利用元数据提高 SQLFlow 血缘分析结果准确率
利用元数据提高 SQLFlow 血缘分析结果准确率
一、SQLFlow--数据治理专家的一把利器
数据血缘属于数据治理中的一个概念,是在数据溯源的过程中找到相关数据之间的联系,它是一个逻辑概念。数据治理里经常提到的一个词就是血缘分析,血缘分析是保证数据融合的一个手段,通过血缘分析实现数据融合处理的可追溯。大数据治理分析师常常需要对各种复杂场景下的SQL语句进行溯源分析,而限于环境因素,往往只能提供SQL语句给SQLFlow进行分析处理,SQL语句的制造者往往为了简便行事,会产生一些数据库可执行但SQLFlow无法正确识别的一类语句,本文聚焦此处,为各位专家介绍SQLFlow官方对这类问题的解决方案。
SQLFlow官方入口: https://sqlflow.gudusoft.com
二、SQLFlow的Orphan Column Error
随着SQLFlow的使用,你会发现在分析部分SQL 数据血缘时,会遇到SQLFlow的orphan column错误提示,如下图所示:

如果您是SQLFlow的新用户,您可能会有我的SQL语句明明是正确可执行的为啥会报这个错误,这主要是因为SQLFlow目前的模式是未连接数据源状态,即仅从SQL语句进行血缘分析。orphan column error是提示正在分析的SQL语句存在‘孤儿列’,什么是孤儿列?孤儿列就是在多表join的情形下某个返回列或条件列没有指定具体所属表对象,即SQLFlow没有依据判断该列到底是来源于哪里。
示例:
select c_customer_id
from customer_total_return ctr1,store,customer
where ctr1.ctr_total_return > (select avg(ctr_total_return)*1.2
from customer_total_return ctr2 where ctr1.ctr_store_sk = ctr2.ctr_store_sk)
and s_store_sk = ctr1.ctr_store_sk
and s_state = 'SD'
and ctr1.ctr_customer_sk = c_customer_sk
order by c_customer_id
上述语句是一个3表(customer_total_return ,store,customer)关联的简单语句,它的运算结果是返回复合条件的c_customer_id列集合。不难看出,关联条件(and s_store_sk = ctr1.ctr_store_sk and s_state = 'SD' and ctr1.ctr_customer_sk = c_customer_sk)中s_store_sk 、s_state 、c_customer_sk等三个列并没有指定来源。该语句之所以在Oracle查询分析器中没有错误,是因为查询分析器可以拿到三个表定义进行遍历对比,如果上述未指定来源表的列恰好都只属于某个表,此时查询分析器便能正常解析并执行该语句。
相反,SQLFlow只有SQL语句,而没法获取表定义,所以就会出现orphan column error。那我们应该如何解决’孤儿列’的问题呢?目前有以下两个可行方案:
1、完善SQL语句,由简变繁
select ctr1.c_customer_id
from customer_total_return ctr1,store s,customer c
where ctr1.ctr_total_return > (select avg(ctr_total_return)*1.2
from customer_total_return ctr2 where ctr1.ctr_store_sk = ctr2.ctr_store_sk)
and s.s_store_sk = ctr1.ctr_store_sk
and s.s_state = 'SD'
and ctr1.ctr_customer_sk = c.c_customer_sk
order by c.c_customer_id
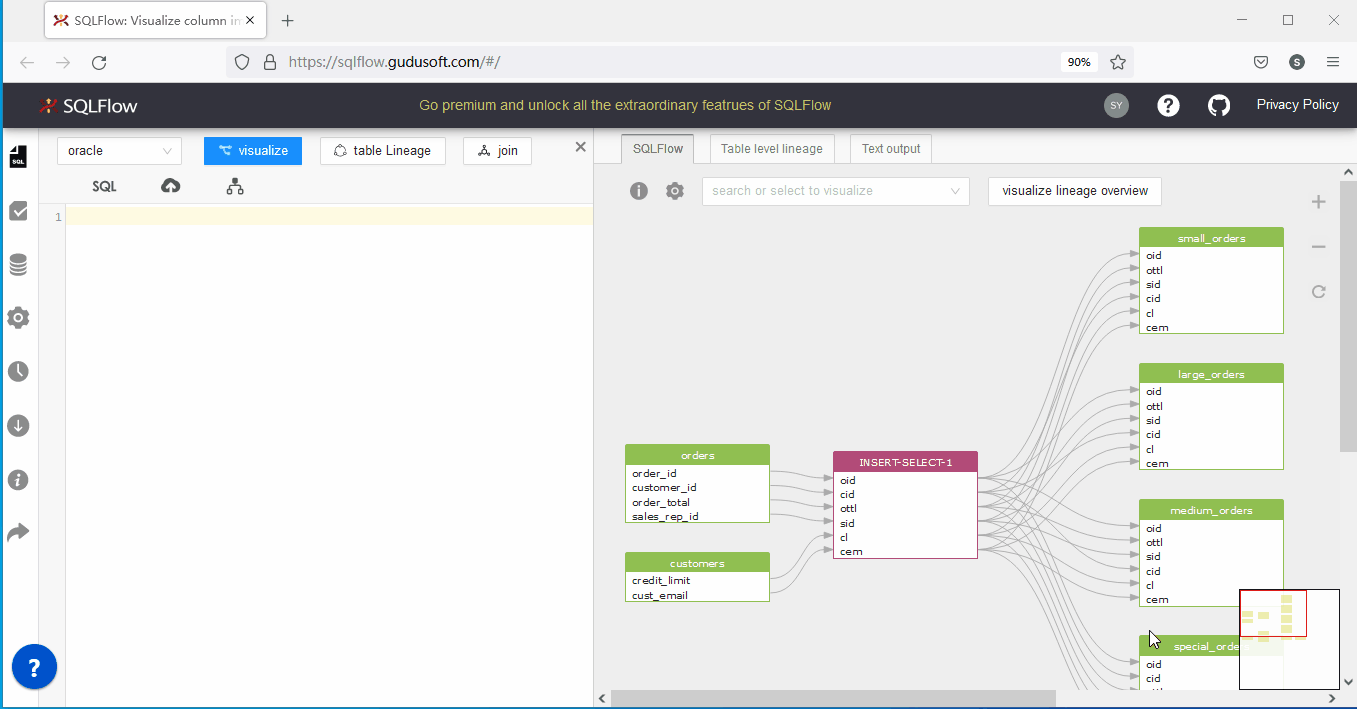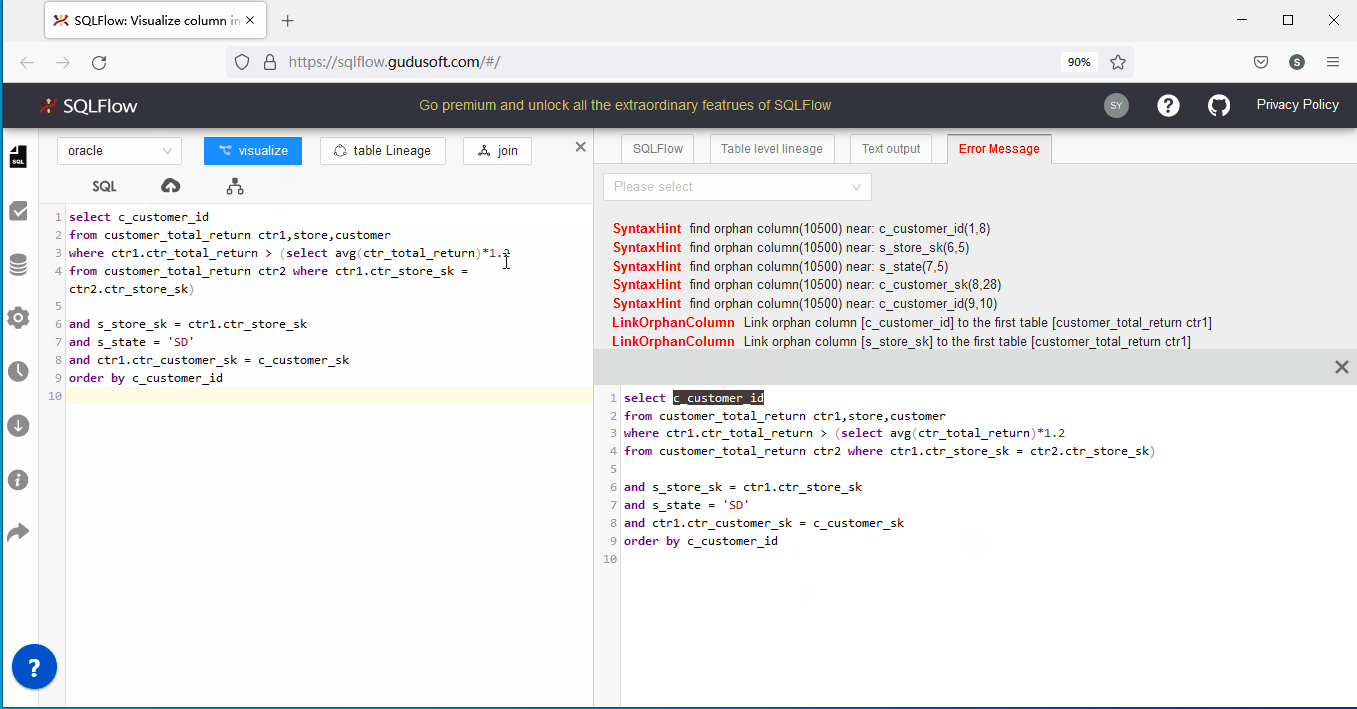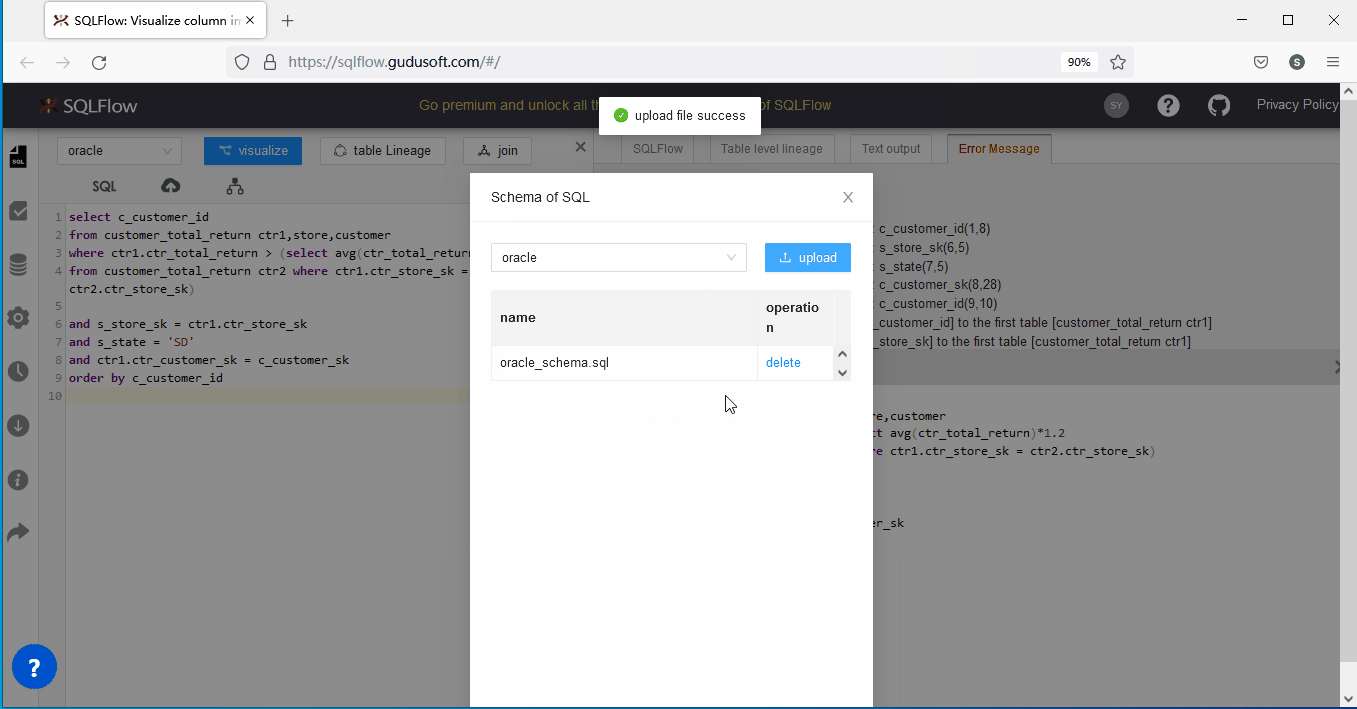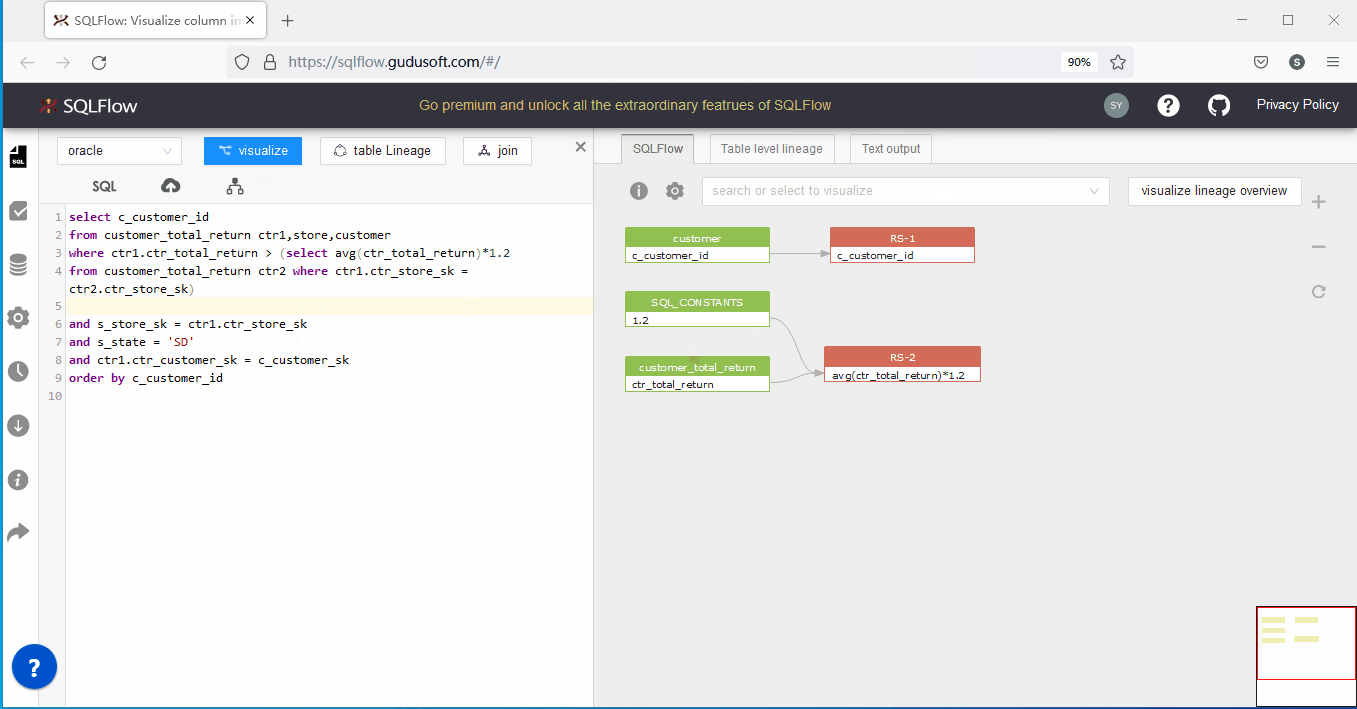
上述代码将返回列、条件列中所有未指定来源表的列进行了完善,执行SQLFlow分析后,能够成功分析:

上图能够成功分析并且右侧显示窗口中已经没有错误信息。
2、为SQLFlow上传schema 文件
SQLFlow厂商为解决上述问题,为用户提供了一个可以手工上传schema DDL文件的方法来解决上述问题。
还以上述SQL语句为例,我们可以将对应的缺失列的Table DDL以文件方式上传提供给SQLFlow后,具体的table DDL定义如下:
create table customer
(
c_customer_sk integer not null,
c_customer_id char(16) not null,
c_current_cdemo_sk integer ,
c_current_hdemo_sk integer ,
c_current_addr_sk integer ,
c_first_shipto_date_sk integer ,
c_first_sales_date_sk integer ,
c_salutation char(10) ,
c_first_name char(20) ,
c_last_name char(30) ,
c_preferred_cust_flag char(1) ,
c_birth_day integer ,
c_birth_month integer ,
c_birth_year integer ,
c_birth_country varchar(20) ,
c_login char(13) ,
c_email_address char(50) ,
c_last_review_date char(10) ,
primary key (c_customer_sk)
);
create table store
(
s_store_sk integer not null,
s_store_id char(16) not null,
s_rec_start_date date ,
s_rec_end_date date ,
s_closed_date_sk integer ,
s_store_name varchar(50) ,
s_number_employees integer ,
s_floor_space integer ,
s_hours char(20) ,
s_manager varchar(40) ,
s_market_id integer ,
s_geography_class varchar(100) ,
s_market_desc varchar(100) ,
s_market_manager varchar(40) ,
s_division_id integer ,
s_division_name varchar(50) ,
s_company_id integer ,
s_company_name varchar(50) ,
s_street_number varchar(10) ,
s_street_name varchar(60) ,
s_street_type char(15) ,
s_suite_number char(10) ,
s_city varchar(60) ,
s_county varchar(30) ,
s_state char(2) ,
s_zip char(10) ,
s_country varchar(20) ,
s_gmt_offset decimal(5,2) ,
s_tax_precentage decimal(5,2) ,
primary key (s_store_sk)
);
由于第一张表customer_total_return所使用/返回的列均在SQL语句中显示指定,所以这里不需要额外提供它的定义信息,只需要提供其他两张表的定义,如果您的语句中存在所有表均有上述情况,则需要将所有表的定义提供给SQLFlow供分析。
实际操作如下:
关于SQLFlow官方提供的上传schema解决方案的几点补充:
一个用户可以上传一个或多个schema文件,也支持打包zip格式上传,SQLFlow会自动遍历所有文件进行分析;
用户可以对已上传的文件进行删除;
三、参考网站
SQLFlow官方入口:
SQLFlow 架构文档:
https://github.com/sqlparser/sqlflow_public/blob/master/sqlflow_architecture.md
利用元数据提高 SQLFlow 血缘分析结果准确率的更多相关文章
- 利用job提升马哈鱼数据血缘分析效率
利用job提升马哈鱼数据血缘分析效率 一.Job基本知识 前面文章中已介绍马哈鱼的基本功能,其中一个是job,job其实是一个任务集合处理的概念,就是让用户通过job,可以一次递交所有需要处理的 SQ ...
- 数据治理中Oracle SQL和存储过程的数据血缘分析
数据治理中Oracle SQL和存储过程的数据血缘分析 数据治理中的一个重要基础工作是分析组织中数据的血缘关系.有了完整的数据血缘关系,我们可以用它进行数据溯源.表和字段变更的影响分析.数据合规性 ...
- 马哈鱼血缘分析工具部署介绍--win 10
马哈鱼血缘分析工具部署介绍--win 10 随着大数据技术的发展与普及,数据治理和数据质量变得越来越重要,数据血缘分析在业界悄然兴起并得到了广泛流行,马哈鱼是国内少有的一款专业且易用的血缘分析工具.本 ...
- [.net 面向对象程序设计进阶] (18) 多线程(Multithreading)(三) 利用多线程提高程序性能(下)
[.net 面向对象程序设计进阶] (18) 多线程(Multithreading)(二) 利用多线程提高程序性能(下) 本节导读: 上节说了线程同步中使用线程锁和线程通知的方式来处理资源共享问题,这 ...
- [.net 面向对象程序设计进阶] (17) 多线程(Multithreading)(二) 利用多线程提高程序性能(中)
[.net 面向对象程序设计进阶] (17) 多线程(Multithreading)(二) 利用多线程提高程序性能(中) 本节要点: 上节介绍了多线程的基本使用方法和基本应用示例,本节深入介绍.NET ...
- [.net 面向对象程序设计进阶] (16) 多线程(Multithreading)(一) 利用多线程提高程序性能(上)
[.net 面向对象程序设计进阶] (16) 多线程(Multithreading)(一) 利用多线程提高程序性能(上) 本节导读: 随着硬件和网络的高速发展,为多线程(Multithreading) ...
- 利用backtrace和objdump进行分析挂掉的程序
转自:http://blog.csdn.net/hanchaoman/article/details/5583457 汇编不懂,先把方法记下来. glibc为我们提供了此类能够dump栈内容的函数簇, ...
- linux下利用elk+redis 搭建日志分析平台教程
linux下利用elk+redis 搭建日志分析平台教程 http://www.alliedjeep.com/18084.htm elk 日志分析+redis数据库可以创建一个不错的日志分析平台了 ...
- [转]利用/*+Ordered*/提高查询性能
[转]利用/*+Ordered*/提高查询性能 2009-02-06 10:46:27| 分类: Oracle | 标签: |字号大中小 订阅 消耗在准备利用Oracle执行计划机制提高查询性能 ...
随机推荐
- dubbo(四)
前言 1.浅谈架构的发展 首先,要了解dubbo,就得了解,它是在什么背景下产生的?这就需要从架构的发展说起. 孟老师从事软件开发2008年份,那时候我上高一,那个时候,淘宝.京东都还没有火起来.那个 ...
- Spring常见问题(五)
1.静态资源访问配置 绝对路径:访问静态资源. <mvc:resources location="/js/" mapping="/js/**">&l ...
- LeetCode通关:求次数有妙招,位运算三连
分门别类刷算法,坚持,进步! 刷题路线参考: https://github.com/chefyuan/algorithm-base 大家好,我是刷题困难户老三,这一节我们来刷几道很有意思的求次数问题, ...
- Python小白的数学建模课-16.最短路径算法
最短路径问题是图论研究中的经典算法问题,用于计算图中一个顶点到另一个顶点的最短路径. 在图论中,最短路径长度与最短路径距离却是不同的概念和问题,经常会被混淆. 求最短路径长度的常用算法是 Dijkst ...
- python编写DDoS攻击脚本
python编写DDoS攻击脚本 一.什么是DDoS攻击 DDoS攻击就是分布式的拒绝服务攻击,DDoS攻击手段是在传统的DoS攻击基础之上产生的一类攻击方式.单一的DoS攻击一般是采用一对一方式的, ...
- 这个大表走索引字段查询的 SQL 怎么就成全扫描了,我TM人傻了
今天收到运营同学的一个 SQL,有点复杂,尤其是这个 SQL explain 都很长时间执行不出来,于是我们后台团队帮忙解决这个 SQL 问题,却正好发现了一个隐藏很深的线上问题. select a. ...
- SpringBoot-表单验证-统一异常处理-自定义验证信息源
1. 简介 我们都知道前台的验证只是为了满足界面的友好性.客户体验性等等.但是如果仅靠前端进行数据合法性校验,是远远不够的.因为非法用户可能会直接从客户端获取到请求地址进行非法请求,所以后台的校验是必 ...
- 面试必知道的APP测试adb命令
查看当前连接设备: adb devices 如果发现多个设备: adb -s 设备号 其他指令 查看日志: adb logcat 安装apk文件: adb install xxx.apk 此安装方式, ...
- tomcat 配置http跳转https
web.xml增加配置 <security-constraint> <web-resource-collection > <web-resource-name >S ...
- awk-04-流程控制
if 格式: if ( 条件 ) 语句 [ else 语句 ] 单分支 正则匹配判断 双分支 多分支 while 格式 while (条件) 语句 awk是按行处理的,每次读取一行,并遍历打印每个字段 ...