Python-对Pcap文件进行处理,获取指定TCP流
通过对TCP/IP协议的学习,本人写了一个可以实现对PCAP文件中的IPV4下的TCP流提取,以及提取指定的TCP流,鉴于为了学习,没有采用第三方包解析pcap,而是对bytes流进行解析,其核心思想为:若想要提取TCP Content,需在下层的IPV4协议中判断Protocol是否为TCP,然后判断下层的以太网协议的Type是否为IPV4协议(此处的IPV4判断,只针对本人所写项目);对于指定流需要获取Client以及Server的[IP,PORT]。
一、Pcap文件解析
对于一个Pcap文件,其结构为文件头,数据包头,数据包数据,数据包头,数据包数据……,文件头为24字节,如下:

- Magic:4Byte:标记文件开始,并用来识别文件自己和字节顺序
- Major:2Byte: 当前文件主要的版本号
- Minor:2Byte: 当前文件次要的版本号
- ThisZone:4Byte:当地的标准时间,如果用的是GMT则全零,一般都直接写 0000 0000
- SigFigs:4Byte:时间戳的精度
- SnapLen:4Byte:最大的存储长度
- LinkType:4Byte:链路类型
数据报头为16字节,如下:
- Timestamp 4Byte:被捕获时间的高位,精度为seconds
- Timestamp 4Byte:被捕获时间的低位,精度为microseconds
- Caplen 4Byte:当前数据区的长度,即抓取到的数据帧长度,不包括Packet Header本身的长度,单位是 Byte ,由此可以得到下一个数据帧的位置。
- Len 4Byte:离线数据长度:网络中实际数据帧的长度,一般不大于caplen,多数情况下和Caplen数值相等。
Packet Data
在数据包头之后,就是数据包的数据了,数据长度就是Caplen个Byte,在此之后是一个新的Packet Header,新的Packet Data,如此循环。
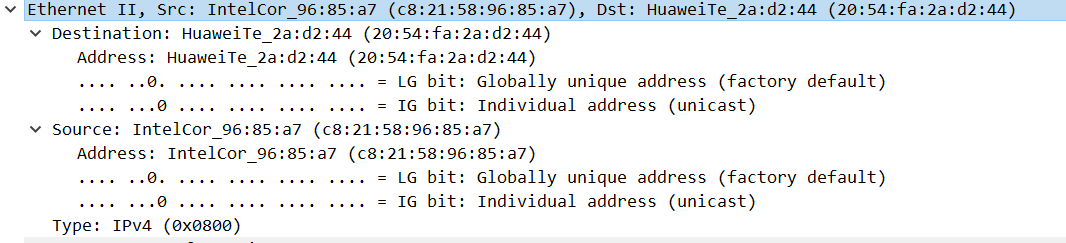

- Version 4bit:对于IPv 4,这总是等于4
- IHL 4bit:数据报协议头长度,表示协议头具有32位字长的数量。该字段的最小值为5,它表示长度为5×32位=160位=20字节。作为一个4位字段,最大值为15字(15×32位,或480位=60字节)
- DSCP 6bit:差分服务代码点
- ECN 2bit:显式拥塞通知
- Total Length 2Byte:这个16位字段定义了整个IP数据包大小(以字节为单位),包括报头和数据,最小大小为20字节(没有数据的头),最大为65535字节。
- Identification 2Byte:该字段是一个标识字段,主要用于唯一标识单个IP数据报的片段组。
- Flags 3bit:用于控制或识别片段
- Fragment Offset 13bit:片段偏移字段以8字节块为单位进行测量。它有13位长,并指定特定片段相对于原始未分段ip数据报开头的偏移量。第一个片段的偏移量为零。这允许最大偏移量(2**13-1)×8=65528字节,这将超过包含报头长度(65528+20=65548字节)的最大IP数据包长度65535字节。
- Time To Live (TTL) 1Byte:一段8位的存活时间有助于防止数据报在互联网上持久化
- Protocol 1Byte:此字段定义IP数据报的数据部分中使用的协议
- Header Checksum 2Byte:16位IPV4头校验和字段用于对标头进行错误检查
- Source address 4Byte:此字段是数据包发件人的IPV4地址。
- Destination address 4Byte:该字段是数据包接收方的IPV4地址
- Options:选项字段不常使用。
四、TCP协议解析

- Source port (16 bits):标识发送端口
- Destination port (16 bits):标识接收端口
- Sequence number (32 bits):序列号,具有双重作用,如果syn被设置成1,标志这是初始序列号,如果syn被设置成0,表示这是初始序列号,如果syn被设置成0,表示这是当前会话的此段的第一个数据字节的累积序列号
- Acknowledgment number (32 bits):如果设置ACK标志,则此字段的值是ACK发送方期望的下一个序列号
- Data offset (4 bits):指定以32位为单位的tcp报头的大小。最小标头为5字,最大为15字,从而使其最小为20字节,最大为60字节,允许在标题中设置多达40字节的选项
- Reserved (3 bits):供将来使用,并应设置为零
- NS (1 bit): ECN-nonce - 隐藏保护
- CWR (1 bit): 发送主机设置拥塞窗口减少(Cwr)标志,以表明它收到了设置了ecc标志的tcp段,并在拥塞控制机制中作出了响应
- ECE (1 bit): ECN-Echo具有双重角色,这取决于SYN标志的值
- URG (1 bit): 指示紧急指针字段是有效的
- ACK (1 bit): 指示确认字段是有效的。客户端发送的初始SYN数据包之后的所有数据包都应该设置此标志
- PSH (1 bit): 推送功能,请求将缓冲数据推送到接收应用程序
- RST (1 bit):重置连接
- SYN (1 bit): 同步序列号。只有从每一端发送的第一个数据包应该设置此标志。其他一些标志和字段根据此标志更改含义,有些只有在设置1时才有效,而另一些则在0时才有效
- FIN (1 bit): 来自发送方的最后一包
- Window size (16 bits):接收窗口的大小
- Checksum (16 bits):16位校验和字段用于对报头、有效载荷和伪头进行错误检查
- Urgent pointer (16 bits):如果设置了URG标志,则此16位字段与表示最后一个紧急数据字节的序列号之间的偏移量
- Options (Variable 0–320 bits, divisible by 32):该字段的长度由数据偏移字段决定
Flags (9 bits) (aka Control bits):包含9个标志位
五、处理文件
部分核心代码如下:
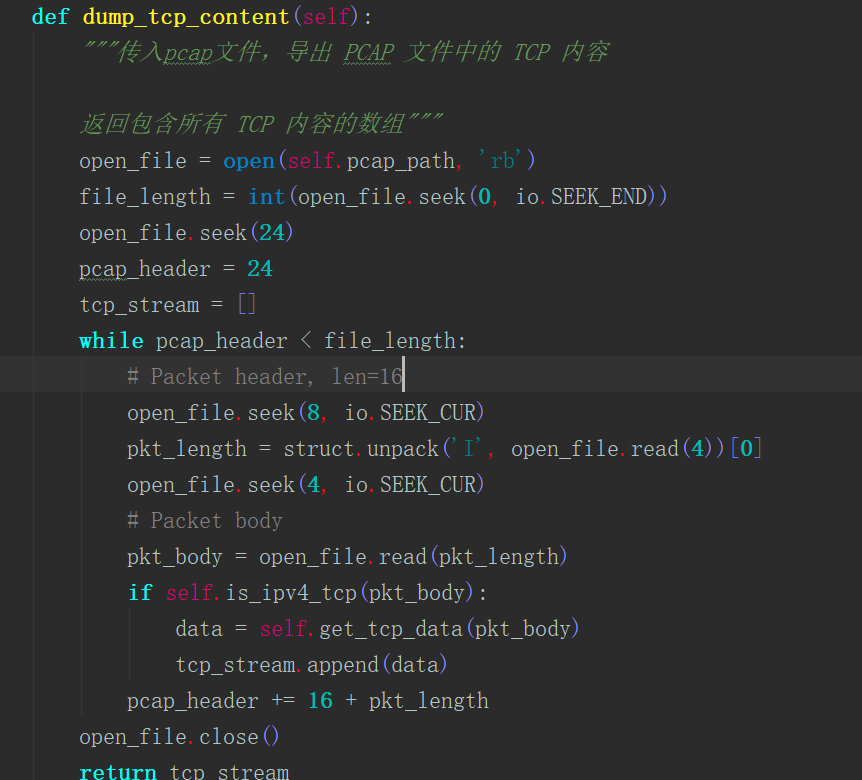
此部分是对pcap(bytes)文件读入,将每一个数据包数据作为一帧,判断为IPV4-TCP数据后,将TCP里面的[src, dst,src_port,dst_port, seq, ack, flags, content]一帧帧提取,存储在tcp_stream,此处即为提取pcap文件中所有的TCP流

此处是对于上面传入的tcp_stream,提取出我们想要指定的Tcpstream,如果flags_ack,flages_push为1时,即有Client或Server进行http请求,若此包被确认接收,则进行存储(避免重传,丢包的情况),判断flags_fin为1时,结束循环,返回指定的Tcp流。
六、完整代码
TCP学习:https://en.wikipedia.org/wiki/Transmission_Control_Protocol#TCP_segment_structure
IPV4学习:https://en.wikipedia.org/wiki/IPv4#Packet_structure
完整代码:https://github.com/sunpudding/python,里面不仅有完整项目代码,还有单元测试,欢迎下载,一起学习交流。
Python-对Pcap文件进行处理,获取指定TCP流的更多相关文章
- python zip压缩文件 并移动到指定目录
需要引入的3个包: import os import shutil import zipfile 1. # 创建zip文件对象your_zip_file_obj = zipfile.ZipFile(' ...
- python解析pcap文件中的http数据包
使用scapy.scapy_http就可以方便的对pcap包中的http数据包进行解析 scapy_http可以在https://github.com/invernizzi/scapy-http下载, ...
- windows上python上传下载文件到linux服务器指定路径【转】
从windows上传文件到linux,目录下的文件夹自动创建 #!/usr/bin/env python # coding: utf-8 import paramiko import datetime ...
- PyQt(Python+Qt)学习随笔:QTableWidget的获取指定位置项的item和itemAt方法
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 1.获取指定行和列的项 根据行和列可以获取对应位置的项,调用语法如下: QTableWidgetIt ...
- 一个获取指定目录下一定格式的文件名称和文件修改时间并保存为文件的python脚本
摘自:http://blog.csdn.net/forandever/article/details/5711319 一个获取指定目录下一定格式的文件名称和文件修改时间并保存为文件的python脚本 ...
- 使用Python脚本获取指定格式文件列表的方法
在Python环境下获取指定后缀文件列表的方式. 来源stackoverflow 这里简单以*.txt的作为例子. 使用glob(推荐) import glob, os os.chdir(" ...
- Python获取指定文件夹下的文件名
本文采用os.walk()和os.listdir()两种方法,获取指定文件夹下的文件名. 一.os.walk() 模块os中的walk()函数可以遍历文件夹下所有的文件. os.walk(top, t ...
- python 脚本(获取指定文件夹、指定文件格式、的代码行数、注释行数)
1.代码的运行结果: 获取 指定文件夹下.指定文件格式 文件的: 总代码行数.总注释行数(需指定注释格式).总空行数: #coding: utf-8 import os, re # 代码所在目录 FI ...
- Python获取指定路径下所有文件的绝对路径
需求 给出制定目录(路径),获取该目录下所有文件的绝对路径: 实现 方式一: import os def get_file_path_by_name(file_dir): ''' 获取指定路径下所有文 ...
随机推荐
- Centos7上yum安装redis
下载tar包 wget http://download.redis.io/releases/redis-6.0.5.tar.gz 解压tar包 tar -zxvf redis-6.0.5.tar.gz ...
- 依赖注入@Autowired@Primary@Quelifier使用
@Autowired 注入声明的SpringBean对象,根据一定的规则首先按照注入的类型去查找,如果没有找到安装注入的名称去匹配你要注入的属性名称,如果都没有找到启动项目时抛出异常,@Autowir ...
- COM组件的使用方法
https://prismlibrary.com/docs/wpf/converting-from-7.html Requirement: 1.创建myCom.dll,该COM只有一个组件,两个接口I ...
- .Net Core 集成 Redis
首先安装RedisServer 安装教程可参照 http://www.redis.cn/download.html 或者 https://www.runoob.com/redis/redis-inst ...
- (5)air202读取串口数据并上传到阿里云显示
一.首先进行云端设置 根据串口助手显示的信息,以及模块文档说明我们可以知道 其中red和ir是红光LED的原始数据, HR表示心率值, HRvalid是心率是否有效标识, SP02是血氧数值,,SPO ...
- Linux 系统下10个查看网络与监听的命令
下面列出来的10个基础的每个linux用户都应该知道的网络和监控命令.网络和监控命令类似于这些: hostname, ping, ifconfig, iwconfig, netstat, nslook ...
- HbaseWAL
1.WAL意为 Write Ahead Log ,类似MySQL中的binlog,用来做灾难恢复之用,HLog记录数据的所有变更,一旦数据修改,就可以从Log中进行恢复. Hbase采用类LSM的架构 ...
- 刷题-力扣-518. 零钱兑换 II
518. 零钱兑换 II 题目链接 来源:力扣(LeetCode) 链接:https://leetcode-cn.com/problems/coin-change-2/ 著作权归领扣网络所有.商业转载 ...
- Python和java的选择
它是什么? Java是一种通用的面向对象的编程语言,主要用于开发从移动应用程序到Web到企业应用程序的各种应用程序. Python是一种高级的面向对象的编程语言,主要用于Web开发,人工智能,机器学习 ...
- Qt5创建模态和非模态对话框
1.模态对话框创建: 第一种方法: QDialog dialog(this); dialog.exec(); this为该对话框的父窗口. 第二种方法: QDialog *dialog = new Q ...