SQLServer 索引总结
测试案例:
SET STATISTICS IO ON
SET STATISTICS TIME ON
SET STATISTICS PROFILE ON
SELECT count(A.CarrierTrackingNumber) FROM SALES.SALESORDERDETAIL A
WHERE A.SalesOrderDetailID>10000 AND A.SalesOrderDetailID<10100
执行计划:

测试loopup 和索引查找:
第一步 走了扫描 和通过聚集索引查找 OutputList字段;
我们这里可以添加索引 不过建议创建包含索引;复合索引快 但是维护起来要复杂些,也影响性能;
我做了下比较:
CREATE NONCLUSTERED INDEX [IX_TEST] ON [Sales].[SalesOrderDetail]
(
[SalesOrderDetailID] ASC
)
INCLUDE ( [CarrierTrackingNumber]) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)
GO
CREATE NONCLUSTERED INDEX [IX_TEST1] ON [Sales].[SalesOrderDetail]
(
[SalesOrderDetailID],[CarrierTrackingNumber] ASC
)
WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)
GO
蓝色是包含索引,红色是复合索引,我们无论单独创建哪个索引他都会把第一步合成一个步骤索引查找;(就不截图了)
然后我们做下两者的速度;
DBCC FREEPROCCACHE

测试包含、联合索引:
查询优化器智能走向是test1 复合索引;
我们看下io开销:
包含索引test:

复合索引:

复合索引逻辑读是3,这个很好解释,因为联合索引的索引叶要比包含索引叶子大,包含索引是只是存储包含字段的一个指针,而复合是实际的值;
如果数据量很大,性能差距也很明显:
我们把条件改下,返回的结果集大点,然后下面一句我们使用强制索引,强制语句选择使用包含索引:

轻而易举我们发现ix_test1 联合索引 明显绝对性优势;
计算函数对索引影响:
SELECT count(A.CarrierTrackingNumber) FROM SALES.SALESORDERDETAIL A
WHERE CONVERT(NUMERIC(9,3),A.SALESORDERDETAILID/100)=100
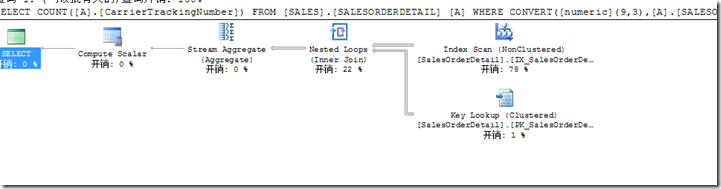
这个字段我们上面两个索引都加过了,结果错误的走向了[IX_SalesOrderDetail_ProductID]这个索引;
一般函数在’=’’<’’>’左侧不会走索引! 这个要修改语句逻辑了!
SCAN未必是很差的选择:
PKID 列上有个非聚集索引;
pkid=100093 有2万行数据;
pkid=10094 大概有10条结果;
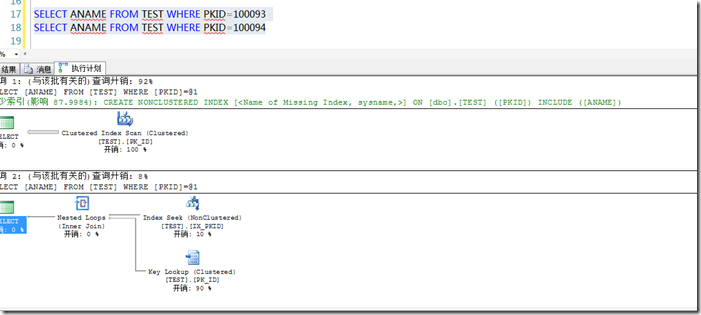
下图得到结果是pkid=100093走了聚集索引扫描,优化器认为这样比通过索引叶查询+聚集rid look 要快;
我们可以尝试下 很简单的测试:
SELECT ANAME FROM TEST with(index=ix_pkid) WHERE PKID=100093
SELECT ANAME FROM TEST WHERE PKID=100093

很显然 全表扫描要快;
我再补上IO次数;

差距是不是很明显,索引优化器还是比较很聪明;
还一点 我也顺便测试了
我把这个语句打包成存储过程,直接缓存到缓存中;我们看下效果:
CREATE PROC SCAN (@I INT)
AS
SELECT ANAME FROM TEST WHERE PKID=@I
DBCC FREEPROCCACHE
我们先执行这个数量少的给优化器看,骗她存入缓存计划;
exec scan 100094

当我们执行这个一般大概2次,sqlserer就会存入缓存当中;
开始测试第二个:
exec scan 100093


你看很好骗吧,太坑了!!!
我们重新编译下:
sp_recompile 'scan'
exec scan 100093
哪天优化器能识别优化这个就更厉害了!!

当然我们也有解决办法:
添加包含索引如下:
USE [AdventureWorks2014]
GO
CREATE NONCLUSTERED INDEX IDX_PKIDANAME ON [dbo].[TEST] ([PKID])
INCLUDE ([ANAME])
GO
这样结果就全是seek 了;具体问题具体分析了!
一般filter记录越早越好,对筛选条件SARG(SearchArgument)条件写法注意点:
走索引的SARG:
“列运算符<常量或变量>”
“<常量或变量>列运算符”
“=”
“<”
“>“
“>=”
“<=“
“IN”
”BETWEEN“
“LIKE ‘ABC%’”
”AND“
'50000'="SALESORDERID"
不走索引SARG:
NOT
<>
NOT EXISTS
NOT IN
NOT LIKE
CONVERT,UPPER
SQLServer 索引总结的更多相关文章
- SQLServer索引
SQLServer索引1.聚集和非聚集索引聚集索引:根据聚集索引进行排序,非聚集索引因为不根据索引键排序,所以聚集索引比非聚集索引快(一个表只有一个聚集索引)2.唯一索引和非唯一索引唯一索引时值不能重 ...
- mssql sqlserver 索引专题
摘要: 下文将详细讲述sql server 索引的相关知识,如下所示: 实验环境: sql server 2008 R2 sqlserver索引简介: mssql sqlsever 索引分类简介 ms ...
- sqlserver 索引的结构及其存储,索引内容
sqlserver 索引的结构及其存储,sql server索引内容 文章转载,原文地址: http://www.cnblogs.com/panchunting/p/SQLServer_IndexSt ...
- sqlserver 索引优化 CPU占用过高 执行分析 服务器检查
原文:sqlserver 索引优化 CPU占用过高 执行分析 服务器检查 1. 管理公司一台服务器,上面放的东西挺多的.有一天有个哥们告诉我现在程序卡的厉害.我给他说,是时候读点优化的书了.别一天到晚 ...
- 技术分享会(二):SQLSERVER索引介绍
SQLSERVER索引介绍 一.SQLSERVER索引类型? 1.聚集索引: 2.非聚集索引: 3.包含索引: 4.列存储索引: 5.无索引(堆表): 二.如何创建索引? 索引示例: 建表 creat ...
- sqlserver索引维护(重新组织生成索引)
sqlserver索引的维护 1:查看索引碎片大于百分三十以上的索引 select object_id= object_id,indexid = index_id,partitionnum = par ...
- SqlServer索引的原理与应用(转载)
SqlServer索引的原理与应用 索引的概念 索引的用途:我们对数据查询及处理速度已成为衡量应用系统成败的标准,而采用索引来加快数据处理速度通常是最普遍采用的优化方法. 索引是什么:数据库中的索引类 ...
- SQLServer索引的四个高级特性
一Index Building Filter索引创建时过滤 二Index Include Column索引包含列 三聚集索引Cluster Index 四VIEW INDEX视图索引 SQLSer ...
- SqlServer索引的原理与应用
索引的概念 索引的用途:我们对数据查询及处理速度已成为衡量应用系统成败的标准,而采用索引来加快数据处理速度通常是最普遍采用的优化方法. 索引是什么:数据库中的索引类似于一本书的目录,在一本书中使用目录 ...
- sqlserver索引小结
1.1 什么是索引? SQL索引有两种,聚集索引和非聚集索引,索引主要目的是提高了SQL Server系统的性能,加快数据的查询速度与减少系统的响应时间 下面举两个简单的例子: 图书馆的例子:一个图书 ...
随机推荐
- PHP开发b2c商城价格
电商的快速发展不断地挤压传统企业的生存空间,渠道越来越窄,所以现在很多企业开始往线上发展,搭建自己的B2C商城,直接面向消费者进行销售.那开发b2c商城价格怎么样?很多企业都是比较关心到商城价格这个问 ...
- PDFBox创建并打印PDF文件, 以及缩放问题的处理.
PDFBox带了一些很方便的API, 可以直接创建 读取 编辑 打印PDF文件. 创建PDF文件 public static byte[] createHelloPDF() { ByteArrayOu ...
- 将STM32 iap hex文件与app hex文件合并为一个hex文件
日前公司产品需要增加远程升级功能,boot loader程序写好后交予生产部门使用时他们反馈每个产品程序需要刷写两次(一个boot loader 一个app程序),生产进度变慢浪费时间,于是乎研究如何 ...
- hdu 1233 还是畅通project(kruskal求最小生成树)
还是畅通project Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Tota ...
- Android ImageLoader(Android-Universal-Image-Loader)【1】概述及使用简单介绍
Android ImageLoader(Android-Universal-Image-Loader)[1]概述及使用简单介绍 一,前言:为什么要引入Android-Universal-Imag ...
- JAVA入门[15]-过滤器filter
一.过滤器 过滤器是可用于 Servlet 编程的 Java 类,可以实现以下目的: 在客户端的请求访问后端资源之前,拦截这些请求. 在服务器的响应发送回客户端之前,处理这些响应. 参考:http:/ ...
- ASP.NET Core 异常重试组件 Polly
Polly 是一种 .NET 弹性和瞬态故障处理库,允许开发人员以流畅和线程安全的方式表达策略,如重试,断路器,超时,隔离隔离和备用,Polly 适用于 .NET 4.0,.NET 4.5 和 .NE ...
- 七、Spring Boot Servlet 使用
Web开发使用 Controller 基本上可以完成大部分需求,但是我们还可能会用到 Servlet.Filter.Listener.Interceptor 等等. 当使用spring-Boot时,嵌 ...
- JSON Schema 校验实例
JSON Schema 简介 JSON Schema is a vocabulary that allows you to annotate and validate JSON documents. ...
- 安装eclipse时跳转到网页提示JRE Missing
可能的原因:jdk与安装的eclipse不兼容,可能64位机器安装了32位的jdk,导致64位的eclipse不能识别.