数据结构中常见的树(BST二叉搜索树、AVL平衡二叉树、RBT红黑树、B-树、B+树、B*树)
树
即二叉搜索树:
1.所有非叶子结点至多拥有两个儿子(Left和Right);
2.所有结点存储一个关键字;
非叶子结点的左指针指向小于其关键字的子树,右指针指向大于其关键字的子树;
如:
BST树的搜索,从根结点开始,如果查询的关键字与结点的关键字相等,那么就命中;
如果BST树的所有非叶子结点的左右子树的结点数目均保持差不多(平衡),那么B树
的搜索性能逼近二分查找;但它比连续内存空间的二分查找的优点是,改变BST树结构
插入与删除结点)不需要移动大段的内存数据,甚至通常是常数开销;
如:
但BST树在经过多次插入与删除后,有可能导致不同的结构:
树,但它的搜索性能已经是线性的了;同样的关键字集合有可能导致不同的
树结构索引;所以,使用BST树还要考虑尽可能让BST树保持左图的结构,和避免右图的结构,也就
是所谓的“平衡”问题;
AVL平衡二叉搜索树
定义:平衡二叉树或为空树,或为如下性质的二叉排序树:
(1)左右子树深度之差的绝对值不超过1;
(2)左右子树仍然为平衡二叉树.
平衡因子BF=左子树深度-右子树深度.
平衡二叉树每个结点的平衡因子只能是1,0,-1。若其绝对值超过1,则该二叉排序树就是不平衡的。
如图所示为平衡树和非平衡树示意图:

RBT 红黑树
AVL是严格平衡树,因此在增加或者删除节点的时候,根据不同情况,旋转的次数比红黑树要多;
红黑是弱平衡的,用非严格的平衡来换取增删节点时候旋转次数的降低;
所以简单说,搜索的次数远远大于插入和删除,那么选择AVL树,如果搜索,插入删除次数几乎差不多,应该选择RB树。
红黑树上每个结点内含五个域,color,key,left,right,p。如果相应的指针域没有,则设为NIL。
一般的,红黑树,满足以下性质,即只有满足以下全部性质的树,我们才称之为红黑树:
1)每个结点要么是红的,要么是黑的。
2)根结点是黑的。
3)每个叶结点,即空结点(NIL)是黑的。
4)如果一个结点是红的,那么它的俩个儿子都是黑的。
5)对每个结点,从该结点到其子孙结点的所有路径上包含相同数目的黑结点。
下图所示,即是一颗红黑树:
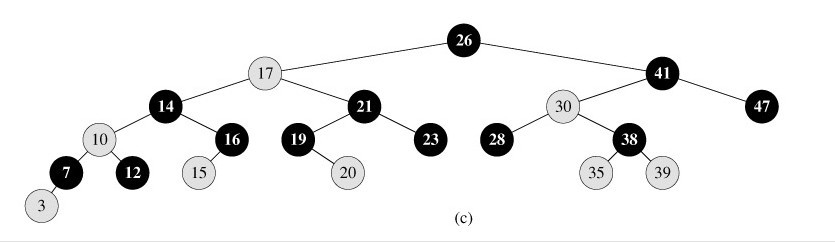
B-树
是一种平衡多路搜索树(并不是二叉的):
1.定义任意非叶子结点最多只有M个儿子;且M>2;
2.根结点的儿子数为[2, M];
3.除根结点以外的非叶子结点的儿子数为[M/2, M];
4.每个结点存放至少M/2-1(取上整)和至多M-1个关键字;(至少2个关键字)
5.非叶子结点的关键字个数=指向儿子的指针个数-1;
6.非叶子结点的关键字:K[1], K[2], …, K[M-1];且K[i]
< K[i+1];
7.非叶子结点的指针:P[1], P[2], …, P[M];其中P[1]指向关键字小于K[1]的
子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1],
K[i])的子树;
8.所有叶子结点位于同一层;
如:(M=3)

B-树的搜索,从根结点开始,对结点内的关键字(有序)序列进行二分查找,如果
命中则结束,否则进入查询关键字所属范围的儿子结点;重复,直到所对应的儿子指针为
空,或已经是叶子结点;
B-树的特性:
1.关键字集合分布在整颗树中;
2.任何一个关键字出现且只出现在一个结点中;
3.搜索有可能在非叶子结点结束;
4.其搜索性能等价于在关键字全集内做一次二分查找;
5.自动层次控制;
由于限制了除根结点以外的非叶子结点,至少含有M/2个儿子,确保了结点的至少
利用率,其最底搜索性能为:

其中,M为设定的非叶子结点最多子树个数,N为关键字总数;
所以B-树的性能总是等价于二分查找(与M值无关),也就没有B树平衡的问题;
由于M/2的限制,在插入结点时,如果结点已满,需要将结点分裂为两个各占
M/2的结点;删除结点时,需将两个不足M/2的兄弟结点合并;
B+树
B+树是B-树的变体,也是一种多路搜索树:
1.其定义基本与B-树同,除了:
2.非叶子结点的子树指针与关键字个数相同;
3.非叶子结点的子树指针P[i],指向关键字值属于[K[i],
K[i+1])的子树
(B-树是开区间);
5.为所有叶子结点增加一个链指针;
6.所有关键字都在叶子结点出现;
如:(M=3)

B+的搜索与B-树也基本相同,区别是B+树只有达到叶子结点才命中(B-树可以在
非叶子结点命中),其性能也等价于在关键字全集做一次二分查找;
B+的特性:
1.所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好
是有序的;
2.不可能在非叶子结点命中;
3.非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储
(关键字)数据的数据层;
4.更
适合文件索引系统;比如对已经建立索引的数据库记录,查找10<=id<=20,那么只要通过根节点搜索到id=10的叶节点,之后只要根据
叶节点的链表找到第一个大于20的就行了,比B-树在查找10到20内的每一个时每次都从根节点出发查找提高了不少效率。
B*树
是B+树的变体,在B+树的非根和非叶子结点再增加指向兄弟的指针;

B*树定义了非叶子结点关键字个数至少为(2/3)*M,即块的最低使用率为2/3
(代替B+树的1/2);
B+树的分裂:当一个结点满时,分配一个新的结点,并将原结点中1/2的数据
复制到新结点,最后在父结点中增加新结点的指针;B+树的分裂只影响原结点和父
结点,而不会影响兄弟结点,所以它不需要指向兄弟的指针;
B*树的分裂:当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分
数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字
(因为兄弟结点的关键字范围改变了);如果兄弟也满了,则在原结点与兄弟结点之
间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针;
所以,B*树分配新结点的概率比B+树要低,空间使用率更高;
小结
B树:二叉树,每个结点只存储一个关键字,等于则命中,小于走左结点,大于
走右结点;
B-树:多路搜索树,每个结点存储M/2到M个关键字,非叶子结点存储指向关键
字范围的子结点;
所有关键字在整颗树中出现,且只出现一次,非叶子结点可以命中;
B+树:在B-树基础上,为叶子结点增加链表指针,所有关键字都在叶子结点
中出现,非叶子结点作为叶子结点的索引;B+树总是到叶子结点才命中;
B*树:在B+树基础上,为非叶子结点也增加链表指针,将结点的最低利用率
从1/2提高到2/3;
B+/B*Tree应用
数据库索引--索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。
数据库索引--表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键。
倒排索引--也可以由B树及其变种实现但不一定非要B树及其变种实现,如lucene没有使用B树结构,因此lucene可以用二分搜索算法快速定位关键词。实现时,lucene将下面三列分别作为词典文件(Term
Dictionary)、频率文件(frequencies)、位置文件 (positions)保存。其中词典文件不仅保存有每个关键词,还保留了指向频率文件和位置文件的指针,通过指针可以找到该关键字的频率信息和位置信息。
数据结构中常见的树(BST二叉搜索树、AVL平衡二叉树、RBT红黑树、B-树、B+树、B*树)的更多相关文章
- 二叉搜索树、平衡二叉树、红黑树、B树、B+树
完全二叉树: 空树不是完全二叉树,叶子结点只能出现在最下层和次下层,且最下层的叶子结点集中在树的左部.如果遇到一个结点,左孩子不为空,右孩子为空:或者左右孩子都为空:则该节点之后的队列中的结点都为叶子 ...
- B-Tree 漫谈 (从二叉树到二叉搜索树到平衡树到红黑树到B树到B+树到B*树)
关于B树的学习还是需要做点笔记. B树是为磁盘或者其他直接存取辅助存储设备而设计的一种平衡查找树.B树与红黑树的不同在于,B树可以有很多子女,从几个到几千个.比如一个分支因子为1001,高度为2的B树 ...
- 数据结构中很常见的各种树(BST二叉搜索树、AVL平衡二叉树、RBT红黑树、B-树、B+树、B*树)
数据结构中常见的树(BST二叉搜索树.AVL平衡二叉树.RBT红黑树.B-树.B+树.B*树) 二叉排序树.平衡树.红黑树 红黑树----第四篇:一步一图一代码,一定要让你真正彻底明白红黑树 --- ...
- 树-二叉搜索树-AVL树
树-二叉搜索树-AVL树 树 树的基本概念 节点的度:节点的儿子数 树的度:Max{节点的度} 节点的高度:节点到各叶节点的最大路径长度 树的高度:根节点的高度 节点的深度(层数):根节点到该节点的路 ...
- 浅析BST二叉搜索树
2020-3-25 update: 原洛谷日报#2中代码部分出现一些问题,详情见此帖.并略微修改本文一些描述,使得语言更加自然. 2020-4-9 update:修了一些代码的锅,并且将文章同步发表于 ...
- 树&二叉树&二叉搜索树
树&二叉树 树是由节点和边构成,储存元素的集合.节点分根节点.父节点和子节点的概念. 二叉树binary tree,则加了"二叉"(binary),意思是在树中作区分.每个 ...
- bst 二叉搜索树简单实现
//数组实现二叉树: // 1.下标为零的元素为根节点,没有父节点 // 2.节点i的左儿子是2*i+1:右儿子2*i+2:父节点(i-1)/2: // 3.下标i为奇数则该节点有有兄弟,否则又左兄弟 ...
- 二叉树、二叉搜索树、平衡二叉树、B树、B+树的精确定义和区别探究
概述 关于树的概念很多,B树,B+树,红黑树等等. 但是你去翻翻百度百科,或者用百度或者谷歌搜索一下中文的树结构的介绍,全都是狗屁.没有哪个中文网站是真正精确解释树的定义的,尤其是百度百科. 下面我要 ...
- 【数据结构与算法Python版学习笔记】树——平衡二叉搜索树(AVL树)
定义 能够在key插入时一直保持平衡的二叉查找树: AVL树 利用AVL树实现ADT Map, 基本上与BST的实现相同,不同之处仅在于二叉树的生成与维护过程 平衡因子 AVL树的实现中, 需要对每个 ...
随机推荐
- Tomcat学习笔记(一)一个简单的Web服务器
内容为<深入剖析Tomcat>第一章重点,以及自己的总结,如有描述不清的,可查看原书. 一.HTTP协议: 1.定义:用于服务器与客户端的通讯的协议,允许web服务器和浏览器通过互联网进行 ...
- svo笔记
使用 要想在ros中有更多的debug信息,要在global.h中把ros log的级别设为debug,最简单的就是把SVO_DEBUG_STREAM(x)改成ROS_INFO_STREAM(x) # ...
- 历年NOIP中的搜索题
什么题目都不会做于是开始做搜索题. 然而我搜索题也不会做了. 铁定没戏的蒟蒻. 1.NOIP2004 虫食算 “对于给定的N进制加法算式,求出N个不同的字母分别代表的数字,使得该加法算式成立.输入数据 ...
- css 定位属性position的使用方法实例-----一个层叠窗口
运行结果: <!DOCTYPE html> <html> <head> <title>重叠样式窗口</title> <style ty ...
- 浅谈viewport
我们通常在写移动端页面时,往往都会在html页面中加入这样一段话 <meta name="viewport" content="width=device-width ...
- Java 基本语法----变量
变 量 变量的概念 内存中的一个存储区域该区域有自己的名称(变量名)和类型(数据类型)Java中每个变量必须先声明,后使用该区域的数据可以在同一类型范围内不断变化 定义变量的格式:数据类型 变量名 = ...
- java宠物练习
先定一个宠物的抽象类,把所有共有的属性方法放到次类中,用于子类去继承实现. package backing2; abstract public class pet { private String n ...
- Linux服务器学习(一)
一.首先连接服务器 下载一个windows下连接linux的ssh工具,我这里用的putty.一次填入HostName(主机名,可以是服务器域名也可以是对应的ip).Port(端口号默认为22).Co ...
- Missing number - 寻找缺失的那个数字
需求:给出一个int型数组,包含不重复的数字0, 1, 2, ..., n:找出缺失的数字: 如果输入是[0, 1, 2] 返回 3 输入数组 nums = [0, 1, 2, 4] :应该返回 3 ...
- JavaScript-DOM编程的一些常用属性
一.Document常见属性 document.title // 设置文档标题等价于HTML的title标签 document.bgColor // 设置页面背景色 document.fgColor ...