第57篇-profile实例
之前已经介绍过回边计数和ProfileData与Layout,下面举个具体的例子看下MethodData是怎么利用ProfileData等记录详细的运行时信息的。实例如下:
package com.test;
import java.util.LinkedList;
public class CompilationDemo {
public static void main(String args[]){
fact(60010*2);
}
public static int fact(int n) {
int p = 1;
while (n > 0) {
p++;
}
return p;
}
}
通过如下命令配置让HotSpot VM运行如上使用Javac编译的字节码,如下:
-cp .:/media/mazhi/sourcecode/workspace/projectjava/projectjava01/bin -XX:+TraceOnStackReplacement com.test/CompilationDemo
生成的字节码如下:
public static int fact(int);
descriptor: (I)I
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=1, locals=2, args_size=1
0: iconst_1
1: istore_1
2: iload_0
3: ifle 12 // 当栈顶int类型数值小于等于0时跳转
6: iinc 1, 1
9: goto 2
12: iload_1
13: ireturn
对如上的字节码来说,字节码索引为3和9的2个字节码 ifle和goto需要有对应的ProfileData,具体就是BranchData和JumpData。其数据布局如下:
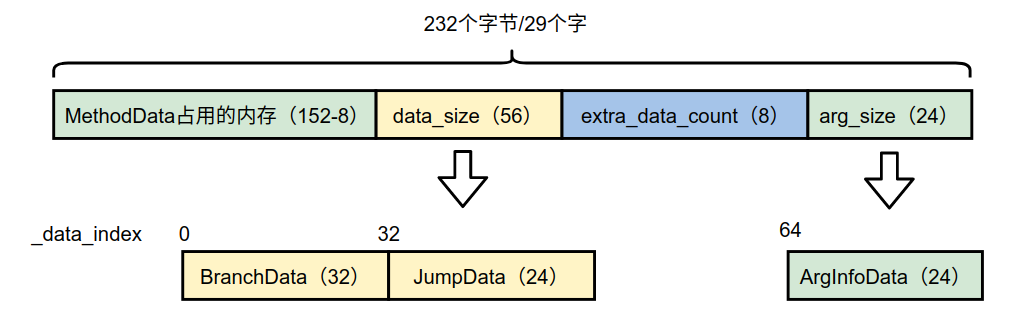
BranchData、JumpData等都是按照DataLayout的格式布局数据的,DataLayout在前一篇文章中详细介绍过,如下:
class DataLayout VALUE_OBJ_CLASS_SPEC {
private:
union {
// intptr_t类型占用8个字节
intptr_t _bits;
struct {
u1 _tag;
// flags的格式为[ recompile:1 | reason:3 | flags:4]
u1 _flags;
u2 _bci;
} _struct;
} _header;
// 可以有许多个cells,首个cell的地址通过如下的_cells属性保存,
// 具体的cells数组的大小还要根据具体的ProfileData来决定
intptr_t _cells[1];
// ...
}
对于本篇的实例来说,各个具体的值如下:
(1)BranchData
DataLayout::_bits=0
DataLayout::_struct._tag=DataLayout::branch_data_tag
_header._struct._bci=3
_cells数组的大小为3,每个数组元素的大小为8字节。_cells的初始化主要是在各个ProfileData的子类中调用post_initialize()函数完成的,对于BranchData来说,调用BranchData类的post_initialize()函数初始化。_cells在初始化时会在下标为displacement_off_set=1处存储56。因为ifle指令跳转的目的地指令没有对应的ProfileData数据,所以直接跳转出了data_size区域。
BranchData类的定义如下:
class BranchData : public JumpData {
protected:
enum {
not_taken_off_set = jump_cell_count, // jump_cell_count的值为2
branch_cell_count // branch_cell_count的值为3
};
// ...
}
注意BranchData类继承自JumpData类,所以BranchData类的_cells需要3个,分别为JumpData::taken_off_set、JumpData::displacement_off_set和BranchData::not_taken_off_set。
调用如下函数初始化BranchData,函数的实现如下:
void BranchData::post_initialize(BytecodeStream* stream, MethodData* mdo) {
assert(stream->bci() == bci(), "wrong pos");
int target = stream->dest();
// 调用dp()函数获取ProfileData::_data属性的值,然后结合MethodData::_data计算
// 出BranchData相对于MethodData::_data的索引值
int my_di = mdo->dp_to_di(dp());
// 通过字节码指令的下标索引获取target data index
int target_di = mdo->bci_to_di(target);
int offset = target_di - my_di;
// 将偏移存储到JumpData的displacement_off
set_displacement(offset);
}
可以看到会初始化BranchData中的JumpData::displacement_off_set属性的值。其它_cells的值为0。
(2)JumpData
DataLayout::_bits=0
DataLayout::_struct._tag=DataLayout::jump_data_tag
_header._struct._bci=9
_cells数组的大小为2,初始化时在下标为displacement_off_set=1处存储-32。因为goto指令会跳转到下标索引为2的字节码处,这个指令虽然没有ProfileData,但是ifle有对应的BranchData数据,所以JumpData的_data_index加上-32后值为0,在运行过程中遇到ifle时直接能通过_data_index找到对应的BranchData。
JumpData类的定义如下:
class JumpData : public ProfileData {
protected:
enum {
taken_off_set, // 0
displacement_off_set, // 1
jump_cell_count // 2
};
// ...
}
JumpData占用的内存大小除了DataLayout::_header之外,还要分配2个cell,每个cell的大小为8字节,分别用来存储taken_off和displacement_off。taken_off表示跳转的次数,而displacement_off用来调整method data pointer到对应的ProfileData位置,这个ProfileData位置和跳转的字节码指令对应,这样如果跳转的目标字节码指令如果也有一些需要记录的信息,则直接通过method data pointer就能找到对应的ProfileData进行记录。
JumpData::post_initialize()函数的实现如下:
void JumpData::post_initialize(BytecodeStream* stream, MethodData* mdo) {
int target;
Bytecodes::Code c = stream->code();
// 获取跳转指令的目标跳转字节码指令的索引
if (c == Bytecodes::_goto_w || c == Bytecodes::_jsr_w) {
target = stream->dest_w();
} else {
target = stream->dest();
}
// dp()函数获取JumpData::_data的首地址,然后结合MethodData::_data计算
// 出JumpData在MethodData::_data的索引值
int my_di = mdo->dp_to_di(dp()); //
// 通过字节码指令的下标索引获取target data index
int target_di = mdo->bci_to_di(target);
int offset = target_di - my_di;
// 将偏移存储到JumpData的displacement_off
set_displacement(offset);
}
可以看到JumpData中的displacement_off存储的是_data的偏移量,method data pointer其实是指向_data中的某一项ProfileData,偏移 displacement_off 后仍然指向另外一个ProfileData。
(3)ArgInfoData
DataLayout::_bits=0
DataLayout::_struct._tag=DataLayout::arg_info_data_tag
_header._struct._bci=0
_cells数组的大小为2。在下标为0处的数组中存储的是数组的长度,为1。可以理解为下标索引最大为1。
下面看一下,控制转移指令是如何通过Method::_method_data中的_data属性记录运行时信息的。
ifle指令对应的汇编代码如下:
// 对第1个第2个操作数进行逻辑与,如果为0则ZF设置为0
0x00007fffe101ba07: test %eax,%eax
// 如果大于0则跳转到---- not_taken ----
0x00007fffe101ba09: jg 0x00007fffe101bd69 // 找到Method*并存储到%rcx中
0x00007fffe101ba0f: mov -0x18(%rbp),%rcx
// 找到method data pointer,如果为NULL就直接跳转
0x00007fffe101ba13: mov -0x20(%rbp),%rax
0x00007fffe101ba17: test %rax,%rax
0x00007fffe101ba1a: je 0x00007fffe101ba38 // 根据Method::_method_data获取到JumpData::taken_off_set偏移处属性的值并存储到%rbx中
0x00007fffe101ba20: mov 0x8(%rax),%rbx
// 增加DataLayout::counter_increment,值为1
0x00007fffe101ba24: add $0x1,%rbx
0x00007fffe101ba28: sbb $0x0,%rbx
// 存储回JumpData::taken_off_set偏移处
0x00007fffe101ba2c: mov %rbx,0x8(%rax) // %rax中存储的是method data pointer
// 根据method data pointer获取JumpData::displacement_off_set偏移处的值
0x00007fffe101ba30: add 0x10(%rax),%rax
// 将%rax中存储的值更新到栈中interpreter_frame_mdx_offset偏向处
0x00007fffe101ba34: mov %rax,-0x20(%rbp) // .... // **** not_takne **** // 如果method data pointer为NULL,就直接跳转到---- profile_continue ----
0x00007fffe101bd69: mov -0x20(%rbp),%rax
0x00007fffe101bd6d: test %rax,%rax
0x00007fffe101bd70: je 0x00007fffe101bd88 // 增加BranchData::not_taken_off_set=2处的值,加1
0x00007fffe101bd76: addq $0x1,0x18(%rax) // 根据method data pointer增加$0x20,也就是BranchData的大小
0x00007fffe101bd7b: sbbq $0x0,0x18(%rax)
0x00007fffe101bd80: add $0x20,%rax
0x00007fffe101bd84: mov %rax,-0x20(%rbp) // **** profile_continue ****
要注意,如上的method data pointer指向的是_data_index为0的位置的地址。对于BranchData来说,_cells数组的大小为3,分别存储着JumpData::taken_off_set、JumpData::displacement_off_set和BranchData::not_taken_off_set,所以会详细记录下相关指令的运行时具体数据,非常有利于后续编译器进行高级优化。
在介绍goto字节码指令时,调用的TemplateTable::branch()函数中会调用InterpreterMacroAssembler::profile_taken_branch()函数,生成的汇编代码如下:
// 如果开启了选项ProfileInterpreter,则执行分支跳转相关的性能统计 // %rax中保存着mdp(method data pointer)
0x00007fffe101dd14: mov -0x20(%rbp),%rax
// 如果Method::_method_data的值为NULL,则跳转到---- profile_continue ----
0x00007fffe101dd18: test %rax,%rax
0x00007fffe101dd1b: je 0x00007fffe101dd39 // 代码执行到这里时,表示Method::_method_data的值不为NULL // 根据Method::_method_data获取到JumpData::taken_off_set偏移处属性的值并存储到%rbx中
0x00007fffe101dd21: mov 0x8(%rax),%rbx
// 增加DataLayout::counter_increment,值为1
0x00007fffe101dd25: add $0x1,%rbx
// sbb是带借位减法指令
0x00007fffe101dd29: sbb $0x0,%rbx
// 存储回JumpData::taken_off_set偏移处
0x00007fffe101dd2d: mov %rbx,0x8(%rax) // %rax中存储的是method data pointer
// 根据method data pointer获取JumpData::displacement_off_set偏移处的值
0x00007fffe101dd31: add 0x10(%rax),%rax
// 将%rax中存储的值更新到栈中interpreter_frame_mdx_offset偏向处
0x00007fffe101dd35: mov %rax,-0x20(%rbp)
当Method::_method_data不为NULL时,会向MethodData::_data中记录控制转移的次数(注意这里是控制转移的次数,并不是回边的次数)。通过JumpData来记录,这个JumpData已经在MethodData::_data上的对应位置上并且已经进行了初始化,,在DataLayout::initialize()函数中初始化一些常用的属性,然后调用post_initialize()函数完成一些特定属性的初始化,下面看一下JumpData。
程序在使用过程中,经常需要在bci、bcp、method data pointer(栈中interpreter_frame_mdx_offset处存储的就是这个值)、data index。如bci转换为data index的函数如下:
int bci_to_di(int bci) {
address x = bci_to_dp(bci);
return dp_to_di(x);
}
首先要通过bci找到method data pointer,调用的函数如下:
address MethodData::bci_to_dp(int bci) {
ResourceMark rm;
ProfileData* data = data_before(bci);
ProfileData* prev = NULL;
for ( ; is_valid(data); data = next_data(data)) {
if (data->bci() >= bci) { // 如果进入这个循环,则一定会返回
if (data->bci() == bci){
int x = dp_to_di(data->dp());
set_hint_di(x);
}
else if (prev != NULL){
int x = dp_to_di(prev->dp());
set_hint_di(x);
}
return data->dp();
}
prev = data;
}
return (address)limit_data_position();
}
ProfileData* data_before(int bci) {
// avoid SEGV on this edge case
if (data_size() == 0){
return NULL;
}
int hint = hint_di();
if (data_layout_at(hint)->bci() <= bci){
return data_at(hint);
}
return first_data();
}
将method data pointer转换为data index的函数如下:
int dp_to_di(address dp) {
return dp - ((address)_data);
}
有时候,当Method::_method_data属性的值不为NULL时需要调用InterpreterRuntime::bcp_to_di()函数将bcp转换为data index,此函数的实现如下:
IRT_LEAF(jint, InterpreterRuntime::bcp_to_di(
Method* method,
address cur_bcp)
)
int bci = method->bci_from(cur_bcp);
MethodData* mdo = method->method_data();
if (mdo == NULL)
return 0;
return mdo->bci_to_di(bci);
IRT_END
首先调用bci_from()函数获取字节码索引bci,函数的实现如下:
int Method::bci_from(address bcp) const {
return bcp - code_base();
}
然后调用bci_to_di()函数即可。
公众号 深入剖析Java虚拟机HotSpot 已经更新虚拟机源代码剖析相关文章到60+,欢迎关注,如果有任何问题,可加作者微信mazhimazh,拉你入虚拟机群交流
第57篇-profile实例的更多相关文章
- (转)干货|这篇TensorFlow实例教程文章告诉你GANs为何引爆机器学习?(附源码)
干货|这篇TensorFlow实例教程文章告诉你GANs为何引爆机器学习?(附源码) 该博客来源自:https://mp.weixin.qq.com/s?__biz=MzA4NzE1NzYyMw==& ...
- Bluetooth篇 开发实例之九 和蓝牙模块通信
首先,我们要去连接蓝牙模块,那么,我们只要写客户端的程序就好了,蓝牙模块就相当于服务端. 连接就需要UUID. #蓝牙串口服务SerialPortServiceClass_UUID = ‘{00001 ...
- 深入理解ajax系列第四篇——请求实例
前面的话 在使用ajax的过程中,常用的请求方式是GET和POST两种.本文将以实例的形式来详细说明这两种请求方式 GET GET是最常见的请求类型,最常用于向服务器查询某些信息.必要时,可以将查询字 ...
- # hadoop入门第六篇:Hive实例
前言 前面已经讲了如何部署在hadoop集群上部署hive,现在我们就做一个很小的实例去熟悉HIVE QL.使用的数据是视频播放数据包括视频编码,播放设备编码,用户账号编码等,我们在这个数据基础上 ...
- Bluetooth篇 开发实例之八 匹配
自己写的App匹配蓝牙设备,不需要通过系统设置去连接. 匹配和通信是两回事. 用过Android系统设置(Setting)的人都知道蓝牙搜索之后可以建立配对和解除配对,但是这两项功能的函数没有在SDK ...
- Android Developer -- Bluetooth篇 开发实例之四 API详解
http://www.open-open.com/lib/view/open1390879771695.html 这篇文章将会详细解析BluetoothAdapter的详细api, 包括隐藏方法, 每 ...
- RobotFrameWork+APPIUM实现对安卓APK的自动化测试----第三篇【实例】
http://blog.csdn.net/deadgrape/article/details/50579565 在这一篇里我先让大家看一下RF+APPIUM这个框架的实际运行时什么样子的,给大家一个直 ...
- pytorch进行图像分类的流程,下一篇为实例源代码解析
一.预处理部分 1.拿到数据首先对数据进行分析 对数据的分布有一个大致的了解,可以用画图函数查看所有类的分布情况.可以采取删除不合理类的方法来提高准确率: 对图像进行分析,在自定义的图像增强的多种方式 ...
- Bluetooth篇 开发实例之十一 官网的Bluetooth Chat sample的bug
当没有匹配的设备和没有找到可用设备的时候. // If there are paired devices, add each one to the ArrayAdapter if (pairedDev ...
随机推荐
- java 图形化小工具Abstract Window Toolit 常用组件
基本组件 Button: 按钮,可接受单击操作 Canvas: 用于绘图的画布 Checkbox: 复选框组(也可变成单选框组件) CheckboxGroup: 用于将多个checkbox组件组合成一 ...
- Boost Asio要点概述(一)
[注]本文不是boost asio的完整应用讲述,而是仅对其中要点的讲解,主要参考了Boost Asio 1.68的官方文档(https://www.boost.org/doc/libs/1_68_0 ...
- SpringCloud(三) Zuul
Zuul 有了eureka . feign 和 hystrix 后,基本上就搭建了简易版的分布式项目,但仍存在一些问题,比如: 1.如果我们的微服务中有很多个独立服务都要对外提供服务,那么我们要如何去 ...
- vue-组件化编程
1.传统编写方式和组件编写方式的区别 组件方式编写可以很方便的复用和封装某些功能模块/组件的命名最好语义化,方便维护和阅读 编写时,我们可以将某些共用的功能或者样式部分抽象,得到对应的组件,按需要引入 ...
- c++ 设计模式概述之策略
代码写的不规范,目的是为了缩短文章篇幅,实际中请不要这样做. 1.概述 类比现实生活中的场景,比如,我需要一块8G内存条,我可以选择:A.去线下实体店买,B.线上购买,C.其他渠道. 再比如,吃饭餐具 ...
- 【LeetCode】377. Combination Sum IV 解题报告(Python & C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 日期 题目地址:https://leetcode.c ...
- 【LeetCode】804. Unique Morse Code Words 解题报告(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述: 题目大意 解题方法 set + map set + 字典 日期 题目地 ...
- Normalized Cuts and Image Segmentation
目录 概 主要内容 求解 相似度 总的算法流程 skimage.future.graph.cut Shi J. and Malik J. Normalized cuts and image segme ...
- 基于Java swing+mysql+eclipse的【图书管理系统】
本项目为Java swing项目,在工作环境中基本使用不到,但是很多学校把这个当做编程入门的项目来做,故分享出本项目供初学者参考. CSDN赞助下载:https://download.csdn.net ...
- 【HTML基础习题】HTML5+CSS3做问卷星登录页面
源代码下载地址:https://download.csdn.net/download/weixin_44893902/12839539 码云仓库地址: https://gitee.com/ynavc/ ...