Java实现缓存(LRU,FIFO)
现在软件或者网页的并发量越来越大了,大量请求直接操作数据库会对数据库造成很大的压力,处理大量连接和请求就会需要很长时间,但是实际中百分之80的数据是很少更改的,这样就可以引入缓存来进行读取,减少数据库的压力。
常用的缓存有Redis和memcached,但是有时候一些小场景就可以直接使用Java实现缓存,就可以满足这部分服务的需求。
缓存主要有LRU和FIFO,LRU是Least Recently Used的缩写,即最近最久未使用,FIFO就是先进先出,下面就使用Java来实现这两种缓存。
LRU
LRU缓存的思想
- 固定缓存大小,需要给缓存分配一个固定的大小。
- 每次读取缓存都会改变缓存的使用时间,将缓存的存在时间重新刷新。
- 需要在缓存满了后,将最近最久未使用的缓存删除,再添加最新的缓存。
按照如上思想,可以使用LinkedHashMap来实现LRU缓存。
这是LinkedHashMap的一个构造函数,传入的第三个参数accessOrder为true的时候,就按访问顺序对LinkedHashMap排序,为false的时候就按插入顺序,默认是为false的。
当把accessOrder设置为true后,就可以将最近访问的元素置于最前面,这样就可以满足上述的第二点。
/**
* Constructs an empty <tt>LinkedHashMap</tt> instance with the
* specified initial capacity, load factor and ordering mode.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @param accessOrder the ordering mode - <tt>true</tt> for
* access-order, <tt>false</tt> for insertion-order
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
这是LinkedHashMap中另外一个方法,当返回true的时候,就会remove其中最久的元素,可以通过重写这个方法来控制缓存元素的删除,当缓存满了后,就可以通过返回true删除最久未被使用的元素,达到LRU的要求。这样就可以满足上述第三点要求。
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
由于LinkedHashMap是为自动扩容的,当table数组中元素大于Capacity * loadFactor的时候,就会自动进行两倍扩容。但是为了使缓存大小固定,就需要在初始化的时候传入容量大小和负载因子。
为了使得到达设置缓存大小不会进行自动扩容,需要将初始化的大小进行计算再传入,可以将初始化大小设置为(缓存大小 / loadFactor) + 1,这样就可以在元素数目达到缓存大小时,也不会进行扩容了。这样就解决了上述第一点问题。
通过上面分析,实现下面的代码
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.Set;
public class LRU1<K, V> {
private final int MAX_CACHE_SIZE;
private final float DEFAULT_LOAD_FACTORY = 0.75f;
LinkedHashMap<K, V> map;
public LRU1(int cacheSize) {
MAX_CACHE_SIZE = cacheSize;
int capacity = (int)Math.ceil(MAX_CACHE_SIZE / DEFAULT_LOAD_FACTORY) + 1;
/*
* 第三个参数设置为true,代表linkedlist按访问顺序排序,可作为LRU缓存
* 第三个参数设置为false,代表按插入顺序排序,可作为FIFO缓存
*/
map = new LinkedHashMap<K, V>(capacity, DEFAULT_LOAD_FACTORY, true) {
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > MAX_CACHE_SIZE;
}
};
}
public synchronized void put(K key, V value) {
map.put(key, value);
}
public synchronized V get(K key) {
return map.get(key);
}
public synchronized void remove(K key) {
map.remove(key);
}
public synchronized Set<Map.Entry<K, V>> getAll() {
return map.entrySet();
}
@Override
public String toString() {
StringBuilder stringBuilder = new StringBuilder();
for (Map.Entry<K, V> entry : map.entrySet()) {
stringBuilder.append(String.format("%s: %s ", entry.getKey(), entry.getValue()));
}
return stringBuilder.toString();
}
public static void main(String[] args) {
LRU1<Integer, Integer> lru1 = new LRU1<>(5);
lru1.put(1, 1);
lru1.put(2, 2);
lru1.put(3, 3);
System.out.println(lru1);
lru1.get(1);
System.out.println(lru1);
lru1.put(4, 4);
lru1.put(5, 5);
lru1.put(6, 6);
System.out.println(lru1);
}
}
运行结果:
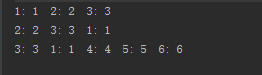
从运行结果中可以看出,实现了LRU缓存的思想。
接着使用HashMap和链表来实现LRU缓存。
主要的思想和上述基本一致,每次添加元素或者读取元素就将元素放置在链表的头,当缓存满了之后,就可以将尾结点元素删除,这样就实现了LRU缓存。
这种方法中是通过自己编写代码移动结点和删除结点,为了防止缓存大小超过限制,每次进行put的时候都会进行检查,若缓存满了则删除尾部元素。
import java.util.HashMap;
/**
* 使用cache和链表实现缓存
*/
public class LRU2<K, V> {
private final int MAX_CACHE_SIZE;
private Entry<K, V> head;
private Entry<K, V> tail;
private HashMap<K, Entry<K, V>> cache;
public LRU2(int cacheSize) {
MAX_CACHE_SIZE = cacheSize;
cache = new HashMap<>();
}
public void put(K key, V value) {
Entry<K, V> entry = getEntry(key);
if (entry == null) {
if (cache.size() >= MAX_CACHE_SIZE) {
cache.remove(tail.key);
removeTail();
}
entry = new Entry<>();
entry.key = key;
entry.value = value;
moveToHead(entry);
cache.put(key, entry);
} else {
entry.value = value;
moveToHead(entry);
}
}
public V get(K key) {
Entry<K, V> entry = getEntry(key);
if (entry == null) {
return null;
}
moveToHead(entry);
return entry.value;
}
public void remove(K key) {
Entry<K, V> entry = getEntry(key);
if (entry != null) {
if (entry == head) {
Entry<K, V> next = head.next;
head.next = null;
head = next;
head.pre = null;
} else if (entry == tail) {
Entry<K, V> prev = tail.pre;
tail.pre = null;
tail = prev;
tail.next = null;
} else {
entry.pre.next = entry.next;
entry.next.pre = entry.pre;
}
cache.remove(key);
}
}
private void removeTail() {
if (tail != null) {
Entry<K, V> prev = tail.pre;
if (prev == null) {
head = null;
tail = null;
} else {
tail.pre = null;
tail = prev;
tail.next = null;
}
}
}
private void moveToHead(Entry<K, V> entry) {
if (entry == head) {
return;
}
if (entry.pre != null) {
entry.pre.next = entry.next;
}
if (entry.next != null) {
entry.next.pre = entry.pre;
}
if (entry == tail) {
Entry<K, V> prev = entry.pre;
if (prev != null) {
tail.pre = null;
tail = prev;
tail.next = null;
}
}
if (head == null || tail == null) {
head = tail = entry;
return;
}
entry.next = head;
head.pre = entry;
entry.pre = null;
head = entry;
}
private Entry<K, V> getEntry(K key) {
return cache.get(key);
}
private static class Entry<K, V> {
Entry<K, V> pre;
Entry<K, V> next;
K key;
V value;
}
@Override
public String toString() {
StringBuilder stringBuilder = new StringBuilder();
Entry<K, V> entry = head;
while (entry != null) {
stringBuilder.append(String.format("%s:%s ", entry.key, entry.value));
entry = entry.next;
}
return stringBuilder.toString();
}
public static void main(String[] args) {
LRU2<Integer, Integer> lru2 = new LRU2<>(5);
lru2.put(1, 1);
System.out.println(lru2);
lru2.put(2, 2);
System.out.println(lru2);
lru2.put(3, 3);
System.out.println(lru2);
lru2.get(1);
System.out.println(lru2);
lru2.put(4, 4);
lru2.put(5, 5);
lru2.put(6, 6);
System.out.println(lru2);
}
}
运行结果:
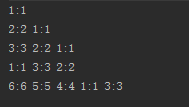
FIFO
FIFO就是先进先出,可以使用LinkedHashMap进行实现。
当第三个参数传入为false或者是默认的时候,就可以实现按插入顺序排序,就可以实现FIFO缓存了。
/**
* Constructs an empty <tt>LinkedHashMap</tt> instance with the
* specified initial capacity, load factor and ordering mode.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @param accessOrder the ordering mode - <tt>true</tt> for
* access-order, <tt>false</tt> for insertion-order
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
实现代码跟上述使用LinkedHashMap实现LRU的代码基本一致,主要就是构造函数的传值有些不同。
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.Set;
public class LRU1<K, V> {
private final int MAX_CACHE_SIZE;
private final float DEFAULT_LOAD_FACTORY = 0.75f;
LinkedHashMap<K, V> map;
public LRU1(int cacheSize) {
MAX_CACHE_SIZE = cacheSize;
int capacity = (int)Math.ceil(MAX_CACHE_SIZE / DEFAULT_LOAD_FACTORY) + 1;
/*
* 第三个参数设置为true,代表linkedlist按访问顺序排序,可作为LRU缓存
* 第三个参数设置为false,代表按插入顺序排序,可作为FIFO缓存
*/
map = new LinkedHashMap<K, V>(capacity, DEFAULT_LOAD_FACTORY, false) {
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > MAX_CACHE_SIZE;
}
};
}
public synchronized void put(K key, V value) {
map.put(key, value);
}
public synchronized V get(K key) {
return map.get(key);
}
public synchronized void remove(K key) {
map.remove(key);
}
public synchronized Set<Map.Entry<K, V>> getAll() {
return map.entrySet();
}
@Override
public String toString() {
StringBuilder stringBuilder = new StringBuilder();
for (Map.Entry<K, V> entry : map.entrySet()) {
stringBuilder.append(String.format("%s: %s ", entry.getKey(), entry.getValue()));
}
return stringBuilder.toString();
}
public static void main(String[] args) {
LRU1<Integer, Integer> lru1 = new LRU1<>(5);
lru1.put(1, 1);
lru1.put(2, 2);
lru1.put(3, 3);
System.out.println(lru1);
lru1.get(1);
System.out.println(lru1);
lru1.put(4, 4);
lru1.put(5, 5);
lru1.put(6, 6);
System.out.println(lru1);
}
}
运行结果:

以上就是使用Java实现这两种缓存的方式,从中可以看出,LinkedHashMap实现缓存较为容易,因为底层函数对此已经有了支持,自己编写链表实现LRU缓存也是借鉴了LinkedHashMap中实现的思想。在Java中不只是这两种数据结构可以实现缓存,比如ConcurrentHashMap、WeakHashMap在某些场景下也是可以作为缓存的,到底用哪一种数据结构主要是看场景再进行选择,但是很多思想都是可以通用的。
Java实现缓存(LRU,FIFO)的更多相关文章
- cache4j轻量级java内存缓存框架,实现FIFO、LRU、TwoQueues缓存模型
简介 cache4j是一款轻量级java内存缓存框架,实现FIFO.LRU.TwoQueues缓存模型,使用非常方便. cache4j为java开发者提供一种更加轻便的内存缓存方案,杀鸡焉用EhCac ...
- java 开源缓存框架--转载
原文地址:http://www.open-open.com/13.htm JBossCache/TreeCache JBossCache是一个复制的事务处理缓存,它允许你缓存企业级应用数据来更好的 ...
- java的缓存框架
1.java里面有一些开源的缓存框架,比如ecache,memcache,redis等缓存框架. 2.使用缓存框架的原理就是减少数据库端的压力,将缓存数据放在内存里面,存储成键值对的格式,这样可以不去 ...
- 5个强大的Java分布式缓存框架推荐
在开发中大型Java软件项目时,很多Java架构师都会遇到数据库读写瓶颈,如果你在系统架构时并没有将缓存策略考虑进去,或者并没有选择更优的 缓存策略,那么到时候重构起来将会是一个噩梦.本文主要是分享了 ...
- 5个强大的Java分布式缓存框架
在开发中大型Java软件项目时,很多Java架构师都会遇到数据库读写瓶颈,如果你在系统架构时并没有将缓存策略考虑进去,或者并没有选择更优的缓存策略,那么到时候重构起来将会是一个噩梦.本文主要是分享了5 ...
- Java分布式缓存框架
http://developer.51cto.com/art/201411/457423.htm 在开发中大型Java软件项目时,很多Java架构师都会遇到数据库读写瓶颈,如果你在系统架构时并没有将缓 ...
- java动态缓存技术:WEB缓存应用(转)
可以实现不等待,线程自动更新缓存 Java动态缓存jar包请下载. 源代码: CacheData.java 存放缓存数据的Bean /** * */package com.cari.web.cach ...
- Java实现缓存(类似于Redis)
Java实现缓存,类似于Redis的实现,可以缓存对象到内存中,提高访问效率.代码如下: import java.util.ArrayList; import java.util.HashMap; i ...
- java中间变量缓存机制
public class Demo { public static void main(String[] args){ method_1(); method_2(); } private static ...
随机推荐
- webpack入门与解析(一)
每次学新东西总感觉自己是不是变笨了,看了几个博客,试着试着就跑不下去,无奈只有去看官方文档. webpack是基于node的.先安装最新的node. 1.初始化 安装node后,新建一个目录,比如ht ...
- JAVA试练塔之试炼技能图
1.计算机基础: 1.1数据机构基础: 主要学习: 1.向量,链表,栈,队列和堆,词典.熟悉 2.树,二叉搜索树.熟悉 3.图,有向图,无向图,基本概念 4.二叉搜索A,B,C类熟练,9大排序熟悉. ...
- 一步一步学Python(2) 连接多台主机执行脚本
最近在客户现场,每日都需要巡检大量主机系统的备库信息.如果一台台执行,时间浪费的就太冤枉了. 参考同事之前写的一个python脚本,配合各主机上写好的shell检查脚本,实现一次操作得到所有巡检结果. ...
- 【java基础之jdk源码】Object
最新在整体回归下java基础薄弱环节,以下为自己整理笔记,若有理解错误,请批评指正,谢谢. java.lang.Object为java所有类的基类,所以一般的类都可用重写或直接使用Object下方法, ...
- 本地Solr服务器搭建
一.Solr官网下载http://lucene.apache.org/solr/下载Solr项目文件 在该项目文件中,可以找到我们在本地环境下运行Solr服务器所需要的资源文件,在这里我们以4.10. ...
- SuperWebClient -一个基于CURL的.NET HTTP/HTTPS模拟神组件(1)
我们都知道,不管你是做爬虫也好,采集工具也罢,它们的HTTP/HTTPS模拟访问总是一个基础问题,我估计有很多人和我一样,虽然这样,那样的内置或是第三方类库用了很多,却总是会有一些不如意的问题存在,亦 ...
- iOS 用Swipe手势和动画实现循环播放图片
主要想法 添加3个ImageView展示图片,实现图片的无限循环. 使用Swipe手势识别用户向右或向左滑动图片. 使用CATransition给ImageView.layer添加动画,展示图片更换的 ...
- Git 基本工作流程
1. 用户信息配置(全局配置) $ git config --global user.name leo$ git config --global user.email hehe_xiao@qq.com ...
- iOS 推送全解析,你不可不知的所有 Tips!
本文旨在对 iOS 推送进行一个完整的剖析,如果你之前对推送一无所知,那么在你认真地阅读了全文后必将变成一个推送老手,你将会对其中的各种细节和原理有充分的理解.以下是 pikacode 使用 iOS ...
- Java面试03|并发及锁
1.synchronized与Lock的区别 使用synchronized这个关键字实现的同步块有一些缺点: (1)锁只有一种类型 (2)线程得到锁或者阻塞 (3)Lock是在Java语言层面基于CA ...