MySQL单表查询(分组-筛选-过滤-去重-排序)
一:单表查询
1.单表查询(前期准备)
create table emp(
id int primary key auto_increment,
name varchar(20) not null,
sex enum('male','female') not null default 'male', # 用户如不输入 默认男的
age int(3) unsigned not null default 28, # 用户如不输入 默认28
hire_date date not null, # 雇佣日期
post varchar(50), # 职业
post_comment varchar(100), # 员工描述
salary double(15,2), # 薪水
office int, #一个部门一个屋子
depart_id int # 编号
);
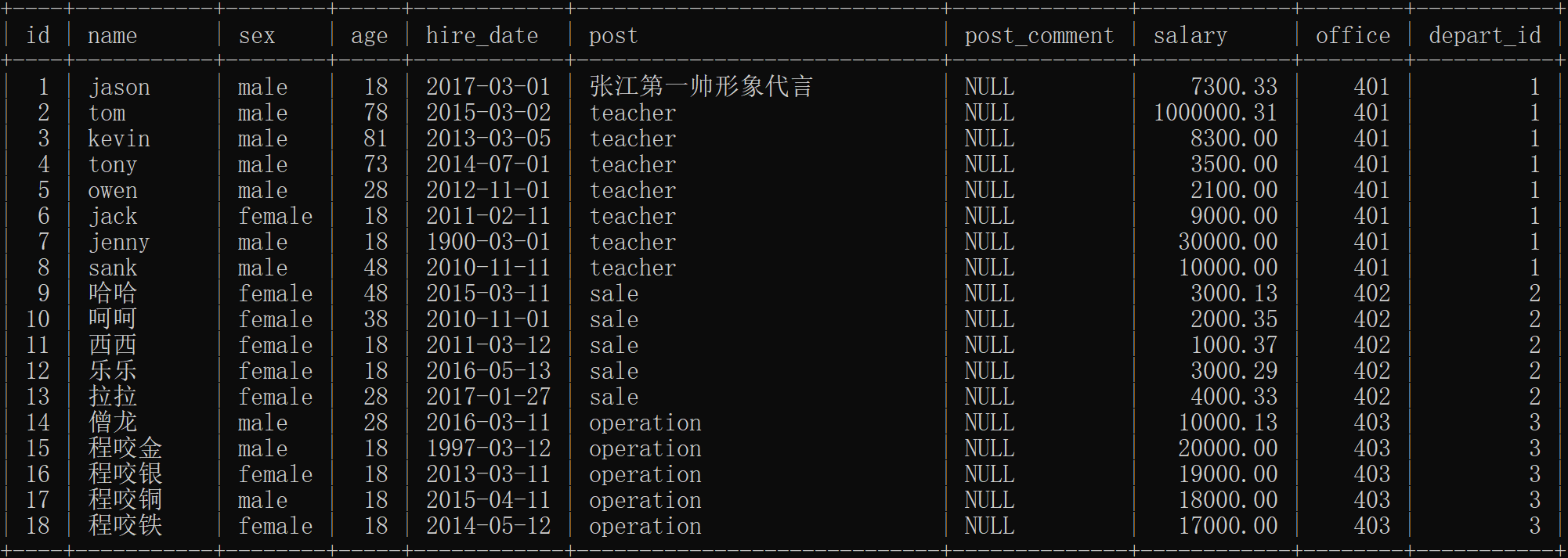
2.插入记录(写入数据)
- 三个部门:
教学,销售,运营
insert into emp(name,sex,age,hire_date,post,salary,office,depart_id) values
('jason','male',18,'20170301','张江第一帅形象代言',7300.33,401,1),
# 以下是教学部
('tom','male',78,'20150302','teacher',1000000.31,401,1),
('kevin','male',81,'20130305','teacher',8300,401,1),
('tony','male',73,'20140701','teacher',3500,401,1),
('owen','male',28,'20121101','teacher',2100,401,1),
('jack','female',18,'20110211','teacher',9000,401,1),
('jenny','male',18,'19000301','teacher',30000,401,1),
('sank','male',48,'20101111','teacher',10000,401,1),
('哈哈','female',48,'20150311','sale',3000.13,402,2),
#以下是销售部门
('呵呵','female',38,'20101101','sale',2000.35,402,2),
('西西','female',18,'20110312','sale',1000.37,402,2),
('乐乐','female',18,'20160513','sale',3000.29,402,2),
('拉拉','female',28,'20170127','sale',4000.33,402,2),
('僧龙','male',28,'20160311','operation',10000.13,403,3),
#以下是运营部门
('程咬金','male',18,'19970312','operation',20000,403,3),
('程咬银','female',18,'20130311','operation',19000,403,3),
('程咬铜','male',18,'20150411','operation',18000,403,3),
('程咬铁','female',18,'20140512','operation',17000,403,3);
3.查询关键字
select
控制查询表中的哪些字段对应的数据
from
控制查询的表
- 结合使用:
select * from t1;
作用:
查询t1表内所以记录
select name from t1;
作用:
查询t1表内name字段
二:查询关键字之where
关键字: where
作用:
其实就是对数据进行筛选
1.查询id大于等于3小于等于6的数据
select id,name from emp where id >= 3 and id <= 6;
select id,name from emp where id between 3 and 6; # 简写
between :选取介于两个值之间的数据范围内的值
2.查询薪资是20000或者18000或者17000的数据
select * from emp where salary = 20000 or salary = 18000 or salary = 17000;
select * from emp where salary in (20000,18000,17000); # 简写
3.模糊查询(like)
模糊查询
关键字 like
模糊查询应用场景:
当查询对象(名称不全)(数字不全)(不确定内容)时,可以使用模糊查询。
关键符号:
% : 匹配任意个数的任意字符
_ : 匹配单个 个数的任意字符
4.查询员工姓名中包含o字母的员工姓名和薪资
select name,salary from emp where name like '%o%';
5.查询员工姓名为四个字符组成的员工姓名和薪资
select name,salary from emp where name like '____';
select name,salary from emp where char_length(name) = 4;
6.查询id小于3或者大于6的数据
select * from emp where id not between 3 and 6;
7.查询薪资不在20000,18000,17000范围的数据
select * from emp where salary not in (20000,18000,17000);
8.(查询岗位描述为空的员工名与岗位名) 针对null不能用等号,只能用is(才能查询到)
select name,post from emp where post_comment = NULL; # 查询为空!
select name,post from emp where post_comment is NULL;
select name,post from emp where post_comment is not NULL;
三:查询关键字之group by分组
1.什么是分组?
按照某个指定的条件将单个单个的数据分为一个个整体
- 分组
咱班按照座位横向分组
咱班按照年龄分组
咱班按照省份分组
2.应用场景
求每个部门的平均薪资
求每个国家的人均GDP
求男女平均薪资
3.如何对数据进行分组?
关键字 group by 条件
4.实现分组
分组之后不再以单个个体为研究对象 也无法直接再获取单个个体的数据
研究对象应该是分组的整体
解析:
分组之后获取是(部门整体)而不是(个体)
分组之后默认只能直接获取到分组的依据 其他字段数据无法直接获取
解析:
使用(post/部门)进行分组的,使用slect只能以post来做分组
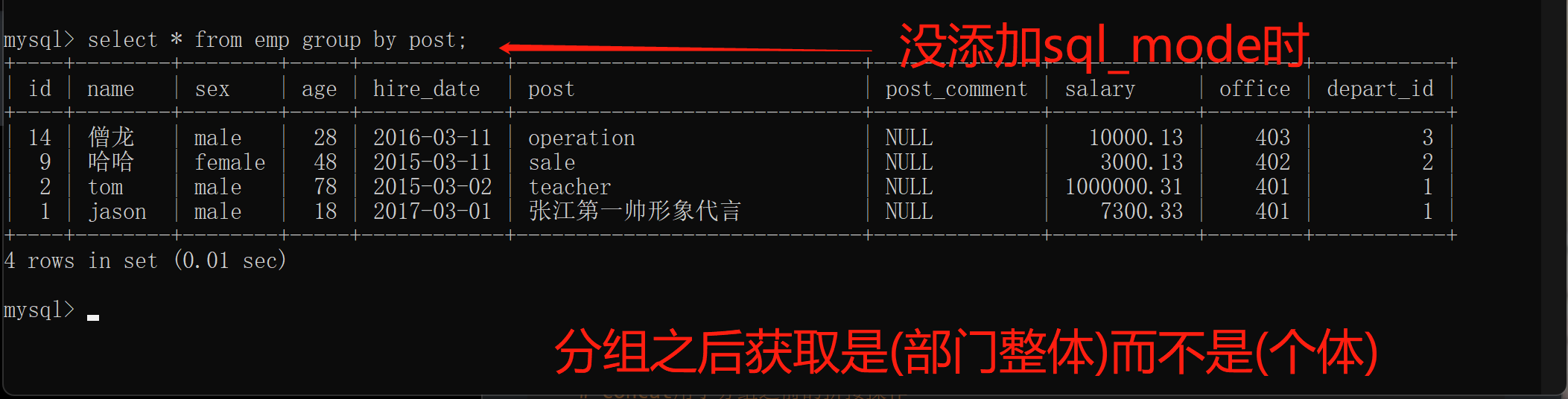
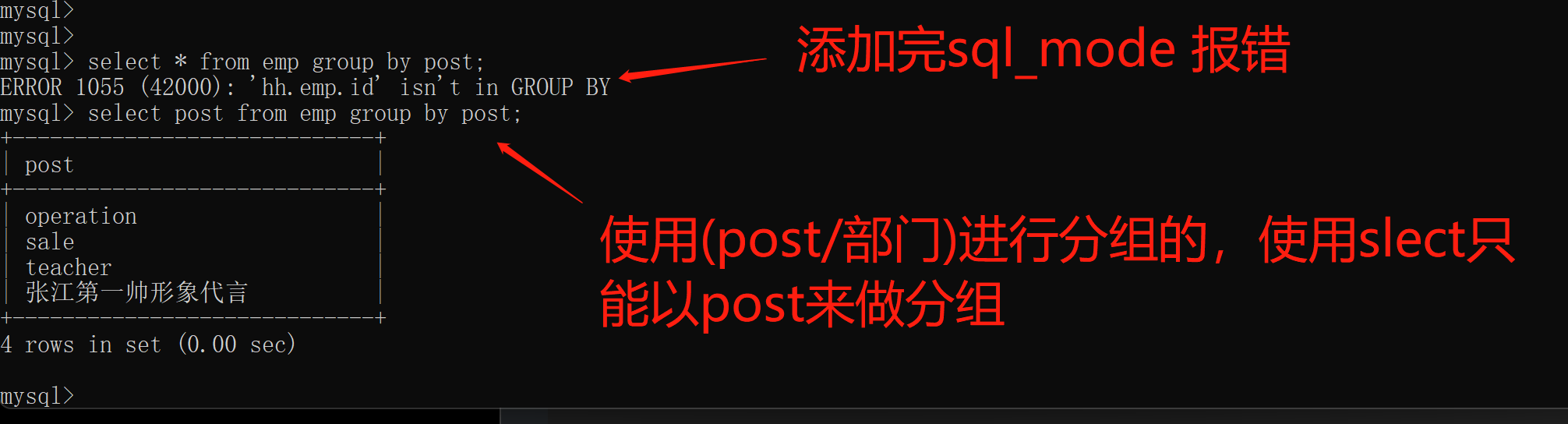
如果需要实现上述要求 还是修改sql_mode
set global sql_mode='only_full_group_by';
修改完后重新登录MySQL
exit
注意:
分组之后默认只能直接获取到分组的依据 其他字段数据无法直接获取
5.聚合函数
max() : 求最大值
min() : 求最小值
sum() : 求合
count() : 计数
avg() : 平均值
# 上述聚合函数都是在分组之后使用 用于操作整体数据
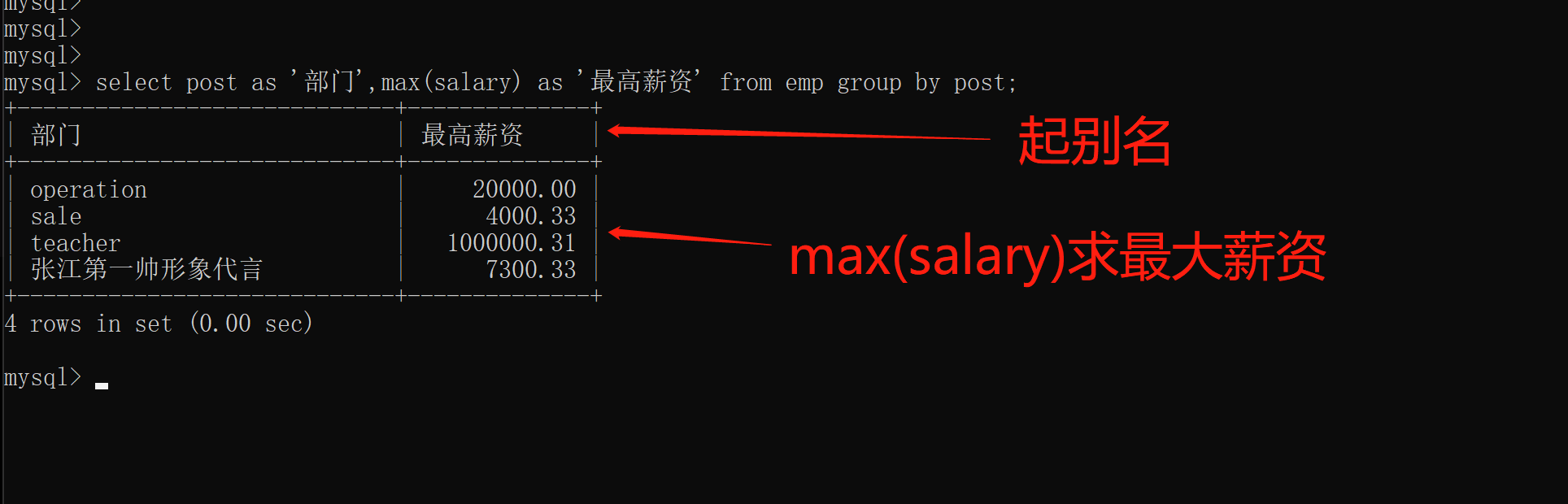
6.as语法(起别名)
as语法在查看结果的时候可以给字段起别名
格式:
select post as '部门',max(salary) as '最高薪资' from emp group by post;
省略as:
select post '部门',max(salary) '最高薪资' from emp group by post;
注意:
as可以省略但是为了语义更加明确建议不要省略
四:分组实战案例
1.获取每个部门的最大薪资
select post '部门',max(salary) '最高薪资' from emp group by post;
获取每个部门的最低薪资
select post '部门',min(salary) '最低薪资' from emp group by post;
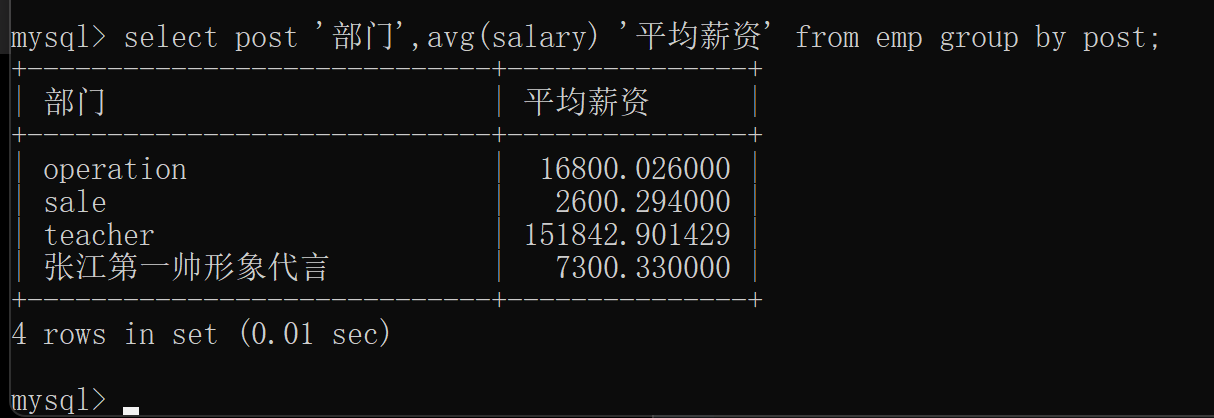
统计每个部门的平均薪资(平均薪资不客观 客观表现(中位数))
select post '部门',avg(salary) '平均薪资' from emp group by post;
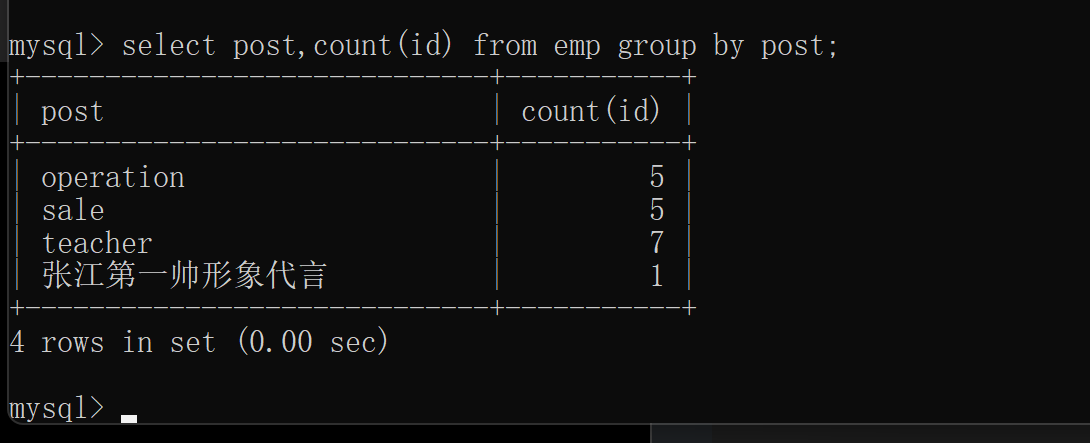
2.统计每个部门的人数
select post,count(id) from emp group by post;
count(id) : count()只是计数 不是针对括号内的id字段
3.获取每个部门的员工姓名(拼接)
select post,group_concat(name) from emp group by post;

获取每个部门的员工姓名(分组之后拼接)
select post,group_concat(name,'|',salary) from emp group by post;
group_concat 用于分组之后获取分组以外的字段数据并支持拼接(间接拿)

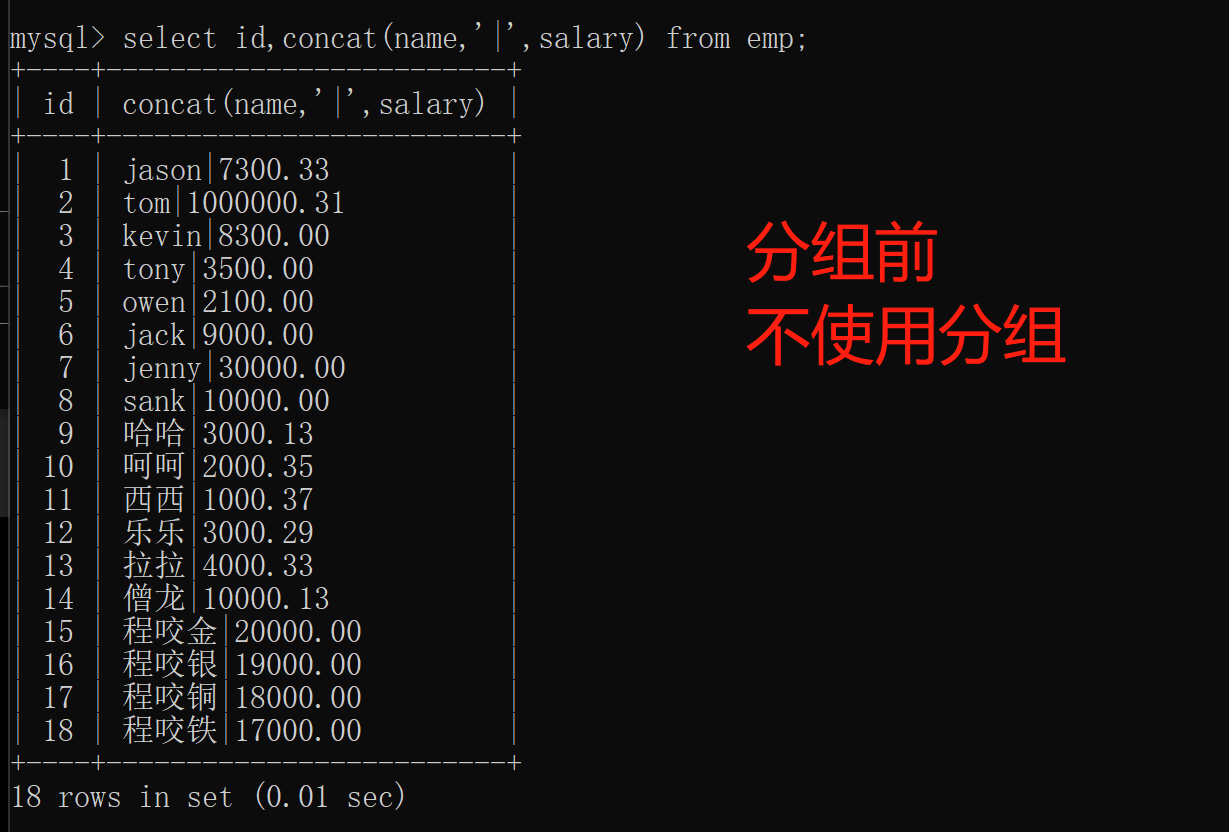
获取员工姓名(分组之前拼接)
select id,concat(name,'|',salary) from emp;
concat 用于分组之前的拼接操作
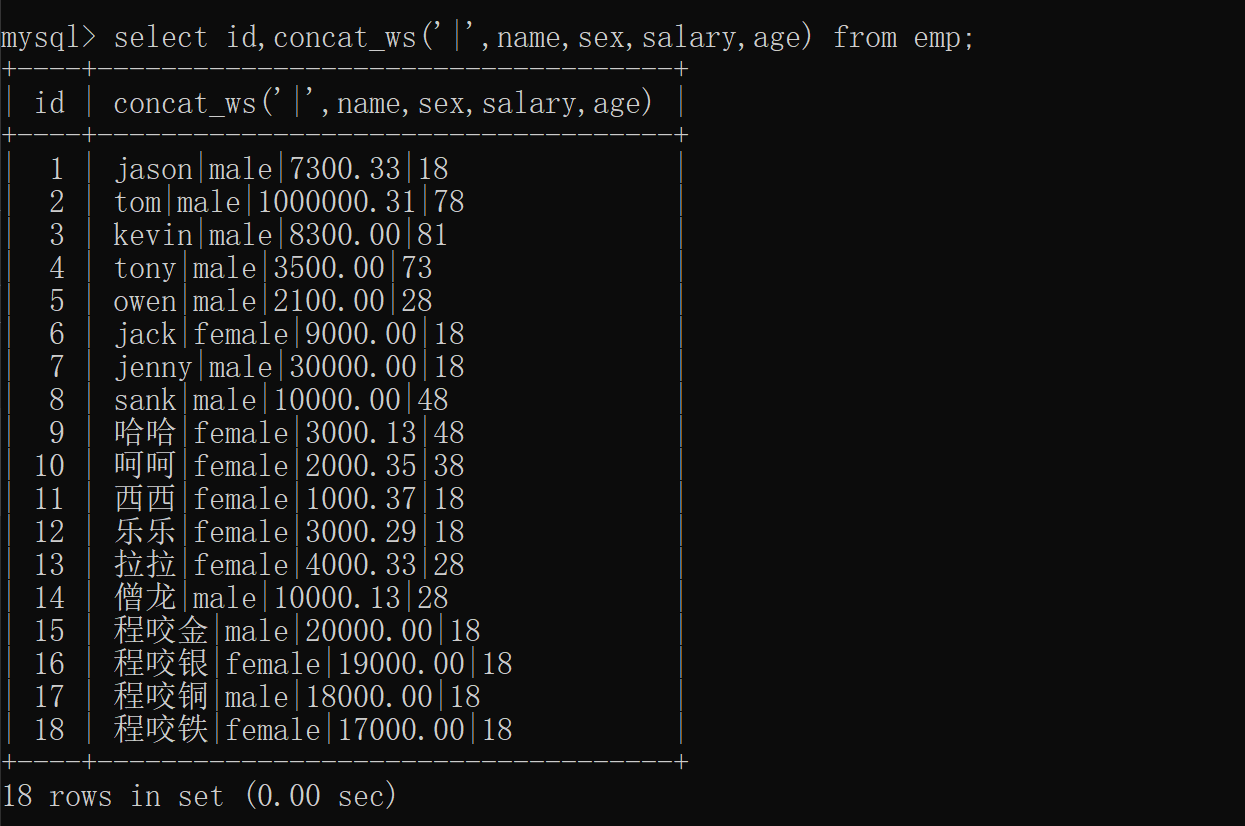
获取多个字段(简写分隔符)分组前
select id,concat_ws('|',name,sex,salary,age) from emp;
concat_ws 当多个字段连接符相同的情况下推荐使用
五;查询关键字之having过滤
1.where与having区别
where与having都是用来筛选数据的
但是where用于分组之前的筛选
having用于分组之后的筛选
为了人为的区分开 我们将where用筛选来形容 having用过滤来形容
2.having过滤案例
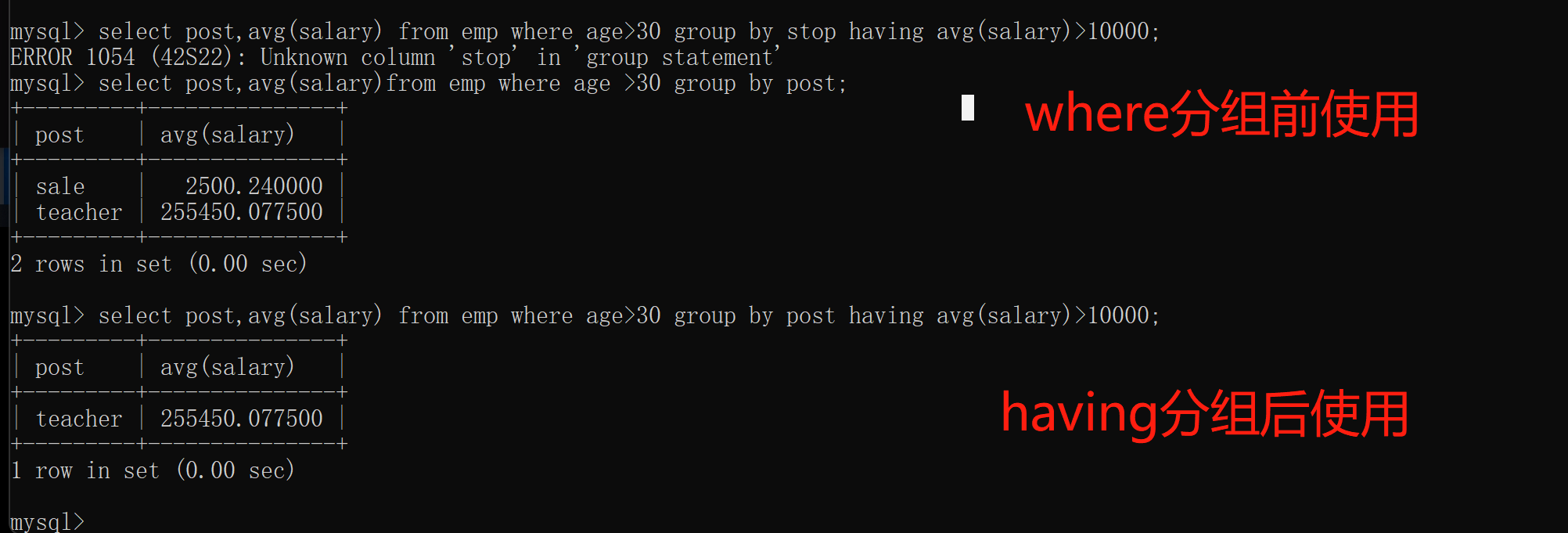
统计各部门年龄在30岁以上的员工平均工资,并且保留平均工资大于10000的部门
将一个复杂的查询题拆分成多个简单的小题:
1.查看整张表的内容: select * from emp;
2.统计年龄在30岁以上的员工: select * from emp where age > 30;
3.给各个部门进行分组: select post from emp group by post;
4.计算各部门的平均薪资: select post,avg(salary) from emp group by post
5.各部门30岁以上的平均薪资: select post,avg(salary) from emp where age > 30 group by post;
6.使用having(分组之后)过滤,并且保留平均工资大于10000的部门:
select post,avg(salary) from emp where age > 30 group by post having avg(salary)>10000;
六:查询关键字之distinct去重
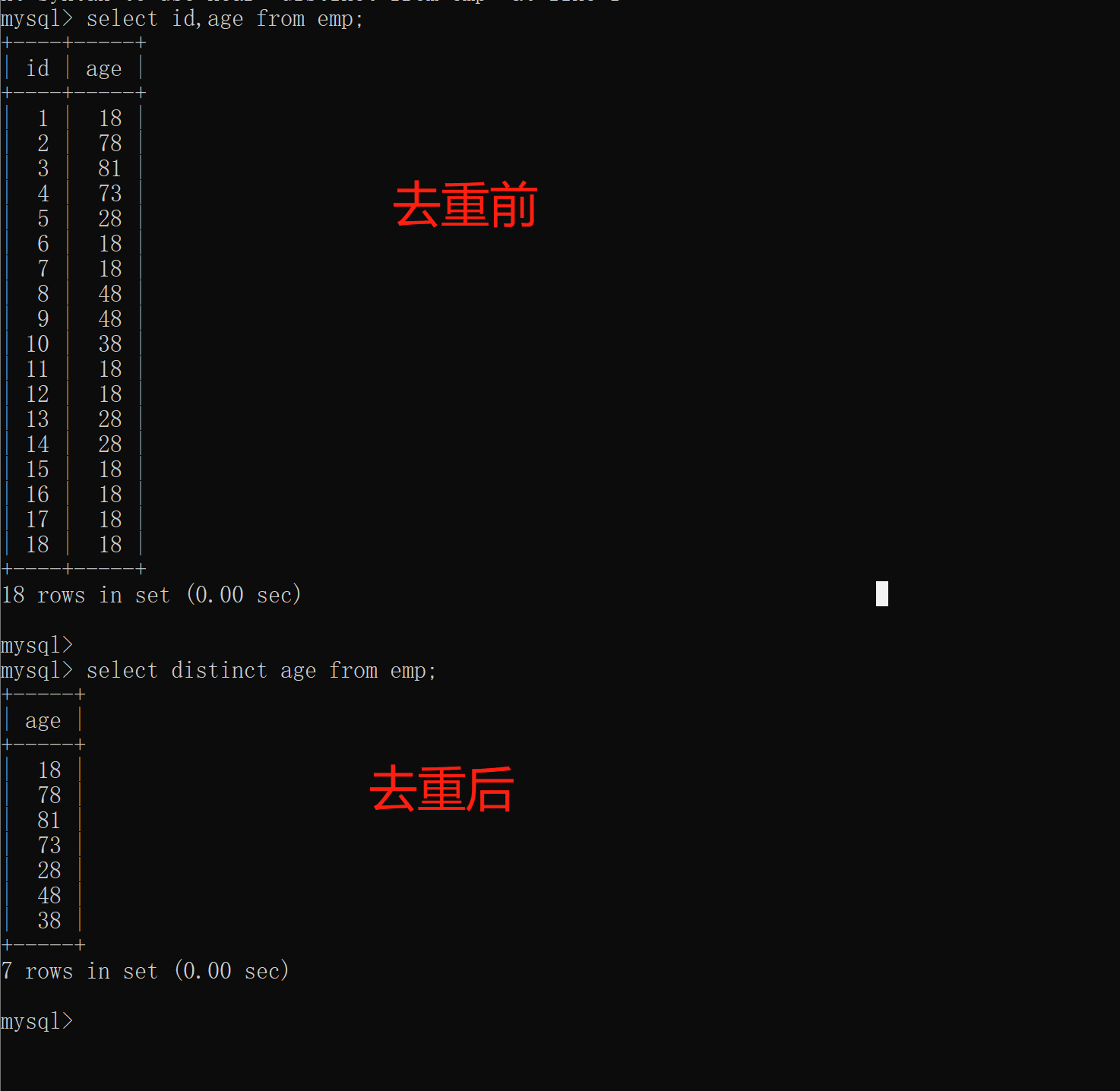
1.distinct去重
1.去重的前提示是存在一模一样的数据
2.如果存在主键肯定无法去重(主键是 非空且唯一)
2.对有重复的展示数据进行去重操作 一定要是重复的数据
select distinct id,age from emp; # 无效果
select distinct id,age distinct from emp; # 报错
select distinct age from emp;
七:查询关键字之order by排序
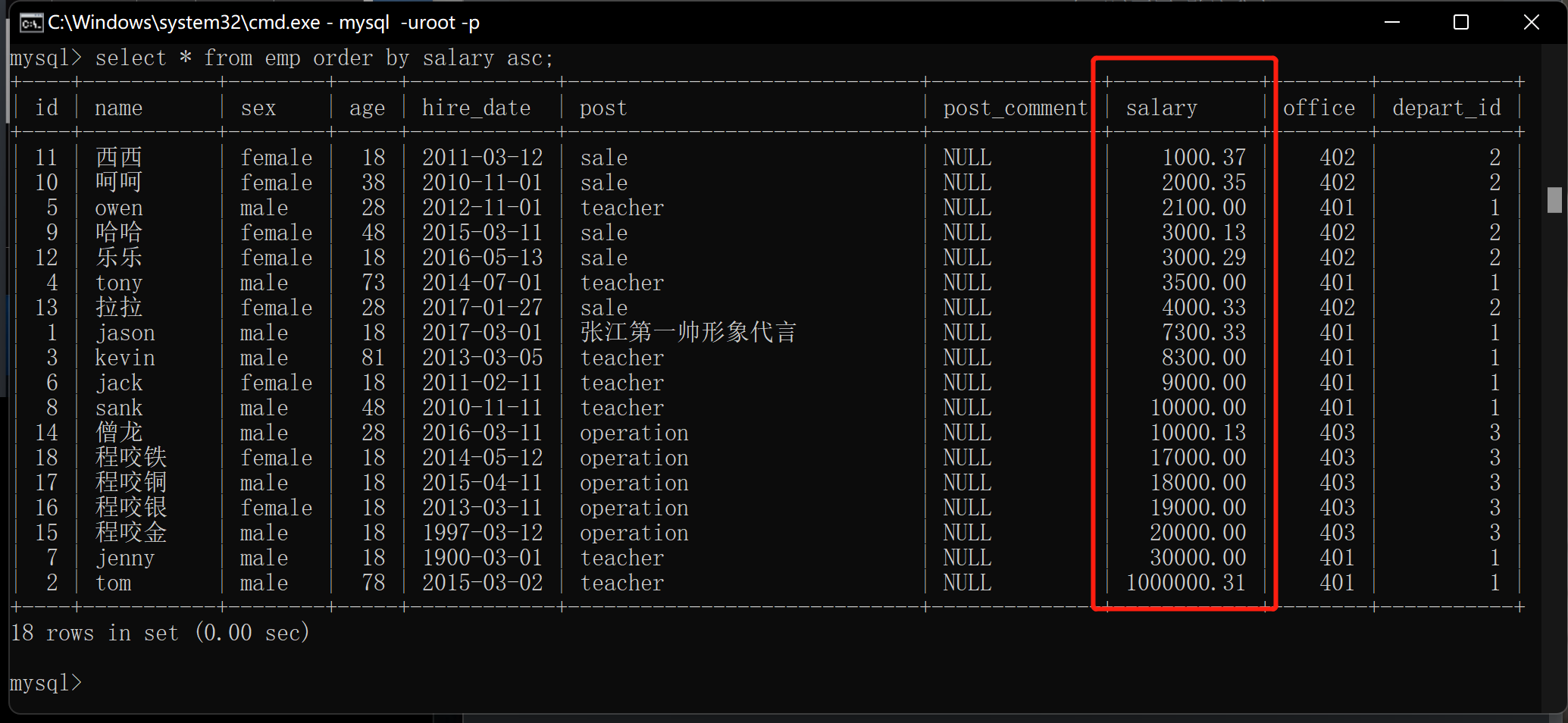
1.关键字order by 排序
order by默认是升序 默认的关键字是asc
升序 : asc
降序 : desc
2.薪资由低到高排序(升序)
select * from emp order by salary asc; # 也可以不写 默认升序
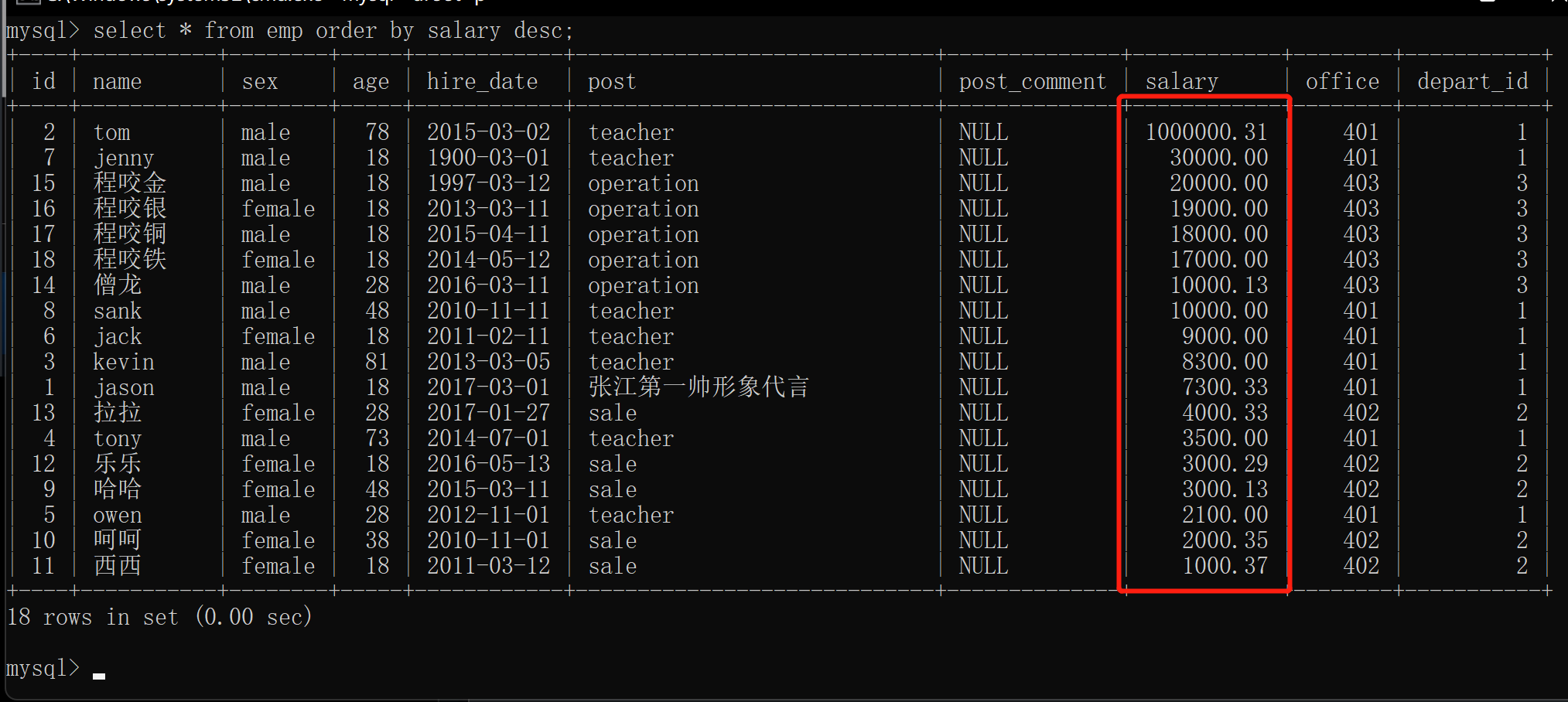
3.薪资由高到低排序(降序)
select * from emp order by salary desc; # 降序
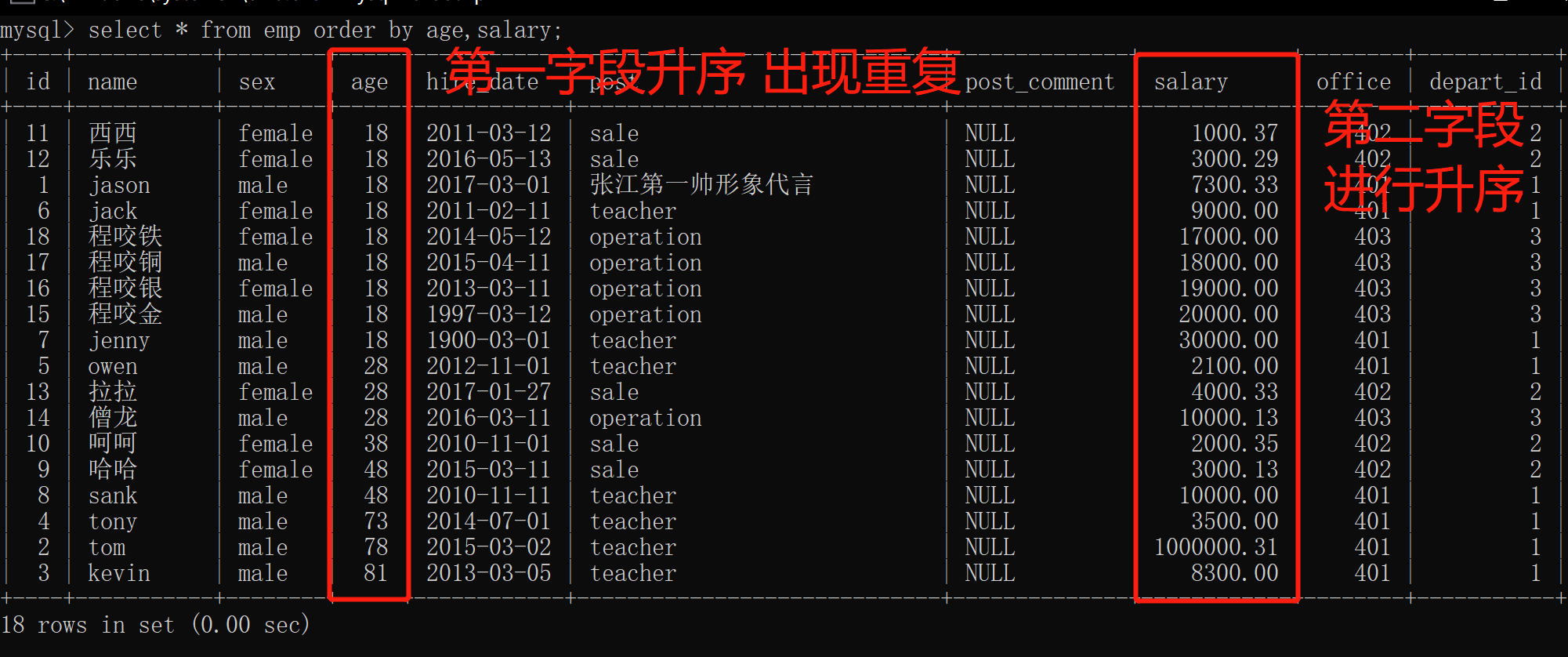
4.order by排序支持多个字段组合(第一个不行 就往后继续排)
解析:
第一个字段排序出现重复时,会从第二个字段排序进行升序比较
select * from emp order by age,salary;
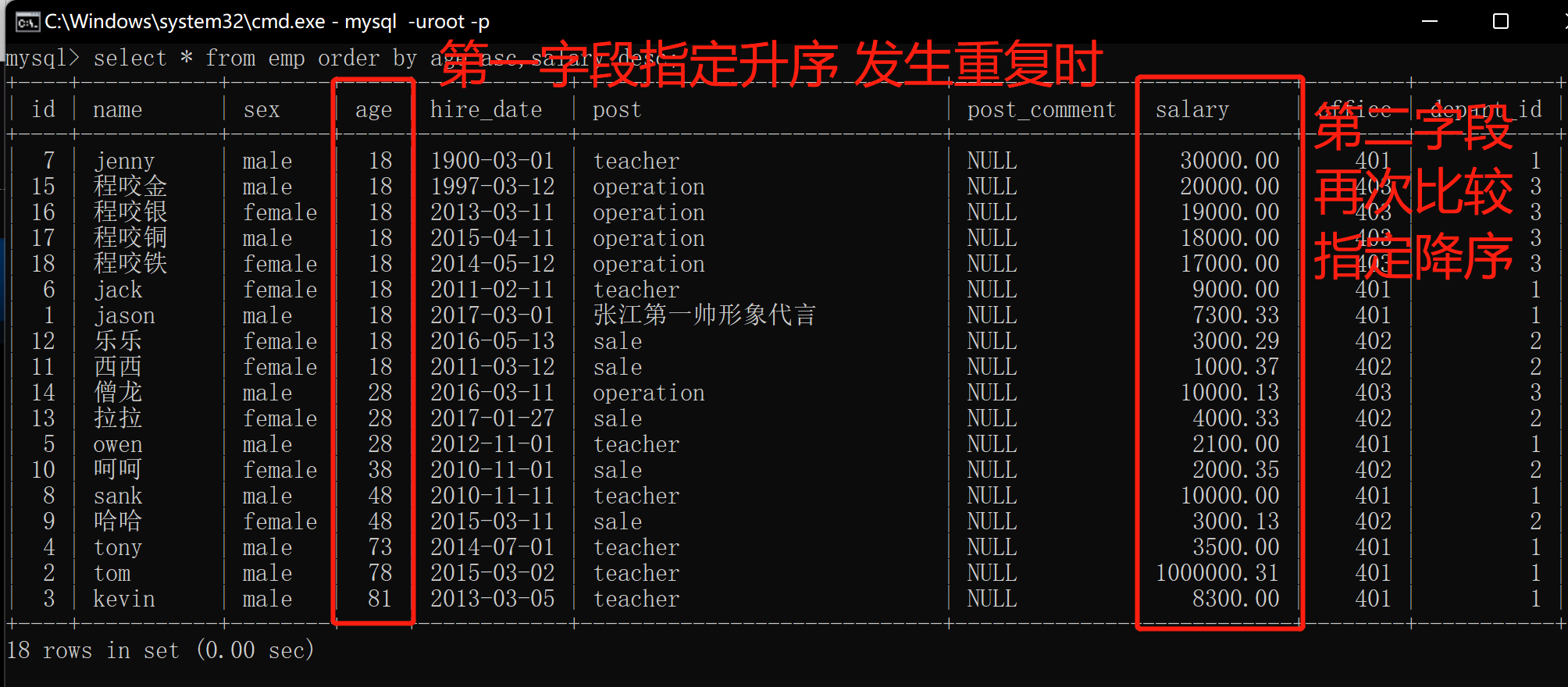
5.order by(多段排序 指定排序)
作用:
可以多段排序,可以给多段排序指定(升序 或 降序)
select * from emp order by age asc,salary desc;
MySQL单表查询(分组-筛选-过滤-去重-排序)的更多相关文章
- mysql——单表查询——分组查询——示例
一.基本查询语句 select的基本语法格式如下: select 属性列表 from 表名和视图列表 [ where 条件表达式1 ] [ group by 属性名1 [ having 条件表达式2 ...
- python 3 mysql 单表查询
python 3 mysql 单表查询 1.准备表 company.employee 员工id id int 姓名 emp_name varchar 性别 sex enum 年龄 age int 入职 ...
- day04 mysql单表查询 多表查询 pymysql的使用
day04 mysql pymysql 一.单表查询 1.having过滤 一般用作二次筛选 也可以用作一次筛选(残缺的: 只能筛选select里面 ...
- Mysql 单表查询-排序-分页-group by初识
Mysql 单表查询-排序-分页-group by初识 对于select 来说, 分组聚合(((group by; aggregation), 排序 (order by** ), 分页查询 (limi ...
- Mysql 单表查询 子查询 关联查询
数据准备: ## 学院表create table department( d_id int primary key auto_increment, d_name varchar(20) not nul ...
- Mysql 单表查询where初识
Mysql 单表查询where初识 准备数据 -- 创建测试库 -- drop database if exists student_db; create database student_db ch ...
- python mysql 单表查询 多表查询
一.外键 变种: 三种关系: 多对一 站在左表的角度: (1)一个员工 能不能在 多个部门? 不成立 (2)多个员工 能不能在 一个部门? 成立 只要有一个条件成立:多 对 一或者是1对多 如果两个条 ...
- mysql 单表查询
一 单表查询的语法 SELECT 字段1,字段2... FROM 表名 WHERE 条件 GROUP BY field HAVING 筛选 ORDER BY field LIMIT 限制条数 二 ...
- SQL学习笔记四(补充-1)之MySQL单表查询
阅读目录 一 单表查询的语法 二 关键字的执行优先级(重点) 三 简单查询 四 WHERE约束 五 分组查询:GROUP BY 六 HAVING过滤 七 查询排序:ORDER BY 八 限制查询的记录 ...
随机推荐
- 【九度OJ】题目1109:连通图 解题报告
[九度OJ]题目1109:连通图 解题报告 标签(空格分隔): 九度OJ 原题地址:http://ac.jobdu.com/problem.php?pid=1109 题目描述: 给定一个无向图和其中的 ...
- 【剑指Offer】反转链表 解题报告(Python)
[剑指Offer]反转链表 解题报告(Python) 标签(空格分隔): LeetCode 题目地址:https://www.nowcoder.com/ta/coding-interviews 题目描 ...
- codeforce 595B-Pasha and Phone(数学)
今天补题,昨天是我太猖狂了,在机房吹牛,然后说着说着忘了时间,后来楼长来了,我们走了,CF没打成. 不扯了,下面说题: 题目的意思是给你n和k, n代表最后得出的号码有n为,然后k能被n整除,就是把n ...
- 编写Java程序,根据提供的 IP 地址,获取主机名称和域名
查看本章节 查看作业目录 需求说明: 根据提供的 IP 地址,获取主机名称和域名 实现思路: 创建 GetHostNameByIpAddress 类,在main方法中声明 String 类型的变量 i ...
- 编写Java程序,演练静态内部类应用
返回本章节 返回作业目录 需求说明: 创建一个Person类,在该类中定义一个Home静态内部类,并在这个Home类中定义一个显示Home相关信息的方法. 在Person类中设置一个Home类型属性对 ...
- 解决eclipse中Findbugs检查不生效的问题
eclipse安装了Findbugs插件, 但是在eclipse中发现不了bug错误, 具体表现为指定的类存在findbugs, 已经通过其他工具检查出来, 但是在eclipse中就是无法报告错误. ...
- RSA非对称加密算法实现:C#
RSA是1977年由罗纳德·李维斯特(Ron Rivest).阿迪·萨莫尔(Adi Shamir)和伦纳德·阿德曼(Leonard Adleman)一起提出的.当时他们三人都在麻省理工学院工作.RSA ...
- 开源实践 | 携程在OceanBase的探索与实践
写在前面:选型考虑 携程于1999年创立,2016-2018年全面推进应用 MySQL 数据库,前期线上业务.前端技术等以 SQL Server 为主,后期数据库逐步从 SQL Server 转到开源 ...
- Python中切片方法总结
对字符串或列表使用切片方法进行操作时 对包含[-1]的方法的使用经常用错 其实[-1]即指最后一个元素(同理[-2]指倒数第二个元素) 现总结如下 以便加深记忆 >>> li = [ ...
- 第10组 Beta冲刺 (2/5)(组长)
1.1基本情况 ·队名:今晚不睡觉 ·组长博客:https://www.cnblogs.com/cpandbb/p/14015412.html ·作业博客:https://edu.cnblogs.co ...