scrapy框架第一章
操作环境:python2.7+scrapy

安装比较简单,网上教程也超多,就不在此赘述。
示例网站:https://www.cnblogs.com/cate/python/ (爬去关于博客园所有python的帖子)
#############开始新建项目 E:work\scrapy_pro\
打开cmd(命令行窗口)
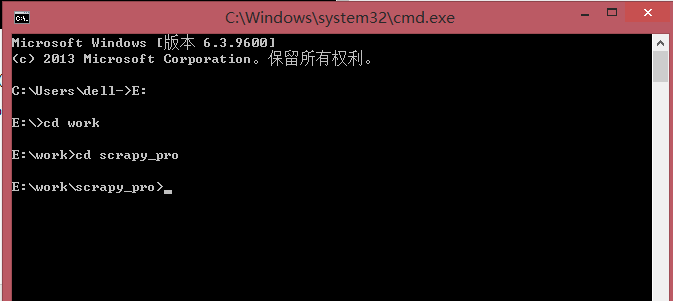
cd 进入文件夹 cd..回到上一级 进入某个盘符直接输入E: 大小写没关系
############执行新建项目命令 项目名 cnblog
scrapy startproject cnblog
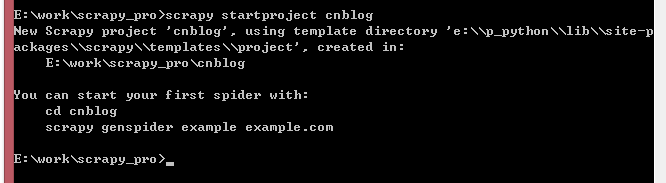
创建ok,进入项目cd cnblog ,操作该项目时在这一层目录。
目录如下
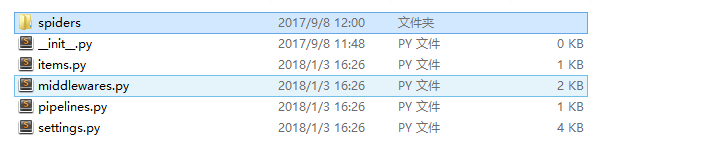
dir-spiders:存放所有spider的文件,里面的spider文件自己新建。
items.py:用来存放爬去的内容,在导出数据时需要用到
middlewares.py:中间件文件,写入多余的功能,比如需要与PhantomJs结合使用时修改这里。
pipelines.py:暂时没用过。
settings.py:项目配置文件。
######打开spiders文件夹开始新建spider文件 test.py 名字无所谓
打开test.py
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
###引入的是items.py里面构造的类
from cnblog.items import ExampleItem class TestSpider(CrawlSpider):
name = 'blog'
allowed_domains = ['cnblogs.com']
start_urls = ['https://www.cnblogs.com/cate/python/'] rules = (
###爬去索引页并跟踪其中链接
###查找start_urls 所有的分页页面
Rule(LinkExtractor(allow=r'/cate/python/[2-9]*'), follow=True),
###爬去items页面并将下载响应返回个头parse_item函数
####查询每个分页页面的详情页
Rule(LinkExtractor(allow=r'http://www.cnblogs.com/[a-z]*/p/[0-1]*'), callback='parse_item', follow=False
),
) def parse_item(self, response):
item = ExampleItem()
#i['domain_id'] = response.xpath('//input[@id="sid"]/@value').extract()
#i['name'] = response.xpath('//div[@id="name"]').extract()
#i['description'] = response.xpath('//div[@id="description"]').extract()
#print response.xpath('//a[@id="Header1_HeaderTitle"]/text()').extract()
if response.xpath('//a[@id="Header1_HeaderTitle"]/text()').extract():
item['blog_name'] = response.xpath('//a[@id="Header1_HeaderTitle"]/text()').extract()
else:
item['blog_name'] = 'null'
items = []
items.append(item)
return items
items.py
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html import scrapy class ExampleItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
blog_name = scrapy.Field()
上面是两个需要用到的两个文件
前面的是spider文件,另一个是定义存储的内容文件
items.py
blog_name = scrapy.Field() //定义一个获取的字段,获取详情页的标题
test.py
from scrapy.linkextractors import LinkExtractor ##引入linkextractors 用于筛选链接和跟进链接,还有很多功能,可以去百度下
from scrapy.spiders import CrawlSpider, Rule ##定义spider的模板,引入Rule规则
from example.items import ExampleItem ##引入定义的items.py
下面是对类的详细介绍
class TestSpider(CrawlSpider): ##继承模板CrawlSpider 普通模板继承Spider
name = 'blog' ###定义spider名 运行---$ scrapy crawl blog
allowed_domains = ['cnblogs.com'] ## 定义查找范围
start_urls = ['https://www.cnblogs.com/cate/python/'] ###初始url
###通过rules限定查找的url
###分页的url ='/cate/python/[2-9]*'
###详情页的url = 'http://www.cnblogs.com/[a-z]*/p/[0-1]*'
####当有follow=True 则会跟进该页面
####原理就是 spider在初始页面查找,同时查找帖子详情页的url和下一个分页,同时跟进下一个分页页面,继续查找下一个分页页面和上面的详情页url,详情页面使用回调函数进行采集
rules = (
###爬去索引页并跟踪其中链接
###查找start_urls 所有的分页页面
Rule(LinkExtractor(allow=r'/cate/python/[2-9]*'), follow=True),
###爬去items页面并将下载响应返回个头parse_item函数
####查询每个分页页面的详情页
Rule(LinkExtractor(allow=r'http://www.cnblogs.com/[a-z]*/p/[0-1]*'), callback='parse_item', follow=False
),
)
####详情页面回调函数
def parse_item(self, response):
###实例化item类
item = ExampleItem()
###几种xpath获取标签的方式
#i['domain_id'] = response.xpath('//input[@id="sid"]/@value').extract()
#i['name'] = response.xpath('//div[@id="name"]').extract()
#i['description'] = response.xpath('//div[@id="description"]').extract()
#print response.xpath('//a[@id="Header1_HeaderTitle"]/text()').extract()
if response.xpath('//a[@id="Header1_HeaderTitle"]/text()').extract():
item['blog_name'] = response.xpath('//a[@id="Header1_HeaderTitle"]/text()').extract()
else:
item['blog_name'] = 'null'
items = []
###把数据装进仓库
items.append(item)
return items
#####现在开始执行spider
切换到当前目录

—————————导出json文件

scrapy框架第一章的更多相关文章
- Nova PhoneGap框架 第一章 前言
Nova PhoneGap Framework诞生于2012年11月,从第一个版本的发布到现在,这个框架经历了多个项目的考验.一直以来我们也持续更新这个框架,使其不断完善.到现在,这个框架已比较稳定了 ...
- Scrapy框架: 第一个程序
首先创建项目: scrappy start project maitian 第二步: 明确要抓取的字段items.py import scrapy class MaitianItem(scrapy.I ...
- 自定义MVC框架---第一章
MVC基本介绍 介绍: mvc是一种编程思想,用来解决开发项目的时候,代码如何编写,项目如何架构的问题,更具体一点就是解决多人协同开发时,如何分工协作的问题,从而提升开发效率 举一个例子:有一个人想 ...
- 路飞学城-Python爬虫集训-第一章
自学Python的时候看了不少老男孩的视频,一直欠老男孩一个会员,现在99元爬虫集训果断参与. 非常喜欢Alex和武Sir的课,技术能力超强,当然讲着讲着就开起车来也说明他俩开车的技术也超级强! 以上 ...
- Learning Scrapy 中文版翻译 第一章
第一章:scrapy介绍 欢迎来到scrapy之旅.通过这本书,我们将帮助你从只会一点或者零基础的Scrapy初学者达到熟练使用这个强大的框架在互联网或者其他资源抓取海量的数据.在这一章节,我们将给你 ...
- 《Entity Framework 6 Recipes》翻译系列 (1) -----第一章 开始使用实体框架之历史和框架简述
微软的Entity Framework 受到越来越多人的关注和使用,Entity Framework7.0版本也即将发行.虽然已经开源,可遗憾的是,国内没有关于它的书籍,更不用说好书了,可能是因为EF ...
- 《Entity Framework 6 Recipes》翻译系列(2) -----第一章 开始使用实体框架之使用介绍
Visual Studio 我们在Windows平台上开发应用程序使用的工具主要是Visual Studio.这个集成开发环境已经演化了很多年,从一个简单的C++编辑器和编译器到一个高度集成.支持软件 ...
- 第一章 自定义MVC框架
第一章 自定义MVC框架1.1 MVC模式设计 组成:Model:模型,用于数据和业务的处理 View :视图,用于数据的显示 Controller:控制器 ...
- jQuery系列 第一章 jQuery框架简单介绍
第一章 jQuery框架简单介绍 1.1 jQuery简介 jQuery是一款优秀的javaScript库(框架),该框架凭借简洁的语法和跨平台的兼容性,极大的简化了开发人员对HTML文档,DOM,事 ...
随机推荐
- 深入了解Android蓝牙Bluetooth——《进阶篇》
在 [深入了解Android蓝牙Bluetooth--<基础篇>](http://blog.csdn.net/androidstarjack/article/details/6046846 ...
- Bootstrap-datepicker3官方文档中文翻译---概述(原版翻译 http://bootstrap-datepicker.readthedocs.io/en/latest/index.html)
bootstrap-datepicker Bootstrap-datepicker 提供了一个拥有Bootstrap样式的弹性Datepicker控件 Requirements/使用要求 Bootst ...
- QTP日期格式化
'以下函数将日期参数进行格式转化,例如:2017-01-02 Function ShortDateToLongDate(strChangeDate) b=split(strChangeDate, ...
- PostgreSQL索引描述
索引方式:唯一索引,主键索引,多属性索引,部分索引,表达式索引. 索引类型:B-Tree,Hash,GiST,GIN以及表达式索引 PostgreSQL所有索引都是“从属索引”,也就是说,索引在物理上 ...
- [置顶]
Java WebService接口生成和调用 图文详解
webservice简介: Web Service技术, 能使得运行在不同机器上的不同应用无须借助附加的.专门的第三方软件或硬件, 就可相互交换数据或集成.依据Web Service规范实施的应用之间 ...
- java设计模式—多工厂模式
概念 多个工厂模式,是对普通工厂方法的改进,在普通工厂模式中,如果字符串传递出错,则不能正 确创建对象,而多个工厂模式是提供多个工厂方法,分别创建对象. 多个工厂模式关 ...
- 基于python2.7通过boto3实现ec2表格化
#!/usr/bin/env python import xlwt,xlrd,datetime,json,os,xlutils.copy a={ 'VpcPeeringConnection': { ' ...
- 《Qt on Android核心编程》介绍
<Qt on Android核心编程>最终尘埃落定.付梓印刷了. 2014-11-02更新:china-pub的预售链接出来了.折扣非常低哦. 封面 看看封面的效果吧,历经几版,最终就成了 ...
- CSS clear 清除浮动,兼容各浏览器
.clear:after{content:".";display:block;height:0;clear:both;visibility:hidden;} .clear{zoom ...
- 数据库中的參照完整性(Foreign Key)
之前在项目中遇到了这样一个问题,我举得简单的样例来说明. 比方我们有两个表,一个表(department)存放的是部门的信息,比如部门id,部门名称等:还有一个表是员工表(staff),员工表里面肯定 ...