0基础搭建Hadoop大数据处理-初识
在互联网的世界中数据都是以TB、PB的数量级来增加的,特别是像BAT光每天的日志文件一个盘都不够,更何况是还要基于这些数据进行分析挖掘,更甚者还要实时进行数据分析,学习,如双十一淘宝的交易量的实时展示。

大数据什么叫大?4个特征:
体量化 Volume,就是量大。
多样化 Variety,可能是结构型的数据,也可能是非结构行的文本,图片,视频,语音,日志,邮件等
快速化 Velocity,产生快,处理也需要快。
价值密度低 Value,数据量大,但单个数据没什么意义,需要宏观的统计体现其隐藏的价值。
可以看出想只要一台强大的服务器来实时处理这种体量的数据那是不可能的,而且成本昂贵,代价相当大,普通的关系型数据库也随着数据量的增大其处理时间也随之增加,那客户是不可能忍受的,所以我们需要Hadoop来解决此问题。
优点:
Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序。它主要有以下几个优点:
高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖。
高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
低成本。与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低。
Hadoop得以在大数据处理应用中广泛应用得益于其自身在数据提取、变形和加载(ETL)方面上的天然优势。Hadoop的分布式架构,将大数据处理引擎尽可能的靠近存储,对例如像ETL这样的批处理操作相对合适,因为类似这样操作的批处理结果可以直接走向存储。Hadoop的MapReduce功能实现了将单个任务打碎,并将碎片任务(Map)发送到多个节点上,之后再以单个数据集的形式加载(Reduce)到数据仓库里。
Hadoop在各应用中是最底层,最基础的组件,所以其重要性不言而喻。
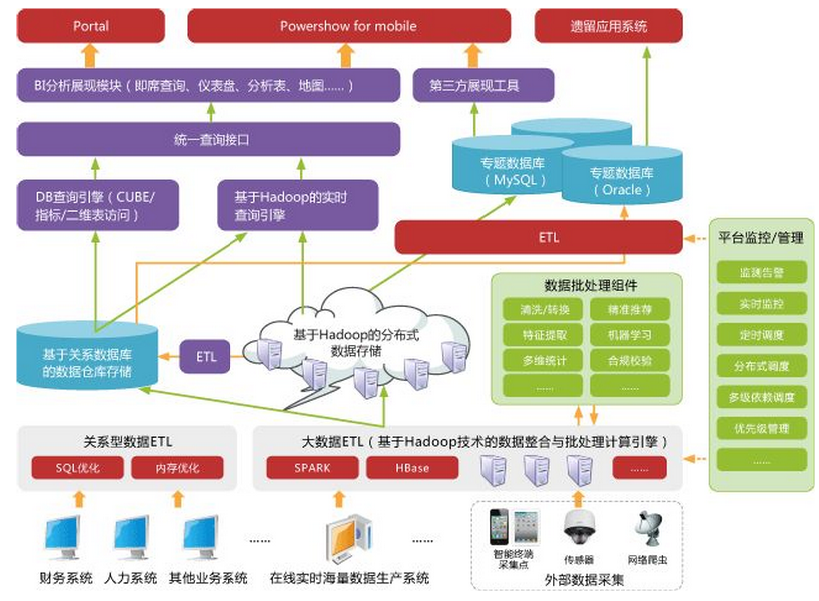
框架结构
Hadoop主要由HDFS ( 分布式文件系统)和MapReduce (并行计算框架)组成。
Hadoop 由许多元素构成。其最底部是 Hadoop Distributed File System(HDFS),它存储 Hadoop 集群中所有存储节点上的文件。HDFS(对于本文)的上一层是MapReduce 引擎,该引擎由 JobTrackers 和 TaskTrackers 组成。通过对Hadoop分布式计算平台最核心的分布式文件系统HDFS、MapReduce处理过程,以及数据仓库工具Hive和分布式数据库Hbase的介绍,基本涵盖了Hadoop分布式平台的所有技术核心。
HDFS
对外部客户机而言,HDFS就像一个传统的分级文件系统。可以创建、删除、移动或重命名文件,等等。但是 HDFS 的架构是基于一组特定的节点构建的,这是由它自身的特点决定的。这些节点包括 NameNode(仅一个),它在 HDFS 内部提供元数据服务;DataNode,它为 HDFS 提供存储块。由于仅存在一个 NameNode,因此这是 HDFS 的一个缺点(单点失败)。
存储在 HDFS 中的文件被分成块,然后将这些块复制到多个计算机中(DataNode)。这与传统的 RAID 架构大不相同。块的大小(通常为 64MB)和复制的块数量在创建文件时由客户机决定。NameNode 可以控制所有文件操作。HDFS 内部的所有通信都基于标准的 TCP/IP 协议。
单节点物理结构
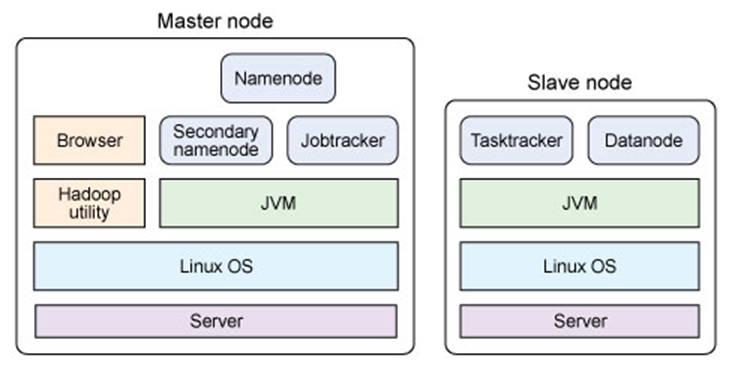
主从结构
主节点,只有一个: namenode
从节点,有很多个: datanodes
namenode负责:接收用户操作请求 、维护文件系统的目录结构、管理文件与block之间关系,block与datanode之间关系
NameNode 是一个通常在 HDFS 实例中的单独机器上运行的软件。它负责管理文件系统名称空间和控制外部客户机的访问。
datanode负责:存储文件文件被分成block存储在磁盘上、为保证数据安全,文件会有多个副本
MapReduce
主从结构
主节点,只有一个: JobTracker
从节点,有很多个: TaskTrackers
JobTracker负责:接收客户提交的计算任务、把计算任务分给TaskTrackers执行、监控TaskTracker的执行情况
TaskTrackers负责:执行JobTracker分配的计算任务
Hadoop能做什么?
- 大数据量存储:分布式存储
- 日志处理: Hadoop擅长这个
- 海量计算: 并行计算
- ETL:数据抽取到oracle、mysql、DB2、mongdb及主流数据库
- 使用HBase做数据分析: 用扩展性应对大量的写操作—Facebook构建了基于HBase的实时数据分析系统
- 机器学习: 比如Apache Mahout项目
- 搜索引擎:hadoop + lucene实现
- 数据挖掘:目前比较流行的广告推荐
- 大量地从文件中顺序读。HDFS对顺序读进行了优化,代价是对于随机的访问负载较高。
- 数据支持一次写入,多次读取。对于已经形成的数据的更新不支持。
- 数据不进行本地缓存(文件很大,且顺序读没有局部性)
- 任何一台服务器都有可能失效,需要通过大量的数据复制使得性能不会受到大的影响。
- 用户细分特征建模
- 个性化广告推荐
- 智能仪器推荐
扩展
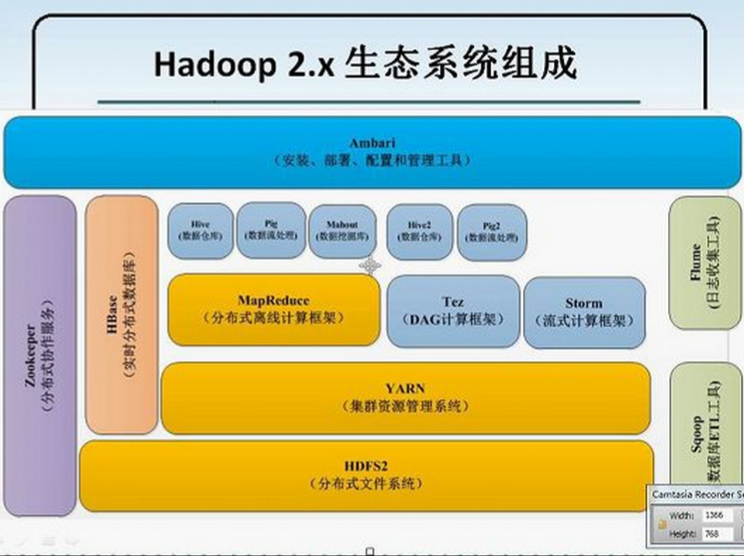
实际应用:
Hadoop+HBase建立NoSQL分布式数据库应用
Flume+Hadoop+Hive建立离线日志分析系统
Flume+Logstash+Kafka+Spark Streaming进行实时日志处理分析
酷狗音乐的大数据平台
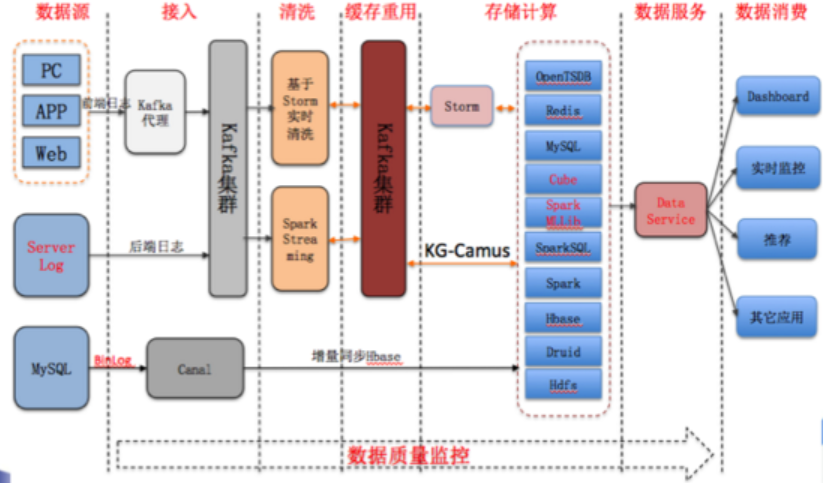
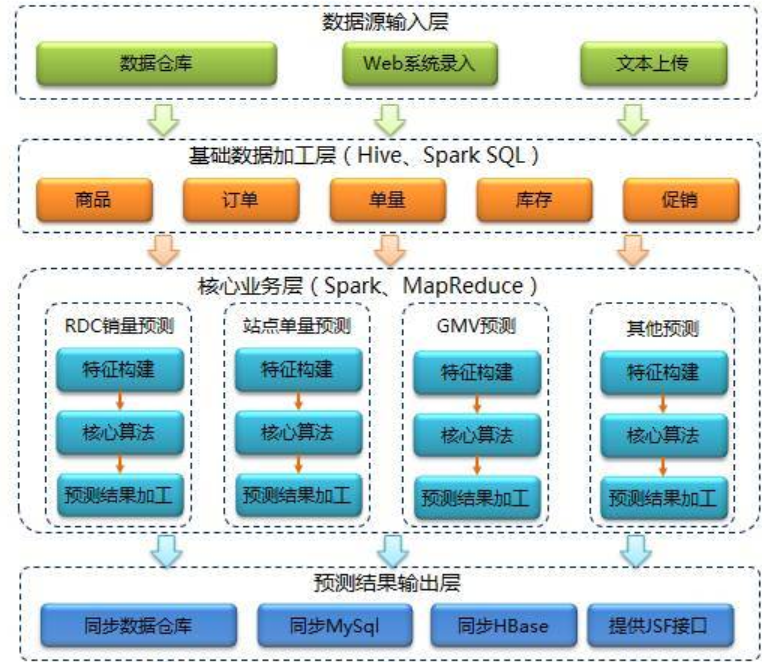
京东的智能供应链预测系统
Hadoop的学习不仅仅是学习Hadoop,还要学习Linux,网络知识,Java、还有数据结构和算法等等,所以万里长征才开始第一步,希望Hadoop学习不是从了解到放弃。
0基础搭建Hadoop大数据处理-初识的更多相关文章
- 0基础搭建Hadoop大数据处理-编程
Hadoop的编程可以是在Linux环境或Winows环境中,在此以Windows环境为示例,以Eclipse工具为主(也可以用IDEA).网上也有很多开发的文章,在此也参考他们的内容只作简单的介绍和 ...
- 0基础搭建Hadoop大数据处理-环境
由于Hadoop需要运行在Linux环境中,而且是分布式的,因此个人学习只能装虚拟机,本文都以VMware Workstation为准,安装CentOS7,具体的安装此处不作过多介绍,只作需要用到的知 ...
- 0基础搭建Hadoop大数据处理-集群安装
经过一系列的前期环境准备,现在可以开始Hadoop的安装了,在这里去apache官网下载2.7.3的版本 http://www.apache.org/dyn/closer.cgi/hadoop/com ...
- 【HADOOP】| 环境搭建:从零开始搭建hadoop大数据平台(单机/伪分布式)-下
因篇幅过长,故分为两节,上节主要说明hadoop运行环境和必须的基础软件,包括VMware虚拟机软件的说明安装.Xmanager5管理软件以及CentOS操作系统的安装和基本网络配置.具体请参看: [ ...
- Hadoop1-认识Hadoop大数据处理架构
一.简介概述 1.什么是Hadoop Hadoop是Apache软件基金会旗下的一个开源分布式计算平台,为用户提供了系统底层细节透明的分布式基础架构 Hadoop是基于java语言开发,具有很好的跨平 ...
- hadoop大数据处理平台与案例
大数据可以说是从搜索引擎诞生之处就有了,我们熟悉的搜索引擎,如百度搜索引擎.360搜索引擎等可以说是大数据技处理技术的最早的也是比较基础的一种应用.大概在2015年大数据都还不是非常火爆,2015年可 ...
- Hadoop2-认识Hadoop大数据处理架构-单机部署
一.Hadoop原理介绍 1.请参考原理篇:Hadoop1-认识Hadoop大数据处理架构 二.centos7单机部署hadoop 前期准备 1.创建用户 [root@web3 ~]# useradd ...
- hadoop大数据处理之表与表的连接
hadoop大数据处理之表与表的连接 前言: hadoop中表连接其实类似于我们用sqlserver对数据进行跨表查询时运用的inner join一样,两个连接的数据要有关系连接起来,中间必须有一个 ...
- 单机,伪分布式,完全分布式-----搭建Hadoop大数据平台
Hadoop大数据——随着计算机技术的发展,互联网的普及,信息的积累已经到了一个非常庞大的地步,信息的增长也在不断的加快.信息更是爆炸性增长,收集,检索,统计这些信息越发困难,必须使用新的技术来解决这 ...
随机推荐
- @PostConstruct 注解
@PostConstruct 注解 /* * Copyright (c) 2005, 2010, Oracle and/or its affiliates. All rights reserved. ...
- 在SSRS的每一页重复显示table header
现在在做一个关于SSRS报表展示的项目,但是我困顿在如何在table的每一页让table header重复显示.因为我在table属性中勾选了"Report header columns o ...
- Hive(笔记)
(2015.07.22Hive笔记) 一.Hive的安装 1.1Hive的安装过程 下载hive源文件(apache-hive-0.14.0-bin.tar.gz ) 解压hive文件 进入$HIVE ...
- JavaEE开发之Spring中的依赖注入与AOP
上篇博客我们系统的聊了<JavaEE开发之基于Eclipse的环境搭建以及Maven Web App的创建>,并在之前的博客中我们聊了依赖注入的相关东西,并且使用Objective-C的R ...
- Centos下PXE+Kickstart无人值守安装操作系统
一.简介 1.1 什么是PXE PXE(Pre-boot Execution Environment,预启动执行环境)是由Intel公司开发的最新技术,工作于Client/Server的网络模式,支持 ...
- 用C语言写的万年历---亲手写的。好累哦
#include <stdio.h>#include <stdlib.h>#include <string.h>#define str " SUN ...
- XAMPP安装报错及解决
FROM:http://www.zeeronsolutions.com/installing-xampp-on-windows-7-user-account-control-uac-warning-m ...
- 浅谈MVC缓存
缓存是将信息放在内存中以避免频繁访问数据库从数据库中提取数据,在系统优化过程中,缓存是比较普遍的优化做法和见效比较快的做法. 对于MVC有Control缓存和Action缓存. 一.Control缓存 ...
- JS中new的运行方式
---恢复内容开始--- 在JS中,有两个基础原型,分别是Function.prototype和Object.prototype.这两个原型组成了JS中的所有实例他们的关系是 Function.pro ...
- cat: can't open '/lib/modules/2.6.35.3-571-gcca29a0/modules.dep': No such file or directory
在使用modprobe 或者modinfo cat: can't open '/lib/modules/2.6.35.3-571-gcca29a0/modules.dep': No such fil ...