Redis分布式锁实现原理
关于Redis分布式锁网上有很多优秀的博文,这篇文章仅作为我这段时间遇到的新问题的记录。
1.什么是分布式锁:
在单机部署的情况下,为了保证数据的一致性,不出现脏数据等,就需要使用synchronized关键字、semaphore、ReentrantLock或者我们可以基于AQS定制锁。锁是在多线程间共享;在分布式部署情况下,锁是在多进程间共享的;所以为了保证锁在多进程之间的唯一性,就需要实现锁在多进程之间的共享。
2.分布式锁的特性:
2.1要保证某个时刻中只有一个服务的一个方法获取到这个锁
2.2要保证是可重入锁(避免死锁)
2.3要保证锁的获取和释放的高可用。
3.分布式锁考虑的要点:
3.1需要在何时释放锁(finally)
3.2锁超时设置
3.3锁刷新设置(timeOut)
3.4如果锁超时了,为了避免误删了其他其他线程的锁,可以将当前线程的id存入redis中,当前线程释放锁的时候,需要判断存入redis的值是否为当前线程的id
3.5可重入
4.Redis分布式锁:
RedisLockRegistry是spring-integration-redis中提供Redis的实现类;主要通过redis锁+本地锁两个锁方式实现。
4.1在pomx.xml文件中导入spring-integration-redis的依赖:
<!-- 分布式锁支持 start-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-integration</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.integration</groupId>
<artifactId>spring-integration-redis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- 分布式锁支持 end-->
4.2 RedisLockRegistry类主要内部结构如图:
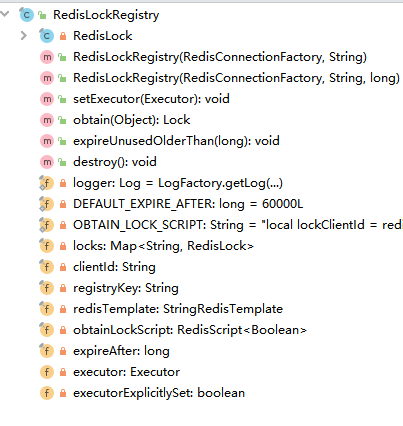
RedisLockRegistry类的静态String的常量OBTAIN_LOCK_SCRIPT是RedisLockRegistry类的一个上锁的lua脚本。KEYS[1]代表当前锁的key值,ARGV[1]代表当前的客户端标识,ARGV[2]代表过期时间。
private static final String OBTAIN_LOCK_SCRIPT = "local lockClientId = redis.call('GET', KEYS[1])\n"+
"if lockClientId == ARGV[1] then\n"+
"redis.call('PEXPIRE', KEYS[1], ARGV[2])\n"+
"return true\n"+
"elseif not lockClientId then\n"+
"redis.call('SET', KEYS[1], ARGV[1], 'PX', ARGV[2])\n"+
"return true\n"+
"end\n"+
"return false";
基本逻辑就是:拿着KEYS[1]去redis中获取值,如果值等于ARGV[1]就表示这条数据已经被上锁了,并且延长锁的过期时间,如果想要获取锁锁就要等待拿到锁的进程释放锁;如果这个键KEYS[1]不存在,那么设置KEYS[1]的值为ARGV[1],并且设置过期时间为ARGV[2],即当前进程就获取到这个数据的锁,并设置过期时间。(对lua脚本和redis命令不熟悉的可以上redis中文网)
4.3RedisLockRegistry类的内部类RedisLock的结构如下:
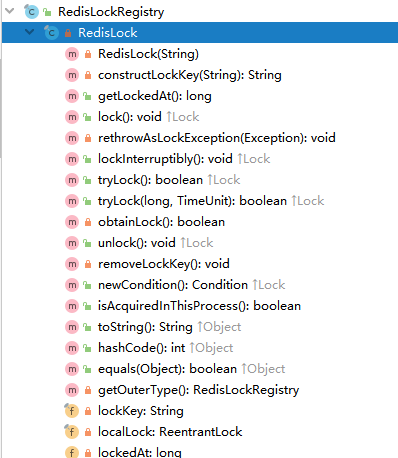
RedisLockRegistry类中获取锁的方法:
......
private final Map<String, RedisLockRegistry.RedisLock> locks;
......
public Lock obtain(Object lockKey) {
Assert.isInstanceOf(String.class, lockKey);
String path = (String)lockKey;
return (Lock)this.locks.computeIfAbsent(path, (x$0) -> {
return new RedisLockRegistry.RedisLock(x$0);
});
}
如上面代码显示,locks是RedisLockRegistry类的Map类型的常量,以String类型作为key,以RedisLockRegistry的内部类RedisLock作为value;
拿着lockKey作为key去这个map中查找是否已经存在(即这条数据是否已经上锁),如果存在就返回这个lockKey对应的RedisLock,如果不存在就创建一个RedisLock并将其以此lockKey为key放入map中。
每个分布式部署的应用都会自己创建一个RedisLockRegistry实例,到这里,同一个应用的多个线程都可以获取到这条共享数据的RedisLock对象,本地锁+Redis锁真正开始于调用通过RedisLockRegistry实例.obtain(lockKey)方法获取到的RedisLock实例对象.trylock()方法,参见下文。
4.4RedisLockRegistry类的内部类的属性和部分构造方法:
private final class RedisLock implements Lock {
private final String lockKey;
private final ReentrantLock localLock;
//用于记录上锁的时间
private volatile long lockedAt;
private RedisLock(String path) {
this.localLock = new ReentrantLock();
this.lockKey = this.constructLockKey(path);
}
......
}
public boolean tryLock(long time, TimeUnit unit) throws InterruptedException {
long now = System.currentTimeMillis();
if (!this.localLock.tryLock(time, unit)) {
return false;
} else {
try {
long expire = now + TimeUnit.MILLISECONDS.convert(time, unit);
boolean acquired;
while(!(acquired = this.obtainLock()) && System.currentTimeMillis() < expire) {
Thread.sleep(100L);
}
if (!acquired) {
this.localLock.unlock();
}
return acquired;
} catch (Exception var9) {
this.localLock.unlock();
this.rethrowAsLockException(var9);
return false;
}
}
}
private boolean obtainLock() {
Boolean success = (Boolean)RedisLockRegistry.this.redisTemplate.execute(RedisLockRegistry.this.obtainLockScript, Collections.singletonList(this.lockKey), new Object[]{RedisLockRegistry.this.clientId, String.valueOf(RedisLockRegistry.this.expireAfter)});
boolean result = Boolean.TRUE.equals(success);
if (result) {
this.lockedAt = System.currentTimeMillis();
}
return result;
}
redisTemplate的execute方法参数:
第一个参数就是要执行的lua脚本;
第二个参数就是表示在脚本中所用到的那些 Redis 键(key),这些键名参数可以在 Lua 中通过全局变量 KEYS 数组,用 1 为基址的形式访问( KEYS[1] , KEYS[2] ,以此类推);
第三个参数那些不是键名参数的附加参数 arg [arg …] ,可以在 Lua 中通过全局变量 ARGV 数组访问,访问的形式和 KEYS 变量类似( ARGV[1] 、 ARGV[2] ,诸如此类)
分析tryLock源码可以看出,首先获取本地锁,如果获取失败,即表示某个请求线程已经获取到了锁,直接返回false;如果获取成功,就调用obtainLock方法执行OBTAIN_LOCK_SCRIPT这段lua脚本来获取redis锁,判断其他进程的某个请求线程获取到了这个redis锁,如果获取redis失败,则acquired变量为false,同时释放本地锁,tryLock方法直接返回false,获取锁失败。
为什么要用本地锁?一个是为了可重入,另一个是为了减轻redis服务器的压力。
4.5 释放锁:
public void unlock() {
if (!this.localLock.isHeldByCurrentThread()) {
throw new IllegalStateException("You do not own lock at " + this.lockKey);
} else if (this.localLock.getHoldCount() > 1) {
this.localLock.unlock();
} else {
try {
if (!this.isAcquiredInThisProcess()) {
throw new IllegalStateException("Lock was released in the store due to expiration. The integrity of data protected by this lock may have been compromised.");
}
if (Thread.currentThread().isInterrupted()) {
RedisLockRegistry.this.executor.execute(this::removeLockKey);
} else {
this.removeLockKey();
}
if (RedisLockRegistry.logger.isDebugEnabled()) {
RedisLockRegistry.logger.debug("Released lock; " + this);
}
} catch (Exception var5) {
ReflectionUtils.rethrowRuntimeException(var5);
} finally {
this.localLock.unlock();
}
}
}
释放锁的过程也比较简单,第一步通过本地锁判断当前线程是否持有锁,第二步通过本地锁判断当前线程持有锁的计数。
如果当前线程持有锁的计数 > 1,说明本地锁被当前线程多次获取,这时只释放本地锁(释放之后当前线程持有锁的计数-1)。
如果当前线程持有锁的计数 = 1,释放本地锁和redis锁。
redis分布式锁的使用参见另一篇博文:springboot实现分布式锁
Redis分布式锁实现原理的更多相关文章
- Redlock(redis分布式锁)原理分析
Redlock:全名叫做 Redis Distributed Lock;即使用redis实现的分布式锁: 使用场景:多个服务间保证同一时刻同一时间段内同一用户只能有一个请求(防止关键业务出现并发攻击) ...
- Redis分布式锁的原理和实现
前言 我们之前聊过redis的,对基础不了解的可以移步查看一下: 几分钟搞定redis存储session共享--设计实现:https://www.cnblogs.com/xiongze520/p/10 ...
- 关于redis分布式锁实现原理
具体详情 http://www.cnblogs.com/SUNSHINEC/p/8302540.html
- 《Redis 分布式锁》
一:什么是分布式锁. - 通俗来说的话,就是在分布式架构的redis中,使用锁. 二:分布式锁的使用选择. - 当 Redis 的使用场景不多,而且也只是单个在用的时候,可以构建自己使用的 锁. - ...
- 分布式-技术专区-Redis分布式锁实现-第一步
承接前面一篇Redis分布式锁的原理介绍 https://www.cnblogs.com/liboware/p/11921759.html 我们针对于实现方案进行接下来上篇进行重新的规划和定义以及完善 ...
- 手撕redis分布式锁,隔壁张小帅都看懂了!
前言 上一篇老猫和小伙伴们分享了为什么要使用分布式锁以及分布式锁的实现思路原理,目前我们主要采用第三方的组件作为分布式锁的工具.上一篇运用了Mysql中的select ...for update实现了 ...
- 面试必问:如何实现Redis分布式锁
摘要:今天我们来聊聊分布式锁这块知识,具体的来看看Redis分布式锁的实现原理. 一.写在前面 现在面试,一般都会聊聊分布式系统这块的东西.通常面试官都会从服务框架(Spring Cloud.Dubb ...
- 循序渐进 Redis 分布式锁(以及何时不用它)
场景 假设我们有个批处理服务,实现逻辑大致是这样的: 用户在管理后台向批处理服务投递任务: 批处理服务将该任务写入数据库,立即返回: 批处理服务有启动单独线程定时从数据库获取一批未处理(或处理失败)的 ...
- 关于分布式锁原理的一些学习与思考-redis分布式锁,zookeeper分布式锁
首先分布式锁和我们平常讲到的锁原理基本一样,目的就是确保,在多个线程并发时,只有一个线程在同一刻操作这个业务或者说方法.变量. 在一个进程中,也就是一个jvm 或者说应用中,我们很容易去处理控制,在j ...
随机推荐
- 使用JavaScript 中的Math对象和勾股定理公式,计算鼠标的位置与页面图片中心点的距离,根据距离对页面上的图片进行放大或缩小处理。距离远时图片放大,距离近时图片缩小
查看本章节 查看作业目录 需求说明: 使用JavaScript 中的Math对象和勾股定理公式,计算鼠标的位置与页面图片中心点的距离,根据距离对页面上的图片进行放大或缩小处理.距离远时图片放大,距离近 ...
- 编写Java程序,随机给定一个数字猜大小
返回本章节 返回作业目录 需求说明: 由系统随机生成一个1~100之间的整数. 通过控制台一直输入一个整数,比较该数与系统随机生成的那个数,如果大就输出"猜大了.",继续输入:如果 ...
- [学习笔记] Oracle创建用户、分配权限、设置角色
创建用户 create user student --用户名 identified by "123456" --密码 default tablespace USERS --表空间名 ...
- 大厂必问的Java集合面试题
本文目录: 常见的集合有哪些? List .Set和Map 的区别 ArrayList 了解吗? ArrayList 的扩容机制? 怎么在遍历 ArrayList 时移除一个元素? Arraylist ...
- Flask_Flask-Migrate数据迁移扩展(十二)
在开发过程中,需要修改数据库模型,而且还要在修改之后更新数据库.最直接的方式就是删除旧表,但这样会丢失数据.更好的解决办法是使用数据库迁移框架,它可以追踪数据库模式的变化,然后把变动应用到数据库中. ...
- 使用 try-catch
ECMA-262 第 3 版引入了 try-catch 语旬,当 try-catch 语句中发生错误时, 浏览器会认为错误已经被处理了 ,因而不会报告错误.对于那些不要求用户懂技术,也不需要用户理解错 ...
- 第10组 Beta冲刺 (1/5)(组长)
1.1基本情况 ·队名:今晚不睡觉 ·组长博客:https://www.cnblogs.com/cpandbb/p/14012521.html ·作业博客:https://edu.cnblogs.co ...
- CSS相关知识及入门
CSS(层叠样式表) 作用 修饰HTML页面,美化 CSS代码规范 放置规范 在<style>标签内容体中书写样式代码 <style>标签放置在<head>标签内. ...
- sql创建表格时出现乱码
1.新建数据库时,第一次只填写了数据库名称保存数据库,如下图: 2.创建一个Student表格,代码如下,其中有数据有中文,创建完后查看表格数据,发现中文为乱码 create table Studen ...
- Solon 开发,三、构建一个Bean的三种方式
Solon 开发 一.注入或手动获取配置 二.注入或手动获取Bean 三.构建一个Bean的三种方式 四.Bean 扫描的三种方式 五.切面与环绕拦截 六.提取Bean的函数进行定制开发 七.自定义注 ...