跳表--怎么让一个有序链表能够进行"二分"查找?
对于一个有序数组,如果要查找其中的一个数,我们可以使用二分查找(Binary Search)算法,将它的时间复杂度降低为O(logn).那查找一个有序链表,有没有办法将其时间复杂度也降低为O(logn)呢?
跳表(skip list),全称为跳跃链表,实质上就是一种可以进行二分查找的有序链表,它允许快速查询、插入和删除有序链表。
跳表使用的前提是链表有序,就像二分查找也要求有序数组
怎么理解跳表
比如我们有一个原始有序链表,如下图所示。
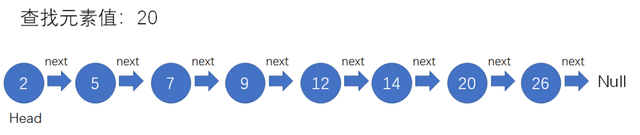
要查找其中值为20的元素,之前都是采取按顺序进行遍历的方法,但这样做时间复杂度就变成了O(n).怎样才能提高效率呢?我们可以通过对链表建立一级索引,查找的时候先遍历索引,通过索引找到原始层继续遍历。索引如下图所示

那么查找20的过程就变成了先使用索引遍历 2 -> 7 -> 12 -> 20,然后顺着索引链表的结点向下找到原始链表的结点20.之前需要遍历7次,现在需要遍历5次。在数据量小的时候跳表性能优化并不明显,但当有序链表包含大量数据时,结点的访问次数大致会减少一半。
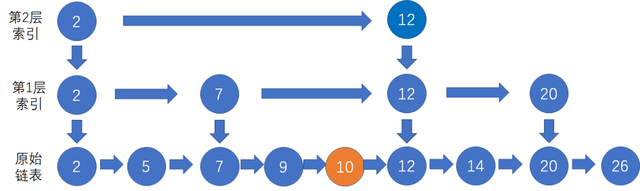
现在我们添加两层索引,基于第一层的索引再添加一层,如下图所示

要查找20,先在第二层索引上遍历 2 -> 12 ,然后向下转到第一层索引遍历 12 - > 20,最后向下找到原始链表的结点20.
这个例子中,原始有序链表的结点数量很少,当结点数量很多时,可以抽出更多的索引层级,每一层索引结点的数量都是低层索引的一半。
跳表复杂度分析
时间复杂度
算法的执行效率可以通过时间复杂度来衡量,跳表的时间复杂度是多少呢?我们来分析一下。
前面我们每两个结点抽一个结点作为上一级索引的结点,那么假设原始链表的长度为n,第一层索引的结点个数为n/2,第二层索引的个数为n/4,第k级的索引结点个数就是n/(2k)。假设索引有 h 级,最高级的索引有 2 个结点。通过上面的公式,我们可以得到 n/(2h)=2,从而求得 h=log2n-1。如果包含原始链表这一层,整个跳表的高度就是 log2n。我们在跳表中查询某个数据的时候,如果每一层都要遍历 m 个结点,那在跳表中查询一个数据的时间复杂度就是 O(m*logn)。
m的值怎么计算呢?在上面的例子中,每一层最多只需要遍历三个元素,因此m=3,根据时间复杂度的计算规则,高阶的常数项也可以省略,因此跳表中查询任意数据的时间复杂度就是O(logn)
空间复杂度
每两个结点中抽一个结点作为上级索引,很明显,它的空间复杂度为O(n).
♂这是一个典型的空间换时间操作。原始链表中存储的有可能是很大的对象,而索引结点只需要存储关键值和几个指针,并不需要存储对象,所以当对象比索引结点大很多时,索引占用的额外空间就可以忽略了。
高效的插入和删除
插入操作
向链表插入数据的时间复杂度是O(1),但为了保持链表数据有序,需要先找到插入结点的前置结点,然后插入数据到前置结点后面,其时间复杂度为O(logn)。假设我们要插入10,需要先找到前置结点9,然后插入10。
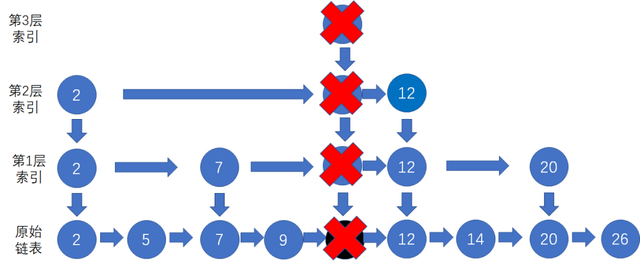
删除操作
删除的话也是需要先找到要删除的结点,如果该结点在索引中也有出现的话,索引中的也需要删除。因为单链表中的删除操作需要拿到要删除结点的前驱结点,然后通过指针操作完成删除。所以在查找要删除的结点的时候,一定要获取前驱结点。
动态更新索引
当我们一直往跳表中插入数据时,两个索引结点之间的数据可能会变得非常多,在极端情况下,跳表还会退化成单链表,这样的话跳表的优势也就没有了。
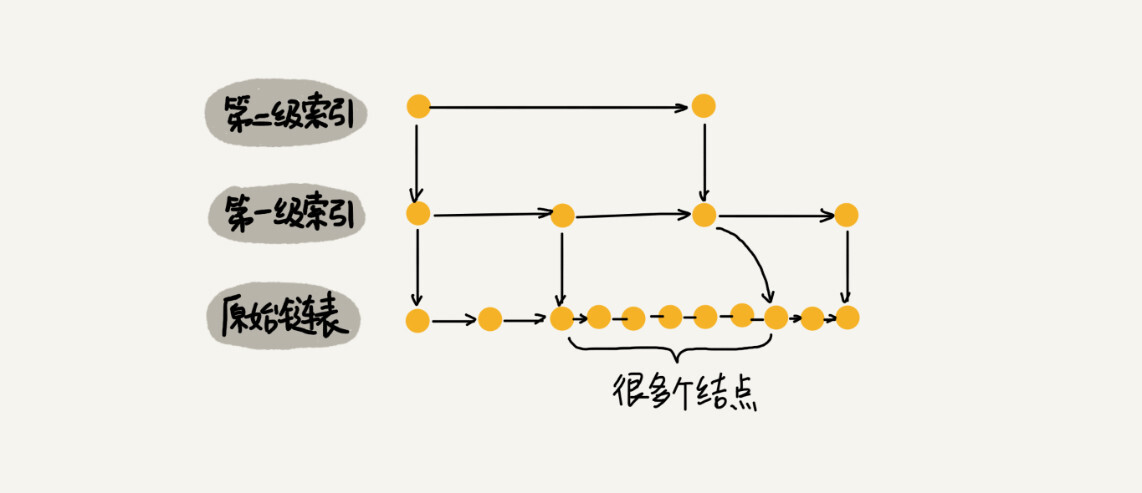
因此我们需要用一些方法来维护索引和原始链表之间的平衡,也就是在增加原始链表中结点内容的时候适当增加索引的大小。为了维护平衡,跳表的设计者采用了一种有趣的方法:“抛硬币”,也就是随机决定新结点是否建立索引,两个结点建立一个索引的话,每层的概率为50%。
Java实现跳表
下面是王争老师 数据结构与算法之美 课程中的代码
package skiplist;
/**
* 跳表的一种实现方法。
* 跳表中存储的是正整数,并且存储的是不重复的。
*
* Author:ZHENG
*/
public class SkipList {
private static final float SKIPLIST_P = 0.5f;
private static final int MAX_LEVEL = 16;
private int levelCount = 1;
private Node head = new Node(); // 带头链表
public Node find(int value) {
Node p = head;
for (int i = levelCount - 1; i >= 0; --i) {
while (p.forwards[i] != null && p.forwards[i].data < value) {
p = p.forwards[i];
}
}
if (p.forwards[0] != null && p.forwards[0].data == value) {
return p.forwards[0];
} else {
return null;
}
}
public void insert(int value) {
int level = randomLevel();
Node newNode = new Node();
newNode.data = value;
newNode.maxLevel = level;
Node update[] = new Node[level];
for (int i = 0; i < level; ++i) {
update[i] = head;
}
// record every level largest value which smaller than insert value in update[]
Node p = head;
for (int i = level - 1; i >= 0; --i) {
while (p.forwards[i] != null && p.forwards[i].data < value) {
p = p.forwards[i];
}
update[i] = p;// use update save node in search path
}
// in search path node next node become new node forwords(next)
for (int i = 0; i < level; ++i) {
newNode.forwards[i] = update[i].forwards[i];
update[i].forwards[i] = newNode;
}
// update node hight
if (levelCount < level) levelCount = level;
}
public void delete(int value) {
Node[] update = new Node[levelCount];
Node p = head;
for (int i = levelCount - 1; i >= 0; --i) {
while (p.forwards[i] != null && p.forwards[i].data < value) {
p = p.forwards[i];
}
update[i] = p;
}
if (p.forwards[0] != null && p.forwards[0].data == value) {
for (int i = levelCount - 1; i >= 0; --i) {
if (update[i].forwards[i] != null && update[i].forwards[i].data == value) {
update[i].forwards[i] = update[i].forwards[i].forwards[i];
}
}
}
while (levelCount>1&&head.forwards[levelCount]==null){
levelCount--;
}
}
// 理论来讲,一级索引中元素个数应该占原始数据的 50%,二级索引中元素个数占 25%,三级索引12.5% ,一直到最顶层。
// 因为这里每一层的晋升概率是 50%。对于每一个新插入的节点,都需要调用 randomLevel 生成一个合理的层数。
// 该 randomLevel 方法会随机生成 1~MAX_LEVEL 之间的数,且 :
// 50%的概率返回 1
// 25%的概率返回 2
// 12.5%的概率返回 3 ...
private int randomLevel() {
int level = 1;
while (Math.random() < SKIPLIST_P && level < MAX_LEVEL)
level += 1;
return level;
}
public void printAll() {
Node p = head;
while (p.forwards[0] != null) {
System.out.print(p.forwards[0] + " ");
p = p.forwards[0];
}
System.out.println();
}
public class Node {
private int data = -1;
private Node forwards[] = new Node[MAX_LEVEL];
private int maxLevel = 0;
@Override
public String toString() {
StringBuilder builder = new StringBuilder();
builder.append("{ data: ");
builder.append(data);
builder.append("; levels: ");
builder.append(maxLevel);
builder.append(" }");
return builder.toString();
}
}
}总结

跳表--怎么让一个有序链表能够进行"二分"查找?的更多相关文章
- [PHP] 算法-合并两个有序链表为一个有序链表的PHP实现
合并两个有序的链表为一个有序的链表: 类似归并排序中合并两个数组的部分 1.遍历链表1和链表2,比较链表1和2中的元素大小 2.如果链表1结点大于链表2的结点,该结点放入第三方链表 3.链表1往下走一 ...
- 【LC_Lesson7】---将两个有序链表合成新的一个有序链表
将两个有序链表合并为一个新的有序链表并返回.新链表是通过拼接给定的两个链表的所有节点组成的. 示例: 输入:1->2->4, 1->3->4 输出:1->1->2- ...
- 从一个NOI题目再学习二分查找。
二分法的基本思路是对一个有序序列(递增递减都可以)查找时,测试一个中间下标处的值,若值比期待值小,则在更大的一侧进行查找(反之亦然),查找时再次二分.这比顺序访问要少很多访问量,效率很高. 设:low ...
- Search in Rotated Sorted Array, 查找反转有序序列。利用二分查找的思想。反转序列。
问题描述:一个有序序列经过反转,得到一个新的序列,查找新序列的某个元素.12345->45123. 算法思想:利用二分查找的思想,都是把要找的目标元素限制在一个小范围的有序序列中.这个题和二分查 ...
- leetcode 31. Next Permutation (下一个排列,模拟,二分查找)
题目链接 31. Next Permutation 题意 给定一段排列,输出其升序相邻的下一段排列.比如[1,3,2]的下一段排列为[2,1,3]. 注意排列呈环形,即[3,2,1]的下一段排列为[1 ...
- C语言跳表(skiplist)实现
一.简介 跳表(skiplist)是一个非常优秀的数据结构,实现简单,插入.删除.查找的复杂度均为O(logN).LevelDB的核心数据结构是用跳表实现的,redis的sorted set数据结构也 ...
- 【转】SkipList跳表基本原理
增加了向前指针的链表叫作跳表.跳表全称叫做跳跃表,简称跳表.跳表是一个随机化的数据结构,实质就是一种可以进行二分查找的有序链表.跳表在原有的有序链表上面增加了多级索引,通过索引来实现快速查找.跳表不仅 ...
- 跳表(SkipList)设计与实现(Java)
微信搜一搜「bigsai」关注这个有趣的程序员 文章已收录在 我的Github bigsai-algorithm 欢迎star 前言 跳表是面试常问的一种数据结构,它在很多中间件和语言中得到应用,我们 ...
- 聊聊Mysql索引和redis跳表 ---redis的有序集合zset数据结构底层采用了跳表原理 时间复杂度O(logn)(阿里)
redis使用跳表不用B+数的原因是:redis是内存数据库,而B+树纯粹是为了mysql这种IO数据库准备的.B+树的每个节点的数量都是一个mysql分区页的大小(阿里面试) 还有个几个姊妹篇:介绍 ...
随机推荐
- 关于 java编程思想第五版 《On Java 8》
On Java 8中文版 英雄召集令 这是该项目的GITHUB地址:https://github.com/LingCoder/OnJava8 广招天下英雄,为开源奉献!让我们一起来完成这本书的翻译吧! ...
- Oracle插入中文乱码问题
PLSQL执行一条插入代码,两个字符既显示超长,一个字符插入后乱码 insert into person (pid, pname) values (1,'明'); Google查询说原因是Oracle ...
- Js/jquery常用
id属性不能有空格 1. js判断checkebox是否被选中 var ischecked = document.getElementById("xxx").checked // ...
- Flink Streaming状态处理(Working with State)
参考来源: https://www.jianshu.com/p/6ed0ef5e2b74 https://blog.csdn.net/Fenggms/article/details/102855159 ...
- 给MediaWiki增加看板娘
我们想给我们的mediawiki增加个像我博客里这样的看板娘,那么怎么做才好呢? 其实很简单,只要在相应的模板文件里增加指定代码就好了! 修改模板文件 找到模板文件skins/Vector/Vecto ...
- MediaWiki 语法简介
本文尚在完善中... 图片 图片官方教程 图文并茂的内容读起来总是更加舒服,让我们在wiki里引入图片. 内部图片 上传图片 点击右侧上传文件,上传文件后会获得文件名 编辑图片 文件上传后在编辑框,如 ...
- VSCode添加某个插件后,Python 运行时出现Segmentation fault (core dumped) 解决办法
在VSCode添加某个插件后,Debug出现Segmentation fault (core dumped) 解决方案,在当前environment下运行: conda update --all
- 阿里云服务器部署mongodb
在阿里云上买了个服务器,部署mongodb遇到一些坑,解决办法也是从网上搜集而来,把零零碎碎的整理记录一下. 服务器是:Alibaba Cloud Linux 下载安装 mongodb官网下载实在是太 ...
- CentOS 7.3安装Zabbix3.2
一.ZABBIX概述 Zabbix是一个基于Web界面的分布式系统监控的企业级开源软件.可以监视各种系统与设备的参数,保障服务器及设备的安全运营. Zabbix的功能和特性: 1.安装与配置简单: ...
- Linux档案权限篇之一
一.查看档案的属性 "ls" 第一列为档案的权限: d:代表是目录 -:代表是文件 l:代表是连接文件(相当于windows里面的快捷方式) b:代表块设备(如硬盘) c:代表字符 ...