大数据学习day29-----spark09-------1. 练习: 统计店铺按月份的销售额和累计到该月的总销售额(SQL, DSL,RDD) 2. 分组topN的实现(row_number(), rank(), dense_rank()方法的区别)3. spark自定义函数-UDF
1. 练习
数据:
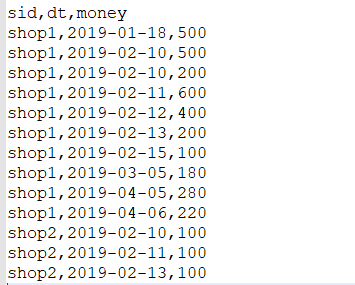
(1)需求1:统计有过连续3天以上销售的店铺有哪些,并且计算出连续三天以上的销售额
第一步:将每天的金额求和(同一天可能会有多个订单)
SELECT
sid,dt,SUM(money) day_money
FROM
v_orders
GROUP BY sid,dt

第二步:给每个商家中每日的订单按时间排序并打上编号
SELECT
sid,dt,day_money,
ROW_NUMBER() OVER(PARTITION BY sid ORDER BY dt) rn
FROM
(
SELECT
sid,dt,SUM(money) day_money
FROM
v_orders
GROUP BY sid,dt
) t1

第三步:获取date与rn的差值的字段
SELECT
sid ,dt,day_money,date_sub(dt,rn) diff
FROM
(
SELECT
sid,dt,day_money,
ROW_NUMBER() OVER(PARTITION BY sid ORDER BY dt) rn
FROM
(
SELECT
sid,dt,SUM(money) day_money
FROM
v_orders
GROUP BY sid,dt
) t1
) t2
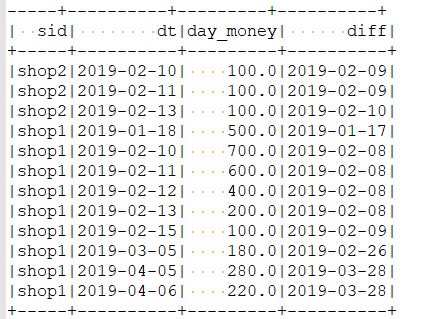
第四步: 最终结果
SELECT
sid,MIN(dt),MAX(dt),SUM(day_money) cmoney,COUNT(*) cc
FROM
(
SELECT
sid ,dt,day_money,date_sub(dt,rn) diff
FROM
(
SELECT
sid,dt,day_money,
ROW_NUMBER() OVER(PARTITION BY sid ORDER BY dt) rn
FROM
(
SELECT
sid,dt,SUM(money) day_money
FROM
v_orders
GROUP BY sid,dt
) t1
) t2
)
GROUP BY sid,diff
HAVING cc >=3

(2)需求2:统计店铺按月份的销售额和累计到该月的总销售额
- SQL风格(只写sq语句,省略代码部分)
SELECT
sid,month,month_sales,
SUM(month_sales) OVER(PARTITION BY sid ORDER BY month) total_sales // 默认是其实位置到当前位置的累加
--PARTITION BY sid ORDER BY mth ASC ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW 完整的写法
FROM
(
SELECT
sid,
DATE_FORMAT(dt,'yyyy-MM') month,
--substr(dt,1,7) month, 用此函数来取月份也行
SUM(money) month_sales
FROM
v_orders
GROUP BY sid, month
)
结果
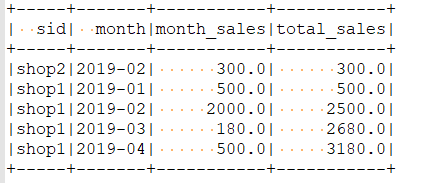
- DSL风格
object RollupMthIncomeDSL {
def main(args: Array[String]): Unit = {
// 创建SparkSession
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName)
.master("local[*]")
.getOrCreate()
// 读取文件创建DataSet
val orders: DataFrame = spark.read
.option("header", "true")
.option("inferSchema", "true") // inferSchema为true可以自动推测数据的类型,默认false,则所有的数据都是String类型的
.csv("F:\\大数据第三阶段\\spark\\spark-day09\\资料\\order.csv")
import spark.implicits._
import org.apache.spark.sql.functions._
// 获取月份,并按照sid和月份进行分组,聚合
val result: DataFrame = orders.groupBy($"sid", date_format($"dt", "yyyy-MM") as "month")
.agg(sum($"money") as "month_sales")
// withColumn相当于在原有基础上再增加一列,此处使用select重新获取表也行
//.select('sid, 'month, 'month_sales, sum('month_sales) over(Window.partitionBy('sid)
// .orderBy('month).rowsBetween(Window.unboundedPreceding, Window.currentRow)) as "rollup_sales")
.withColumn("rollup_sales", sum('month_sales) over (Window.partitionBy('sid) // 'sid相当于$"sid"
.orderBy('month).rowsBetween(Window.unboundedPreceding, Window.currentRow)))
result.show()
spark.stop()
}
}
- RDD风格
object RollupMthIncomeRDD {
def main(args: Array[String]): Unit = {
// 创建SparkContext
val conf = new SparkConf()
.setAppName(this.getClass.getName)
.setMaster("local[*]")
val sc: SparkContext = new SparkContext(conf)
val lines: RDD[String] = sc.textFile("F:\\大数据第三阶段\\spark\\spark-day09\\资料\\order.csv")
val reduced: RDD[((String, String), Double)] = lines.map(line => {
val fields: Array[String] = line.split(",")
val sid: String = fields(0)
val dateStr: String = fields(1)
val month: String = dateStr.substring(0, 7)
val money: Double = fields(2).toDouble
((sid, month), money)
}).reduceByKey(_ + _)
// 按照shop id分组
val result: RDD[(String, String, String, Double)] = reduced.groupBy(_._1._1).mapValues(it => {
//将迭代器中的数据toList放入到内存
//并且按照月份排序【字典顺序】
val sorted: List[((String, String), Double)] = it.toList.sortBy(_._1._2)
var rollup = 0.0
sorted.map(t => {
val sid = t._1._1
val month = t._1._2
val month_sales = t._2
rollup += month_sales
(sid, month, rollup)
})
}).flatMapValues(lst => lst).map(t => (t._1, t._2._1, t._2._2, t._2._3))
result.foreach(println)
sc.stop()
}
}
注意点:可以直接读取csv文件获取DataFram,再获取rdd,如下

2. 分组topN的实现(大数据学习day21中的计算学科最受欢迎老师topN)
- SQL
注意点:此处的文件格式是text的,所以需要用SparkContext的textFile方法来读取数据,然后处理此数据,得到需要的字段(subject,teacher),再利用toDF("subject", "teacher")方法获取对应的DataFrame,从而创建相应的视图
object FavoriteTeacherSQL {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName)
.master("local[*]")
.getOrCreate()
import spark.implicits._
val lines: RDD[String] = spark.sparkContext.textFile("E:\\javafile\\spark\\teacher100.txt")
// 处理数据,获取DataFrame,用于创建视图
val df: DataFrame = lines.map(line => {
val fields = line.split("/")
val subject = fields(2).split("\\.")(0)
val teacher = fields(3)
(subject, teacher)
}).toDF("subject", "teacher")
// 创建视图
df.createTempView("v_teacher")
var topN: Int = 2
// SQL实现分组topN
spark.sql(
s"""
|SELECT
| subject,teacher,counts
| rk
|FROM
|(
| SELECT
| subject,teacher,counts,
| RANK() OVER(PARTITION BY subject ORDER BY counts DESC) rk
| FROM
| (
| SELECT
| subject,teacher,
| count(*) counts
| FROM
| v_teacher
| GROUP BY subject, teacher
| ) t1
|) t2 WHERE rk <= $topN
|""".stripMargin).show()
}
}
此处的小知识点:
row_number(), rank(), dense_rank()方法的区别
row_number() over() 打行号,行号从1开始
rank() over() 排序,有并列,如果有两个第1,就没有第2了,然后直接第3,跳号
dense_rank() over() 排序,有并列,不跳号
- DSL
object FavoriteTeacherDSL {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName)
.master("local[*]")
.getOrCreate()
import spark.implicits._
val lines: RDD[String] = spark.sparkContext.textFile("E:\\javafile\\spark\\teacher100.txt")
// 处理数据,获取DataFrame,用于创建视图
val df: DataFrame = lines.map(line => {
val fields = line.split("/")
val subject = fields(2).split("\\.")(0)
val teacher = fields(3)
(subject, teacher)
}).toDF("subject", "teacher")
import org.apache.spark.sql.functions._
df.groupBy("subject","teacher")
.agg(count("*") as "counts")
.withColumn("rk",dense_rank().over(Window.partitionBy($"subject").orderBy($"counts" desc)) )
.filter('rk <= 2)
.show()
spark.stop()
}
}
3. spark自定义函数-UDF
UDF:一进一出(输入一行,返回一行)
UDTF: 一进多出
UDAF: 多进一出
object MyConcatWsUDF {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName(this.getClass.getSimpleName)
.master("local[*]")
.getOrCreate()
import spark.implicits._
val tp: Dataset[(String, String)] = spark.createDataset(List(("aaa", "bbb"), ("aaa", "ccc"), ("aaa", "ddd")))
val df: DataFrame = tp.toDF("f1", "f2")
//注册自定义函数
//MY_CONCAT_WS函数名称
//后面传入的scala的函数就是具有的实现逻辑
spark.udf.register("MY_CONCAT_WS", (s: String, first: String, second:String) => {
first + s + second
})
import org.apache.spark.sql.functions._
//df.selectExpr("CONCAT_WS('-', f1, f2) as f3")
//df.select(concat_ws("-", $"f1", 'f2) as "f3").show()
//df.selectExpr("MY_CONCAT_WS('_', f1, f2) as f3").show()
df.createTempView("v_data")
spark.sql(
"""
|SELECT MY_CONCAT_WS('-', f1, f2) f3 FROM v_data
""".stripMargin).show()
spark.stop()
}
}
大数据学习day29-----spark09-------1. 练习: 统计店铺按月份的销售额和累计到该月的总销售额(SQL, DSL,RDD) 2. 分组topN的实现(row_number(), rank(), dense_rank()方法的区别)3. spark自定义函数-UDF的更多相关文章
- Spark(十三)SparkSQL的自定义函数UDF与开窗函数
一 自定义函数UDF 在Spark中,也支持Hive中的自定义函数.自定义函数大致可以分为三种: UDF(User-Defined-Function),即最基本的自定义函数,类似to_char,to_ ...
- 大数据学习——hive函数
1 内置函数 测试各种内置函数的快捷方法: 1.创建一个dual表 create table dual(id string); 2.load一个文件(一行,一个空格)到dual表 3.select s ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据学习系列之九---- Hive整合Spark和HBase以及相关测试
前言 在之前的大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 中介绍了集群的环境搭建,但是在使用hive进行数据查询的时候会非常的慢,因为h ...
- SparkSQL中的自定义函数UDF
在Spark中,也支持Hive中的自定义函数.自定义函数大致可以分为三种: UDF(User-Defined-Function),即最基本的自定义函数,类似to_char,to_date等 UDAF( ...
- 大数据学习(一) | 初识 Hadoop
作者: seriouszyx 首发地址:https://seriouszyx.top/ 代码均可在 Github 上找到(求Star) 最近想要了解一些前沿技术,不能一门心思眼中只有 web,因为我目 ...
- 大数据学习笔记——Hadoop编程实战之Mapreduce
Hadoop编程实战——Mapreduce基本功能实现 此篇博客承接上一篇总结的HDFS编程实战,将会详细地对mapreduce的各种数据分析功能进行一个整理,由于实际工作中并不会过多地涉及原理,因此 ...
- 10_Hive自定义函数UDF
Hive官方的UDF手册地址是:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF 1.使用内置函数的快捷方法: 创 ...
随机推荐
- Python 类似 SyntaxError: Non-ASCII character '\xc3' in file
Python 类似 SyntaxError: Non-ASCII character '\xc3' in file 产生这个问题的原因: python 的默认编码文件是ACSII,而编辑器将文件保存为 ...
- Android现有工程使用Compose
Android现有工程使用Compose 看了Compose的示例工程后,我们也想使用Compose.基于目前情况,在现有工程基础上添加Compose功能. 引入Compose 首先我们安装 Andr ...
- [python]基于windows搭建django项目
1.首先我的环境用到的库版本如下,若下载直接pip即可 pip3 install Django==2.0.6pip3 install djangorestframework==3.8.2pip3 in ...
- Mac Python相关配置操作汇总
以下总结一下我在安装pytorch时用到的一些命令及操作,方便以后回顾 一.Which xxxx 直接查找到xxxx所在的路径.如下: which python python: aliased to ...
- Android Activity Deeplink启动来源获取源码分析
一.前言 目前有很多的业务模块提供了Deeplink服务,Deeplink简单来说就是对外部应用提供入口. 针对不同的跳入类型,app可能会选择提供不一致的服务,这个时候就需要对外部跳入的应用进行区分 ...
- win8中让cmd.exe始终以管理员身份运行
最近在学习配置本地服务器,在命令行启动mysql时总是由于权限不足而失败, Win+R -- cmd ,这样总是不能,还要找到cmd.exe右键以管理员身份运行cmd,再 net start mysq ...
- Redis篇:事务和lua脚本的使用
现在多数秒杀,抽奖,抢红包等大并发高流量的功能一般都是基于 redis 实现,然而在选择 redis 的时候,我们也要了解 redis 如何保证服务正确运行的原理 前言 redis 如何实现高性能和高 ...
- [loj3179]视觉程序
暴力做法:1.对每一行/列求$or$:2.枚举行的差值$i$,并对任意相差为$i$的行和相差为$k-i$的列求$and$,对行/列的$and$结果求$or$,对行和列的$or$求$and$,对所有$i ...
- MyBatis-Plus中如何使用ResultMap
MyBatis-Plus (简称MP)是一个MyBatis的增强工具,在MyBatis的基础上只做增强不做改变,为简化开发.提高效率而生. MyBatis-Plus对MyBatis基本零侵入,完全可以 ...
- Sentry 监控 - Snuba 数据中台架构(编写和测试 Snuba 查询)
系列 1 分钟快速使用 Docker 上手最新版 Sentry-CLI - 创建版本 快速使用 Docker 上手 Sentry-CLI - 30 秒上手 Source Maps Sentry For ...