照虎画猫写自己的Spring
从细节跳出来
看了部分Spring的代码,前面用了四篇内容写了一些读书笔记。
回想起来,论复杂度,Spring够喝上好几壶的。他就像一颗枝繁叶茂的大树,远处看,只是一片绿;走近看,他为你撑起一片小天地,为你遮风避雨;往深了看,他盘根错节,根基夯实。
在看Spring代码的过程中,我几度有些迷糊,因为一行简单的函数调用,你要是一直跟踪下去,从一个函数跳到另一个函数,又从一个类进入到另一个接口或者代理类,可能原本你只想知道函数做了什么,等回过头来,你发现已经找不到回去的路……
所以,每写一篇的时候,我都用一两句话总结该篇主要讲的是Spring干了什么事,实现了什么功能。
这些,我觉得还不够。所以,今天我照虎画猫,写了一个自己的Spring——Fairy项目。
Fairy项目
取名Fairy,意为小精灵,象征着东西不大,但是能量无穷,稍有契合Spring春天生机盎然之意。
大体思路
Spring经过这么多年的发展和补充,已经变成庞然大物,代码中包含了很多可扩展性和抽象的代码和设计。如果想一把抓尽收眼底,还是比较难消化的。这里,就设计一个简洁版的Spring,也算是抽丝剥茧,看看Spring最开始是给我们解决了一个什么问题,大体思路如下:
- 声明配置文件,用于声明需要加载使用的类
- 加载配置文件,读取配置文件
- 解析配置文件,需要将配置文件中声明的标签转换为Fairy能够识别的类
- 初始化类,提供配置文件中声明的类的实例
项目结构如下:
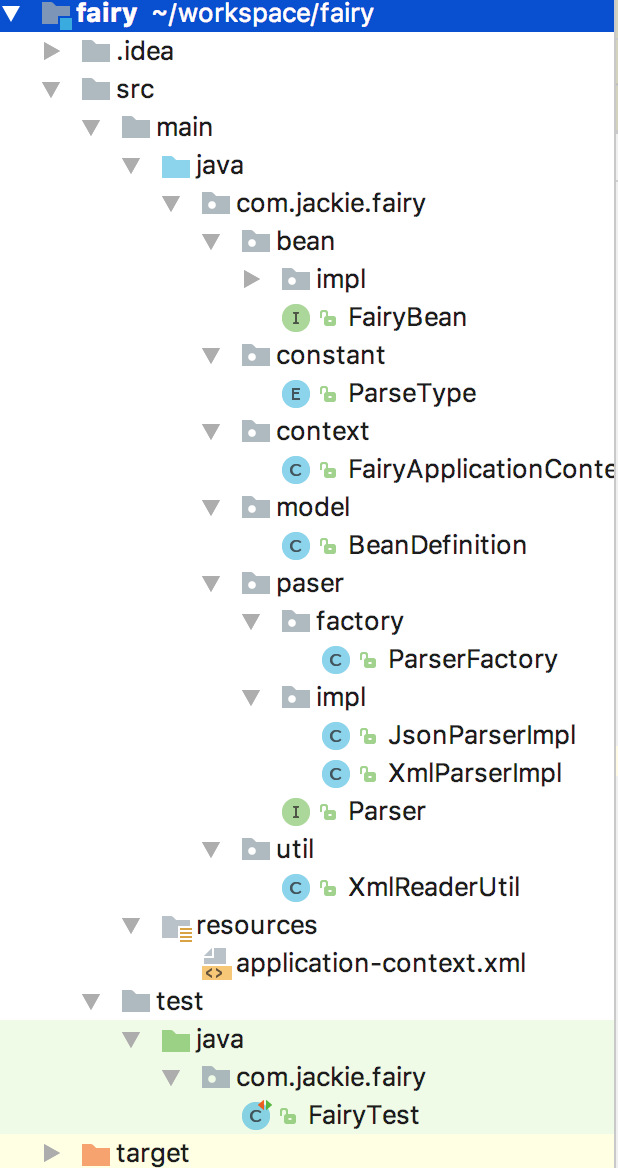
声明配置文件
首先你需要声明一个配置文件,这是一切工作的开始(当然了,更首先是要有一个项目,后面会给出在GitHub上的项目地址)。所有你想要用到的类,都应该声明在这里。
配置文件的好处就是可扩展性强,耦合度低。当需要声明一个bean的时候,我们只需要打开配置文件,在其中加上一个标签,填充你需要使用的那个类即可,剩下的工作就交个容器。
这里的配置文件application-context.xml很简单
<beans>
<bean id="fairyBean" class="com.jackie.fairy.bean.impl.FairyBeanImpl">
</bean>
</beans>
看完配置,我们大概就知道这是一次想得到FairyBeanImpl这个类的实例的征程。按照以往的套路,这些交给Spring去执行就好了,大可以通过这种xml配置的方式,甚至可以通过@Autowired注解的方式。
只是这里,我们不再引入Spring的任何依赖,我们要自己造轮子,完成这次bean的加载。这里的标签其实可以声明任何你想声明的标签名,因为已经跳出Spring的约束了,好比这样
<life>
<smile id="fairyBean" class="com.jackie.fairy.bean.impl.FairyBeanImpl">
</smile>
</life>
加载、解析配置文件
从上面的声明可以看出,我们还是使用了XML这种传统的配置文件的方式(后面还会尝试使用JSON的数据格式,详见项目中的JsonParserImpl)。
所以加载首先我们需要加载xml配置文件。其实这里加载xml文件和其他格式的文件并无二致,只是在解析的时候才有差别。
加载
URL xmlPath = XmlReaderUtil.class.getClassLoader().getResource(fileName);
这里只需要传入文件名,剩下的通过getResource得到文件的URL路径,后面的事情就交给xml解析器去做了。
解析
因为配置文件是xml格式,所以需要针对xml进行解析,这里用的是dom4j对xml进行解析。解析的本质就是层层剥开,抽取想要的信息。
我将解析的过程写在工具类中
public class XmlReaderUtil {
private static final Logger LOG = LoggerFactory.getLogger(XmlReaderUtil.class);
public static List<BeanDefinition> readXml(String fileName) {
List<BeanDefinition> beanDefinitions = Lists.newArrayList();
//创建一个读取器
SAXReader saxReader = new SAXReader();
Document document = null;
try {
//获取要读取的配置文件的路径
URL xmlPath = XmlReaderUtil.class.getClassLoader().getResource(fileName);
//读取文件内容
document = saxReader.read(xmlPath);
//获取xml中的根元素
Element rootElement = document.getRootElement();
for (Iterator iterator = rootElement.elementIterator(); iterator.hasNext(); ) {
Element element = (Element)iterator.next();
String id = element.attributeValue("id");
String clazz = element.attributeValue("class");
BeanDefinition beanDefinition = new BeanDefinition(id, clazz);
beanDefinitions.add(beanDefinition);
}
} catch (Exception e) {
LOG.error("read xml failed", e);
}
return beanDefinitions;
}
}
主要过程
- 新建一个解析器
- 加载xml配置文件
- 找到根元素
- 遍历各个元素
- 找到相应的属性
- 完成解析,将信息存储到集合中
初始化类
完成配置文件的解析后,就需要针对配置文件的信息进行实例化,方便调用者使用。
通过解析后,我们得到了一个List集合,存放了BeanDefinition,每一个BeanDefinition都存放这标签的属性值(这里仅支持id和class属性的解析和存储)。下面就需要针对List集合中解析后的标签进行实例化了。
private void instanceBeanDefinitions() {
if (CollectionUtils.isNotEmpty(beanDefinitions)) {
for (BeanDefinition beanDefinition : beanDefinitions) {
if (StringUtils.isNotEmpty(beanDefinition.getClassName())) {
try {
instanceBeans.put(beanDefinition.getId(),
Class.forName(beanDefinition.getClassName()).newInstance());
LOG.info("instance beans successfully, instanceBeans: {}", instanceBeans);
} catch (InstantiationException e) {
LOG.error("instantiation failed", e);
} catch (IllegalAccessException e) {
LOG.error("illegalAccessException", e);
} catch (ClassNotFoundException e) {
LOG.error("classNotFoundException", e);
}
}
}
}
}
主要是通过遍历解析得到的集合,分别对各个元素一一进行实例化,再存储到Map集合中,方便后面根据名称获取(这里还有一些异常情况的处理和参数校验就不做解释,可以直接看代码)。
测试
完成以上简单的几步之后,我们就可以测试成果了,新建测试类FairyTest
@Test
public void testLoadBean() {
FairyApplicationContext applicationContext = new FairyApplicationContext("application-context.xml", ParseType.XML_PARSER);
FairyBean fairyBean = (FairyBean) applicationContext.getBean("fairyBean");
fairyBean.greet();
}
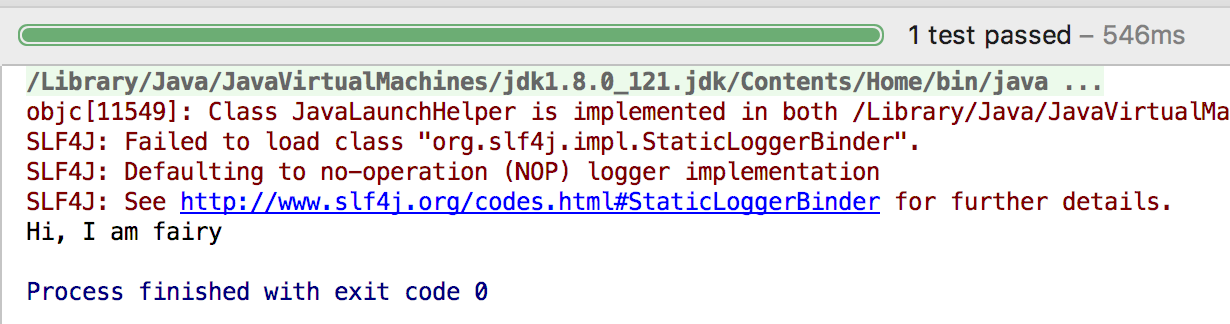
这样,我们就如愿的完成了FairyBean类的加载和实例化,我们没有用到Spring的任何依赖,自己写了个小容器完成了类加载。
项目地址:https://github.com/DMinerJackie/fairy
如果您觉得阅读本文对您有帮助,请点一下“推荐”按钮,您的“推荐”将是我最大的写作动力!如果您想持续关注我的文章,请扫描二维码,关注JackieZheng的微信公众号,我会将我的文章推送给您,并和您一起分享我日常阅读过的优质文章。

照虎画猫写自己的Spring的更多相关文章
- 照虎画猫写自己的Spring——依赖注入
前言 上篇<照虎画猫写自己的Spring>从无到有讲述并实现了下面几点 声明配置文件,用于声明需要加载使用的类 加载配置文件,读取配置文件 解析配置文件,需要将配置文件中声明的标签转换为F ...
- 照虎画猫写自己的Spring——自定义注解
Fairy已经实现的功能 读取XML格式配置文件,解析得到Bean 读取JSON格式配置文件,解析得到Bean 基于XML配置的依赖注入 所以,理所当然,今天该实现基于注解的依赖注入了. 基于XML配 ...
- 利用反射手写代码实现spring AOP
前言:上一篇博客自己动手编写spring IOC源码受到了大家的热情关注,在这里博客十分感谢.特别是给博主留言建议的@玛丽的竹子等等.本篇博客我们继续,还是在原有的基础上进行改造.下面请先欣赏一下博主 ...
- Spring学习之——手写Mini版Spring源码
前言 Sping的生态圈已经非常大了,很多时候对Spring的理解都是在会用的阶段,想要理解其设计思想却无从下手.前些天看了某某学院的关于Spring学习的相关视频,有几篇讲到手写Spring源码,感 ...
- 3.1 spring5源码系列--循环依赖 之 手写代码模拟spring循环依赖
本次博客的目标 1. 手写spring循环依赖的整个过程 2. spring怎么解决循环依赖 3. 为什么要二级缓存和三级缓存 4. spring有没有解决构造函数的循环依赖 5. spring有没有 ...
- 手写Mybatis和Spring整合简单版示例窥探Spring的强大扩展能力
Spring 扩展点 **本人博客网站 **IT小神 www.itxiaoshen.com 官网地址****:https://spring.io/projects/spring-framework T ...
- 用Kotlin写一个基于Spring Boot的RESTful服务
Spring太复杂了,配置这个东西简直就是浪费生命.尤其在没有什么并发压力,随便搞一个RESTful服务 让整个业务跑起来先的情况下,更是么有必要纠结在一堆的XML配置上.显然这么想的人是很多的,于是 ...
- 手把手写一个基于Spring Boot框架下的参数校验组件(JSR-303)
前言 之前参与的新开放平台研发的过程中,由于不同的接口需要对不同的入参进行校验,这就涉及到通用参数的校验封装,如果不进行封装,那么写出来的校验代码将会风格不统一.校验工具类不一致.维护风险高等其它因素 ...
- 如何写好一个 Spring 组件
背景 Spring 框架提供了许多接口,可以使用这些接口来定制化 bean ,而非简单的 getter/setter 或者构造器注入.细翻 Spring Cloud Netflix.Spring Cl ...
随机推荐
- #云栖大会# 移动安全专场——APP加固新方向(演讲速记)
主持人导语: 近些年来,移动APP数量呈现爆炸式的增长,黑产也从原来的PC端转移到了移动端,伴随而来的逆向攻击手段也越来越高明.在解决加固产品容易被脱壳的方案中,代码混淆技术是对抗逆向攻击最有效的方式 ...
- NPOI导出excel(带图片)
近期项目中用到Excel导出功能,之前都是用普通的office组件导出的方法,今天尝试用下NPOI,故作此文以备日后查阅. 1.NPOI官网http://npoi.codeplex.com/,下载最新 ...
- 阿里巴巴 Java 开发规约插件初体验
阿里巴巴 Java 开发手册 又一次来谈<阿里巴巴 Java 开发手册>,经过这大半年的版本迭代,这本阿里工程师们总结出来避免写出那么多 Bug 的规范,对于 Java 开发者简直就是必备 ...
- Appium python自动化测试系列之appium环境搭建(二)
2.1 基础环境搭建 当我们学习新的一项技术开始基本都是从环境搭建开始,本书除了第一章节也是的,如果你连最基础的环境都没有那么我们也没必要去说太多,大概介绍一下: 1.因为appium是支持andr ...
- Android 性能优化概念(1)
http://www.open-open.com/lib/view/open1421723359718.html#_label0 阅读目录 0)Render Performance 1)Underst ...
- mybatis的搭建和注入spring的方式
mybatis实际上是一个更多关注sql语句的框架,他的出现是想让开发者更简单的去操作数据库. 与hibernate相比较,hibernate更多的是去sql化,虽然hibernate也可以本地sql ...
- 张高兴的 Xamarin.Android 学习笔记:(四)常用控件
示例地址 GitHub : https://github.com/ZhangGaoxing/xamarin-android-demo/tree/master/ControlsDemo
- Iozone
参考地址:iozone使用技巧.iozone和Fio安装测试说明 iozone介绍 iozone(www.iozone.org)是一个文件系统的benchmark工具,可以测试不同的操作系统中文件系统 ...
- jsp页面接收json字符串
jsp页面接收 后台添加
- LeetCode 228. Summary Ranges (总结区间)
Given a sorted integer array without duplicates, return the summary of its ranges. Example 1: Input: ...