浅谈KMP模式匹配算法
普通的模式匹配算法(BF算法)
子串的定位操作通常称为模式匹配算法
假设有一个需求,需要我们从串“a b a b c a b c a c b a b"中,寻找内容为“a b c a c”的子串。
此时,称“a b a b c a b c a c b a b"为主串S,“a b c a c”为模式串T。
很容易想到,通过遍历主串S,与模式串T的首字母逐一比对,当主串S中的某一元素i与模式串T首字符j相同,则将主串S中第i+1个字符与模式串T的j+1个字符继续匹配。若匹配成功,则继续将主串S中的第i+2个字符与模式串T中的第j+2个字符进行比对。若匹配失败,则将主串S的第i+1个字符与模式串的第j个字符重新比对....
将上述文字转化为图像如下:
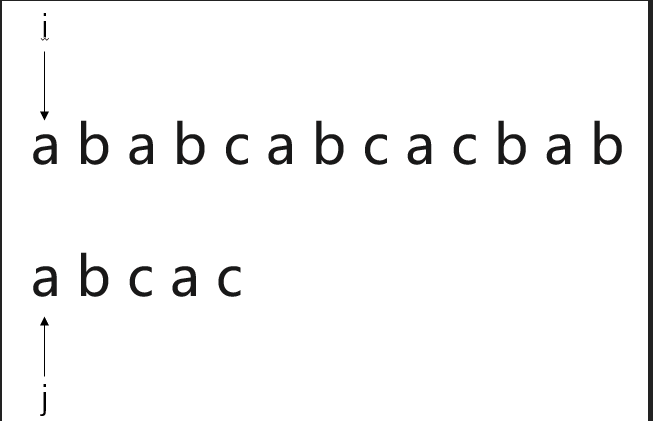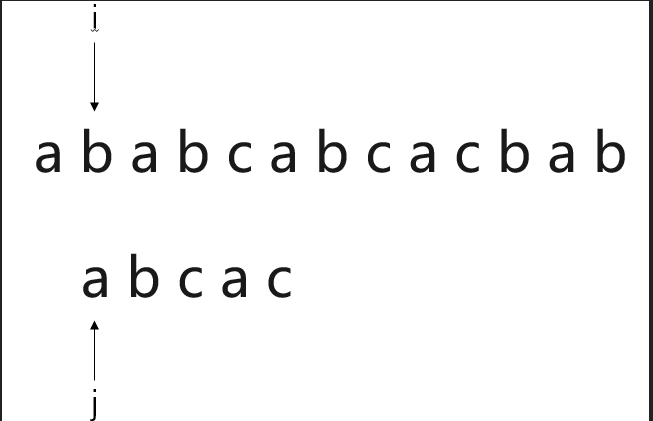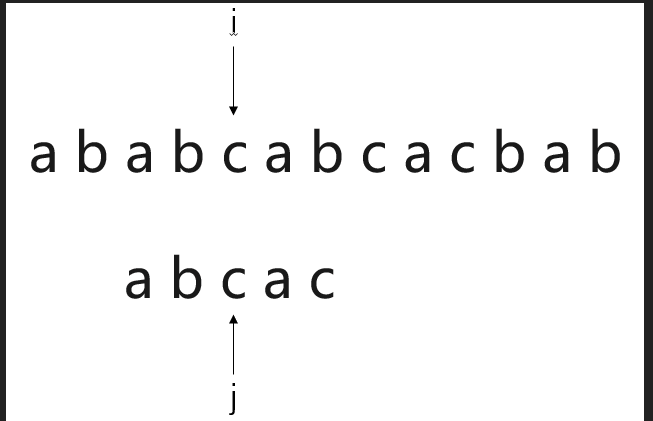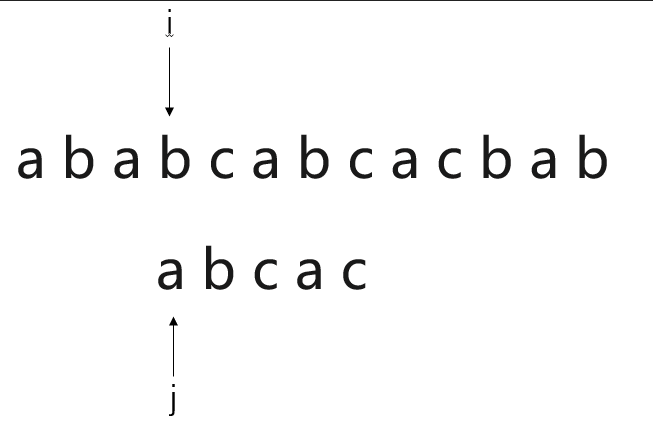
按照动画的显示效果很容易理解BF模式匹配算法。
通过分析可以得出,每次匹配失败之后,i的指向又将回到主串S的i-j+2位置
通过C语言伪代码的方式实现:

若将主串S的长度看作m,将模式串T的长度看作n
则该代码的时间复杂度为O(m+n)
BF算法确实实现了模式匹配的目的,但同时也有较大的缺陷
模式匹配改进算法(KMP算法)的引出
假设目前有这样一个主串S与模式串T
主串S:
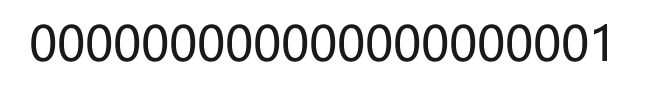
模式串T:
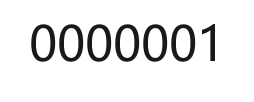
比对过程:
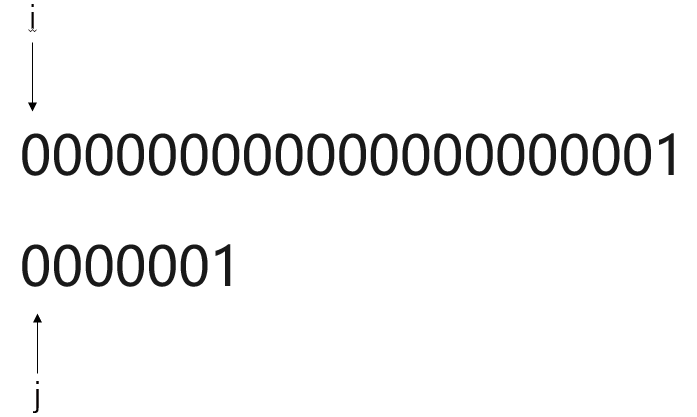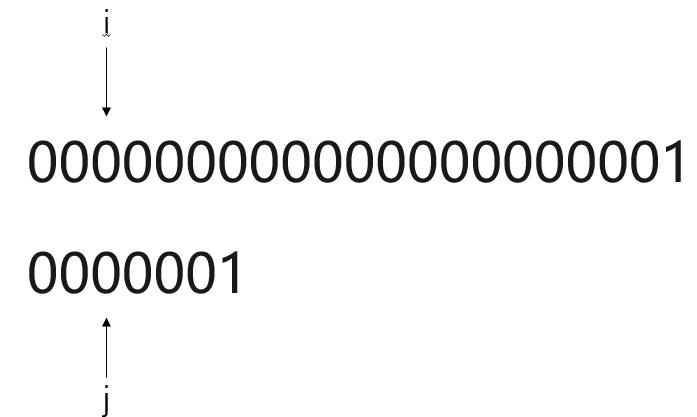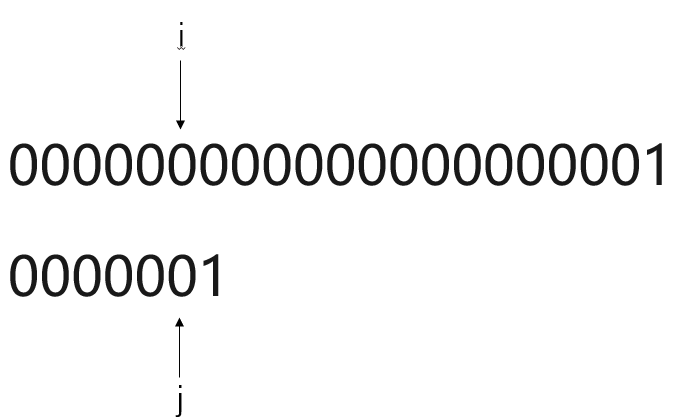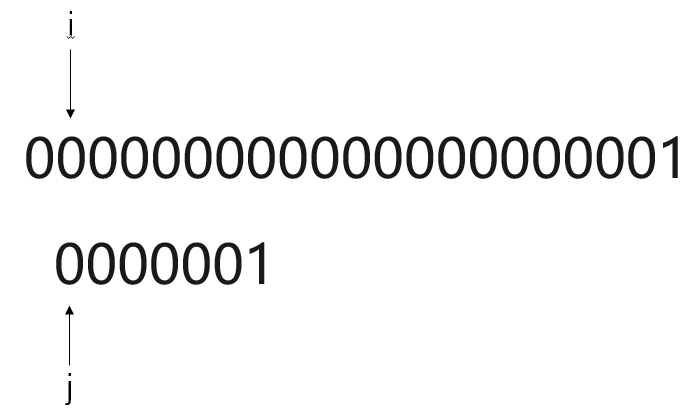
显而易见,使用BF模式匹配算法,一旦遇到主串S元素与模式串T高度重合,但鲜有不同。
此种算法将进行大量重复的“主串S回退”,如此一来,时间复杂度将达到
O(m*n)
而后,D.E.Knuth与V.R.Pratt和J.H.Morris发现了一套模式匹配的改进算法,根据他们的名字的字母,该算法被命名为:
KMP算法
KMP算法
KMP算法基本概念
KMP算法可以在时间复杂度为O(m+n)的时间数量级上完成模式匹配操作。
其不同点在于,在匹配失败之后,不需要回溯i指针
而是利用已经“部分匹配”的结果,将模式串T向右滑动尽可能远的距离
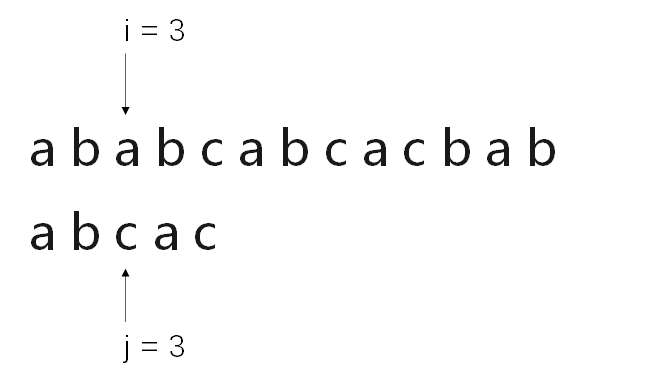
(KMP算法比对过程1)

(KMP算法比对过程2)
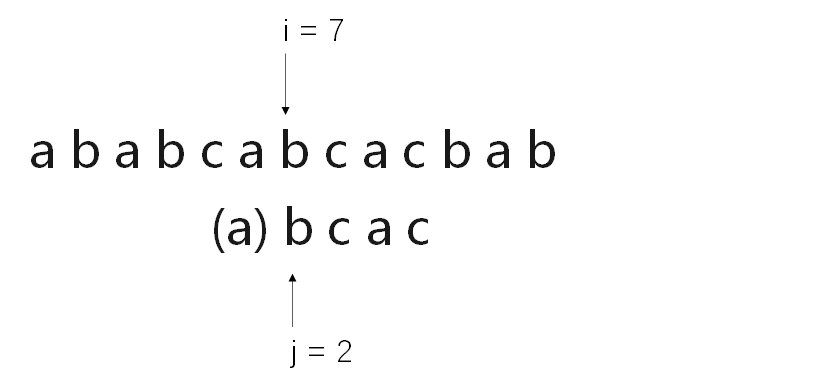
(KMP算法比对过程3)
从该描述中我们提取出要使用KMP算法最核心的三个问题:1.滑动的条件 2.滑动的模式 3.滑动距离k的求解
滑动的条件
这部分我们探究当发生“失配”后,主串S中的i应该与模式串T中的第几个字符(这里用K指代)继续进行比较。
在什么条件下我们可以将窗口进行“滑动”?或者说,怎样才叫发生了“部分匹配”?
这里给出严蔚敏版的《数据结构》中,对于“部分匹配”条件的定义(模式串为p,主串为s):
①
\]
②
\]
③
\]
刚看到这三个公式的时候,有点懵,但仔细比对之后可以发现
公式①说明:模式串p从头开始的子串与后面某段已发生“部分匹配”的主串s的子串q相同
公式②说明:模式串p在除开头以外,有一段子串与刚才的子串q发生了“部分匹配”
公式③说明:如果满足上述两个条件,则可以得出模式串p中有两端相同的子串
如果满足以上三个条件(满足前两个条件则第三个必定满足),则可以快速“滑动k个位置”来进行KMP模式匹配
滑动的模式
明确了前提条件之后,我们建立应该next[j]来保存每次比对结束后的K值
约定:
| next[j] | 条件 | 结果 |
|---|---|---|
| 0 | 当j等于1 | 将i向后移动一位 |
| k | 取Kmax,1<k<j 且 满足条件③ | 将模式串的第k位与当前i对齐 |
| 1 | 其他情况 | 将模式串的第1位与当前i对齐 |
反映成代码形式:
滑动距离K的求解
由
\]
- 可知next[j]仅与模式串有关而与主串无关
这里是整个KMP算法的核心部分,在我反反复复看几十遍严蔚敏版的《数据结构》之后,我终于理清了整个求解滑动距离的方法。
整个算法分为两个情况:
\]
以及
\]
若满足第一种情况,有
next[j+1] = next[j] + 1;
若满足第二种情况,则又分为两种情况
- 设K' = next[k],当P[K'] = P[j] 时,有
next[j+1] = next[k] + 1; - 如果一直移动K'到j = 1时,还不能找到对应的P[K'] = P[j],那么直接有
next[j+1] = 1;
在展开讲求next[j]的算法之前,必须要明确的一点是:
- k,j,k',j+1分别代表串中的哪些位置
在这里给出明确定义:
- j+1就是你需要求k值的模式串位置
- j就是当前需要求出K值的字符的前一个字符
- k-1就是“已匹配”的前缀的最后一个字符
- k就是“已匹配”的前缀的最后一个字符的后一个字符
注意
- 前缀一定要包含第1个字符
- 后缀一定要包含希望求得K的字符的前一个字符

如图所示,如果我们要求得串中第5个字符的K值,假设前四个字符K值均已经求得,设我们的目标字符指针为j+1
又有第1个‘a’与第3个‘a'匹配,所以他们分别为k-1和j-1
因此第2个字符为k,第4个字符为j。
- 重点来了
让我们抛出一个例子,来理解next[j]的求法
假设我们已知j=1,2,3,4的next[j]值分别为:0,1,1,2
由于k-1和j-1已经”匹配“,则满足前置匹配条件,我们来比较pk和pj的内容,
pk = b,pj = a;
可见它们并不相等,因此k指向的b会甩锅给“next[k]”字符,而next[k] = 1,也就是串的第一个字符‘a'
第一个字符‘a'成功与第j个字符‘a'相匹配,因此依照我们定义的的pk ≠ pj的第一种情况可以得到
next[j+1] = next[k] + 1 = 2;
由此,我们可以通过之前定义的方式来确定所有的next[j]的值,下面给出串'abaabcac'的所有next[j]的值:
希望读者能拿起笔,从next[2]开始,计算到next[8]

相信计算完上表格的读者,已经对next[j]的计算方法有了更加深刻的理解
在这里我也分享出自己总结的口诀:
- k,j相等,直接加1
- k,j不等,层层甩锅
- 甩锅失败,直接赋1
- 甩锅成功,老板加1
释义:
- pk = pj:next[j+1] = next[j] + 1;
- pk ≠ pj: 甩锅
- p[k'] = pj:next[j+1] = next[k] + 1;
- p[k'] ≠ pj:next[j+1] = 1 or 继续向next[k']甩锅。
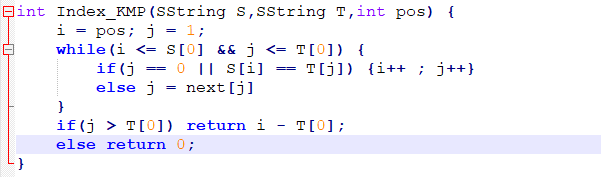
接下来给出代码实现求next[j]:

KMP算法的改进
通过分析代码我们可以发现,当模式串元素有多个重复元素:
他们的next[j]为:0,1,2,3,4
因此在比对时将出现i不动,j从调用next[j]3次的情况,
在这种情况下,我们可以让j=1,2,3,4只进行一次比对就使得i向后移动一位(也就是next[j] = 0)
改进算法如下:
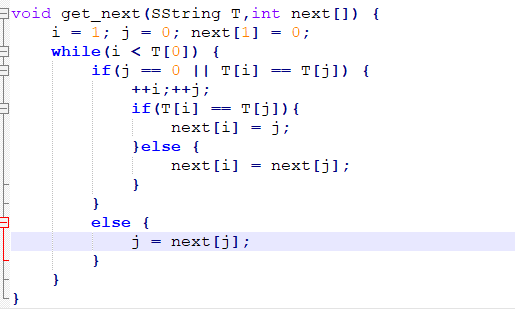
改进之后next[j] = 0,0,0,0,4,成功避免了重复比对
浅谈KMP模式匹配算法的更多相关文章
- KMP模式匹配算法
KMP模式匹配算法 相信很多人对于这个还有点不了解,或者说是不懂,下面,通过一道题,来解决软考中的这个问题! 正题: aaabaaa,其next函数值为多少? 对于这个问题,我们应该怎么做呢? 1.整 ...
- 线性表-串:KMP模式匹配算法
一.简单模式匹配算法(略,逐字符比较即可) 二.KMP模式匹配算法 next数组:j为字符序号,从1开始. (1)当j=1时,next=0: (2)当存在前缀=后缀情况,next=相同字符数+1: ( ...
- C++编程练习(7)----“KMP模式匹配算法“字符串匹配
子串在主串中的定位操作通常称做串的模式匹配. KMP模式匹配算法实现: /* Index_KMP.h头文件 */ #include<string> #include<sstream& ...
- 详细解读KMP模式匹配算法
转载请注明出处:http://blog.csdn.net/fightlei/article/details/52712461 首先我们需要了解什么是模式匹配? 子串定位运算又称为模式匹配(Patter ...
- 浅谈MVVM模式和MVP模式——Vue.js向
浅谈MVVM模式和MVP模式--Vue.js向 传统前端开发的MVP模式 MVP开发模式的理解过程 首先代码分为三层: model层(数据层), presenter层(控制层/业务逻辑相关) view ...
- [从今天开始修炼数据结构]串、KMP模式匹配算法
[从今天开始修炼数据结构]基本概念 [从今天开始修炼数据结构]线性表及其实现以及实现有Itertor的ArrayList和LinkedList [从今天开始修炼数据结构]栈.斐波那契数列.逆波兰四则运 ...
- 字符串的模式匹配算法——KMP模式匹配算法
朴素的模式匹配算法(C++) 朴素的模式匹配算法,暴力,容易理解 #include<iostream> using namespace std; int main() { string m ...
- 串、KMP模式匹配算法
串是由0个或者多个字符组成的有限序列,又名叫字符串. 串的比较: 串的比较是通过组成串的字符之间的编码来进行的,而字符的编码指的是字符在对应字符集中的序号. 计算机中常用的ASCII编码,由8位二进制 ...
- 数据结构(三)串---KMP模式匹配算法
(一)定义 由于BF模式匹配算法的低效(有太多不必要的回溯和匹配),于是某三个前辈发表了一个模式匹配算法,可以大大避免重复遍历的情况,称之为克努特-莫里斯-普拉特算法,简称KMP算法 (二)KMP算法 ...
随机推荐
- MSTP
目录 一.生成树存在的问题 二.MSTP 三.MSTP的网络层次 四.MSTP的端口状态 五.MSTP的保护功能 一.生成树存在的问题 STP和RSTP的问题 PVST的问题 二.MSTP 多生成树 ...
- C++面向对象 1(类-封装)
1 //类和对象 2 //C++ 面向对象 三大特性 : 封装 继承 多态 3 4 //设计一个圆类,求圆的周长 5 //圆周长 = 2*PI * 半径 6 7 #include <iostre ...
- 第一个Java文件
HelloWorld 1.新建一个文件夹,用来存放java文件的 2.用subline来编辑第一个Java文件 要注意的是java的文件名为.java 我们自定义的文件名是Hello 3.编写第一个j ...
- Flink EOS如何防止外部系统乱入--两阶段提交源码
一.前言 根据维基百科的定义,两阶段提交(Two-phase Commit,简称2PC)是巨人们用来解决分布式系统架构下的所有节点在进行事务提交时保持一致性问题而设计的一种算法,也可称之为协议. 在F ...
- Mybatis源码解析2—— 实例搭建
大家好,我是可乐. 上篇文章给大家撸了一遍用 JDBC 直接操作数据库的实例,还只是简单写了一个查询的接口,其代码量就已经很大了,并且可乐还给大家分析了直接使用 JDBC 带来的一些问题,总之是一种反 ...
- gcc limits.h的bug定位看include_next和默认搜索路径
手编的交叉编译工具链经常报一堆宏未定义,例如下面是编译gtest的时候报_POSIX_PATH_MAX宏未定义,有时还会上报SSIZE_MAX等宏未定义: googletest/src/gtest-f ...
- DVWA-全等级SQL注入(显注)
前言: 首先是DVWA环境的搭建: 1.DVWA. 2.PHPSTUDY/WampServer,这里有一个坑,因为他是一体化的,PHP版本必须在5.4以上,否则显注不能打开.或者自己搭建LAMP环境. ...
- stm32高级定时器1互补输出 验证代码
GPIO_InitTypeDef GPIO_InitStructure; TIM_TimeBaseInitTypeDef TIM_TimeBaseStructure; TIM_OCInitTypeDe ...
- 【原创】JavaFx程序解决Jupyter Notebook导出PDF不显示中文
0.ATTENTION!!! JavaFx里是通过Java调用控制台执行的的jupyter和xelatex指令, 这些个指令需要在本地安装Jupyter和MikTeX之后才能正常在电脑上运行 1.[问 ...
- vue--三种组件中之间的传值
参考网址:https://www.jianshu.com/p/46573a741c29 一.父子组件之间的传值----props/$emit 组件之间的传值,我们比较常用到的是props/$emit ...