查询时间段含12点钟,那么能查到时间段之外的其他数据: 跟踪了数据流动发现,前同事写的程序中,有一处是讲前端传来时间字符串转为Date的一 ...
- Netty 了解
1.1 Netty 是什么? Netty is an asynchronous event-driven network application framework for rapid develop ...
- MyBatis原生批量插入的坑与解决方案!
前面的文章咱们讲了 MyBatis 批量插入的 3 种方法:循环单次插入.MyBatis Plus 批量插入.MyBatis 原生批量插入,详情请点击<MyBatis 批量插入数据的 3 种方法 ...
- Intellij IDEA使用姿势
Intellij IDEA 智能补全的 10 个姿势,太牛逼了.. Intellij Idea非常6的10个姿势
- 【UE4 C++】DateTime、Timespan 相关函数
基于UKismetMathLibrary DateTime 相关函数 Timespan 运算操作相关函数见尾部附录 /** Returns the date component of A */ UFU ...