[论文阅读笔记] Adversarial Mutual Information Learning for Network Embedding
[论文阅读笔记] Adversarial Mutual Information Learning for Network Embedding
本文结构
- 解决问题
- 主要贡献
- 算法原理
- 实验结果
- 参考文献
(1) 解决问题
现有的基于GAN的方法大多都是先假设服从一个高斯分布,然后再来学习节点嵌入(匹配节点嵌入向量服从这个假设的先验分布)。
这可能存在两个问题:
- 一个问题是(由于真实数据是有很多噪声的,所以会为GAN模型学习的分布带来很多噪声)很难从节点向量表示中区分出噪声节点,因为所有节点都是服从高斯分布的,很容易受到噪声节点的影响?也就是噪声容易影响学习的分布,学习的分布对噪声不稳定?
- 第二个问题是,这种思想没有充分利用GAN的本质优势,作者认为GAN的优势在于其对抗学习的机制而不是学习节点向量表示本身(现有的利用GAN方法来做网络嵌入的方式大多目标是后者,为了学习更好的节点向量)。
所以本文的主要思路就是要在表示机制中融入对抗机制,而不是仅仅为了使得嵌入向量的分布要服从先验分布这个目的。基于以上基本思路,本文提出了一个结合自编码器的对抗学习方法用来实现网络嵌入,把对抗学习用在表示(映射)机制上。
(2) 主要贡献
Contribution:个人感觉这篇论文的主要贡献是把对抗学习这个机制运用在映射机制上而不是运用在表示向量本身,基于这个基本思路,提出了一个结合自编码器的对抗学习方法用来实现网络嵌入,利用对抗训练的机制来进一步优化编码器所学习得到的节点嵌入向量。
(3) 算法原理
模型的主要思路: 下图为论文所提出的AMIL模型的总体框架。AMIL的框架,包括三个部分,如下图所示。一个自编码器,一个负样本生成器和一个互信息判别器,整体是一个对抗过程。整体来说,自编码器部分利用网络拓扑聚合节点属性到节点表示中,解码器使用节点嵌入重构网络拓扑。负样本生成器部分这是一个生成对抗网络,包含一个生成器和属性判别器,是用来生成节点的fake属性向量的。互信息判别器识别编码器的映射机制生成的正样本和负样本生成器生成的负样本。

在AMIL模型中(编码器和生成器都要训练)。编码器部分包含两个目标,一个是传统的自编码器的重构损失,还有一个是互信息判别器的对抗训练目标。也就是说编码器部分根据解码器的反馈(带有结构信息)以及互信息判别器D的反馈(带有属性信息)两部分来更新自己的参数。这个负样本生成器也同样包括两个目标:一个是与自身的属性判别器的对抗目标,还有一个是和互信息判别器D的对抗训练目标。也就是说生成器也根据互信息判别器反馈(带有结构信息或者说负样本生成器只是对节点属性的建模?自己的猜测)和属性判别器(带有属性信息)反馈两个部分来更新自己的参数。以上这个对抗过程不断训练,直到收敛,就可以获得包含结构和属性的节点嵌入向量表示了,理论上可以是编码器的输出也可以是生成器的输出。但是生成器部分毕竟是最小化和真实节点属性向量的差异,可能没有包含拓扑结构的信息,所以感觉取编码器的输出作为最终向量可能会更好。
下面分别介绍以上AMIL框架三个部分的具体细节。
(1) 自编码器:
自编码器的编码器部分论文中采用两层的GCN来搭建,输入邻接矩阵A和属性矩阵X,GCN通过邻接矩阵A反应的图拓扑结构来聚合节点属性从而学习节点表示,每层GCN聚合一跳节点,两层可以聚合两跳节点。解码器部分简单重构网络拓扑,利用编码器得到的嵌入向量内积的sigmoid来重构邻接矩阵,采用交叉熵函数来计算重构损失,具体公式详见原始论文。
(2) 负样本生成器:
负样本生成器部分是一个普通的生成对抗网络(GAN),包含一个生成器和一个判别器。生成器采用三层全连接层的神经网络实现(判别器也是),以一个高斯噪声作为输入,生成节点的fake属性向量,以欺骗判别器。判别器部分目标是去识别真属性和假属性向量。通过迭代训练,生成器生成的节点属性会更加接近真实。GAN具体目标函数详见原始论文。
(3) 互信息判别器:
前面说到模型的核心在于应用对抗学习策略在表示机制上而非表示向量本身,目标是为了学习一个更加有效的嵌入机制。这个核心思路的具体体现就在互信息判别器这一部分。互信息可以表示两个变量之间的依赖关系,越大则两个变量互相依赖(理解为相似?)程度越大。利用这一点,作者使用输入向量和输出向量的互信息来定量表示一个嵌入机制(将输入向量映射到输出向量)的质量,互信息越大表示嵌入质量越好。互信息可以用一些不同的方式定义,但是为了简便和学习效率,作者简单将输入向量和输出向量的拼接定义为互信息的近似。
既然这是一个判别器那么就需要定义正样本和负样本。对于互信息判别器的正样本和负样本定义,我们将编码器生成的节点表示Z和属性信息X的互信息作为正样本(就是编码器的输入和输出嘛)。并且把生成器的输入(噪声高斯分布Z’)和输出(假属性向量X’)的互信息作为负样本。然后互信息判别器的目标就是去区分这对样本了,对正样本输出1,对负样本输出0。互信息判别器的损失详见原始论文。
结合以上三个部分来看AMIL整体框架结构图,其实整个AMIL框架就是一个包含两个竞争对手(指的是映射机制GAN和自编码器)的全局的对抗学习过程,该模型联合训练一个编码器和一个生成器。 AMIL总的目标函数详见原始论文,并且最终使用基于梯度的优化方法来做优化。
(4) 实验结果
- 节点分类
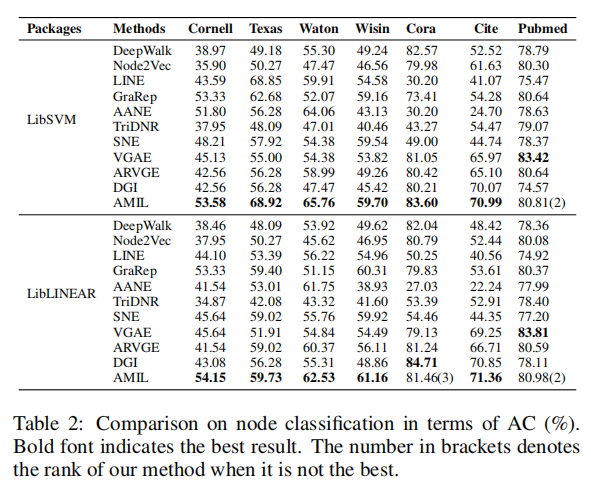
- 节点聚类
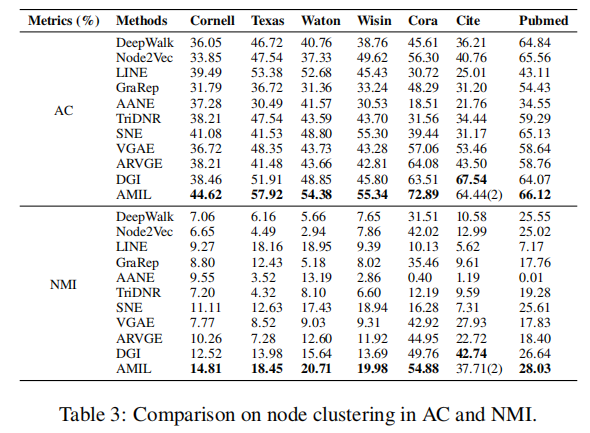
- 参数实验
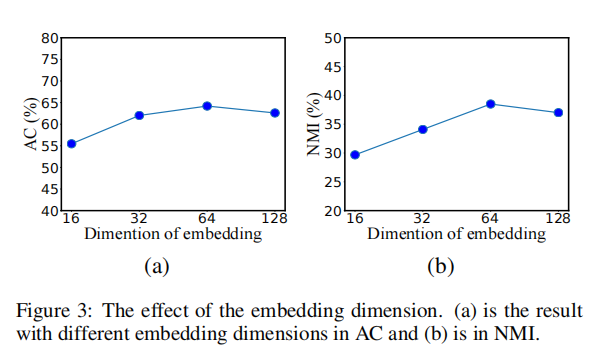
- Citeseer 数据集的可视化结果
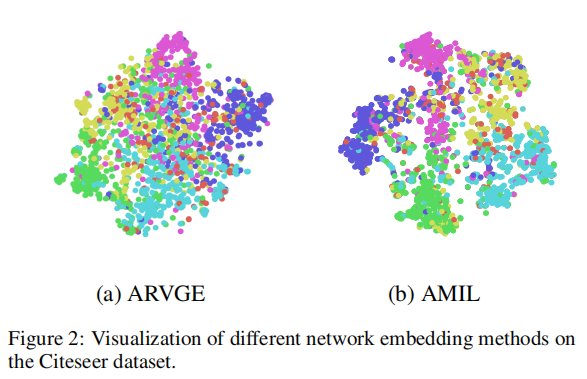
(5) 参考文献
He D, Zhai L, Li Z, et al. Adversarial Mutual Information Learning for Network Embedding[C]//Proceedings of IJCAI. 2020: 3321-3327.
[论文阅读笔记] Adversarial Mutual Information Learning for Network Embedding的更多相关文章
- [论文阅读笔记] Community aware random walk for network embedding
[论文阅读笔记] Community aware random walk for network embedding 本文结构 解决问题 主要贡献 算法原理 参考文献 (1) 解决问题 先前许多算法都 ...
- [论文阅读笔记] Adversarial Learning on Heterogeneous Information Networks
[论文阅读笔记] Adversarial Learning on Heterogeneous Information Networks 本文结构 解决问题 主要贡献 算法原理 参考文献 (1) 解决问 ...
- 论文阅读笔记 Improved Word Representation Learning with Sememes
论文阅读笔记 Improved Word Representation Learning with Sememes 一句话概括本文工作 使用词汇资源--知网--来提升词嵌入的表征能力,并提出了三种基于 ...
- [论文阅读笔记] metapath2vec: Scalable Representation Learning for Heterogeneous Networks
[论文阅读笔记] metapath2vec: Scalable Representation Learning for Heterogeneous Networks 本文结构 解决问题 主要贡献 算法 ...
- [论文阅读笔记] node2vec Scalable Feature Learning for Networks
[论文阅读笔记] node2vec:Scalable Feature Learning for Networks 本文结构 解决问题 主要贡献 算法原理 参考文献 (1) 解决问题 由于DeepWal ...
- 论文阅读笔记二十三:Learning to Segment Instances in Videos with Spatial Propagation Network(CVPR2017)
论文源址:https://arxiv.org/abs/1709.04609 摘要 该文提出了基于深度学习的实例分割框架,主要分为三步,(1)训练一个基于ResNet-101的通用模型,用于分割图像中的 ...
- 论文阅读笔记 Word Embeddings A Survey
论文阅读笔记 Word Embeddings A Survey 收获 Word Embedding 的定义 dense, distributed, fixed-length word vectors, ...
- Nature/Science 论文阅读笔记
Nature/Science 论文阅读笔记 Unsupervised word embeddings capture latent knowledge from materials science l ...
- [置顶]
人工智能(深度学习)加速芯片论文阅读笔记 (已添加ISSCC17,FPGA17...ISCA17...)
这是一个导读,可以快速找到我记录的关于人工智能(深度学习)加速芯片论文阅读笔记. ISSCC 2017 Session14 Deep Learning Processors: ISSCC 2017关于 ...
随机推荐
- php 解析富文本编辑器中的hmtl内容,富文本样式正确输出
说明:富文本编辑器中的内容在直接获获取后需要解析以后才能在页面中正确显示 我在后端这样处理: $content = htmlspecialchars_decode($info['intro']); h ...
- InnoDB解决幻读的方案——LBCC&MVCC
最近要在公司内做一次技术分享,思来想去不知道该分享些什么,最后在朋友的提示下,准备分享一下MySQL的InnoDB引擎下的事务幻读问题与解决方案--LBCC&MVCC.经过好几天的熬夜通宵,终 ...
- Python数模笔记-NetworkX(2)最短路径
1.最短路径问题的常用算法 最短路径问题是图论研究中的经典算法问题,用于计算图中一个顶点到另一个顶点的最短路径. 1.1 最短路径长度与最短加权路径长度 在日常生活中,最短路径长度与最短路径距离好像并 ...
- C++ primer plus读书笔记——第1章 预备知识
第1章 预备知识 1. Ritchie希望有一种语言能将低级语言的效率.硬件访问能力和高级语言的通用性.可移植性融合在一起,于是他在旧语言的基础上开发了C语言. 2. 在C++获得一定程度的成功后,S ...
- 测试报告$\alpha$
pytorch可视化编程网站VisualPytorch NAG \(\alpha\)版本发布了!点击网址访问:VisualPytorch 一.测试查虫(bug detection) 测试贯穿了开发.集 ...
- 【软工】个人项目作业——个人软件流程(PSP)
[软工]个人项目作业--个人软件流程(PSP) 项目 内容 班级:北航2020春软件工程 006班(罗杰.任健 周五) 博客园班级博客 作业:设计程序求几何对象的交点集合 个人项目作业 个人课程目标 ...
- [Python] RPC实现
单线程同步 使用socket传输数据 使用json序列化消息体 struct将消息编码为二进制字节串,进行网络传输 消息协议 1 // 输入 2 { 3 in: "ping", 4 ...
- [刷题] 102 Binary Tree Level Order Traversal
要求 对二叉树进行层序遍历 实现 返回结果为双重向量,对应树的每层元素 队列的每个元素是一个pair对,存树节点和其所在的层信息 1 Definition for a binary tree node ...
- yum 命令详解-yum仓库配置文件详解
yum安装的优点 1.必须得有网络,通过网络获取软件. 2.管理rpm包 3.自动解决依耐 4.命令简单好用 5.生产最佳实践 yum命令详解 # linux安装软件的三种方式 1.rpm安装 2.源 ...
- IDEA 创建 Maven 项目每次都需要重新配置问题
问题描述 通过 File->Settings 设置 maven 配置,在 IDEA 新创建 Maven 项目时设置的 maven 配置会被重置,导致每次创建新 Maven 项目都需要重新设置一遍 ...