SQL Server-聚焦EXISTS AND IN性能分析(十六)
前言
前面我们学习了NOT EXISTS和NOT IN的比较,当然少不了EXISTS和IN的比较,所以本节我们来学习EXISTS和IN的比较,简短的内容,深入的理解,Always to review the basics。
初步探讨EXISTS和IN
我们创建表Table1并且取出前面创建BigTable表中的六条数据并插入其中,同时有一条数据重复,如下:
CREATE TABLE Table1 (IntCol UNIQUEIDENTIFIER)
Insert into Table1 (IntCol) Values ('b927ded5-c78b-4f53-80bf-f65a6ce86d87')
Insert into Table1 (IntCol) Values ('1be326ec-4b62-4feb-8421-d9edf2df28c8')
Insert into Table1 (IntCol) Values ('91c92337-24ba-4ebf-b2a3-14b987179ca6')
Insert into Table1 (IntCol) Values ('c03168f8-c1c7-4903-a8ee-9b4d9c0b6b1f')
Insert into Table1 (IntCol) Values ('c15ac08c-8d3d-4381-9c64-54854ddf15b7')
Insert into Table1 (IntCol) Values ('c15ac08c-8d3d-4381-9c64-54854ddf15b7')
此时我们来进行IN查询
USE TSQL2012
GO SELECT SomeColumn
FROM BigTable
WHERE SomeColumn IN (SELECT IntCol FROM dbo.Table1)

我们在之前讲过若是内部联接中此时会返回六条数据,因为内部联接着重强调的是JOIN后面的表,若右表有多条数据匹配上,此时则会返回多条数据,但是在IN查询中,此时只会返回五条数据,为何如此呢?
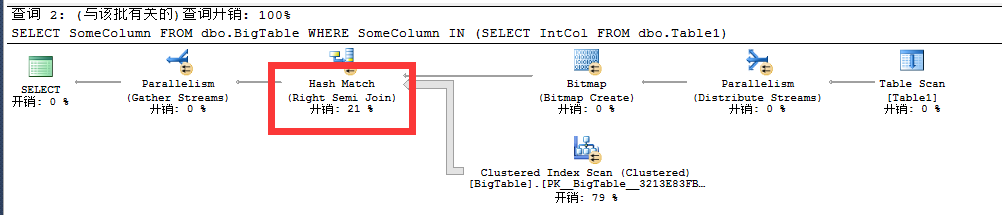
此时用IN查询时即使在子查询中有重复数据时也不会担心出问题,它会自动进行过滤处理,因为在上图中利用了Semi Join半联接中右半联接或左半联接,也就是说只返回重复的数据中的一条。那么在EXISTS中情况又是怎样呢?
SELECT SomeColumn
FROM dbo.BigTable
WHERE EXISTS (SELECT IntCol FROM dbo.Table1)
此时因为没有WHERE条件,此时会返回外部查询表中所有数据,为了和上述IN查询实现等同的结果,我们需要加上WHERE条件
USE TSQL2012
GO SELECT SomeColumn
FROM dbo.BigTable AS bt
WHERE EXISTS (SELECT IntCol FROM dbo.Table1 AS t WHERE bt.SomeColumn = t.IntCol)
而EXISTS相对于IN来说当需要比较两个或两个以上条件时,EXISTS能更好的实现而IN就没那么容易了,比如如下
SELECT SomeColumn
FROM dbo.BigTable AS bt
WHERE EXISTS (SELECT IntCol FROM dbo.Table1 AS t WHERE bt.SomeColumn = t.IntCol AND bt.OtherCol = t.OtherCol)
好了,到了这里我们开始讲讲二者性能问题
进一步探讨EXISTS和IN
我们直接利用前面的表来进行查询
SELECT ID, SomeColumn FROM BigTable
WHERE SomeColumn IN (SELECT LookupColumn FROM SmallerTable) SELECT ID, SomeColumn FROM BigTable
WHERE EXISTS (SELECT LookupColumn FROM SmallerTable WHERE SmallerTable.LookupColumn = BigTable.SomeColumn)

二者都是利用默认的聚集索引扫描和哈希匹配中的右半联接且开销一致。接下来我们再来在二者查询列上创建索引
CREATE INDEX idx_BigTable_SomeColumn
ON BigTable (SomeColumn)
CREATE INDEX idx_SmallerTable_LookupColumn
ON SmallerTable (LookupColumn)
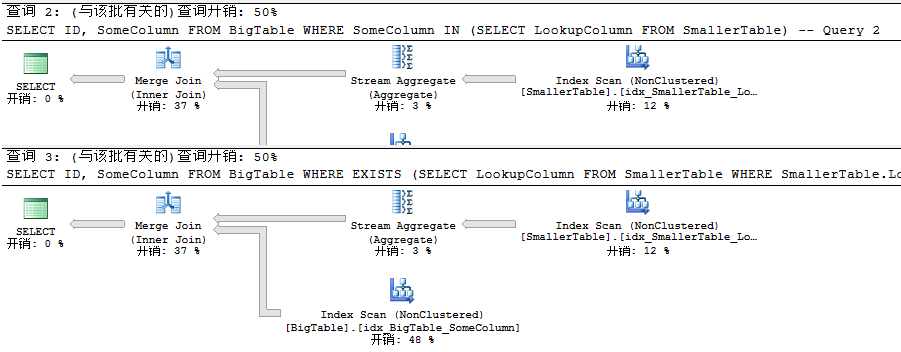
此时只是创建了索引后查询效率改善了,而且查询计划较之前只是哈希匹配中的左半联接替换成了合并联接中的内部联接,同时增加了流聚合。二者在开销上仍是一致的。在我所看其他教程中印象中一直都在说利用EXISTS代替IN,其EXISTS查询性能高于IN,而且事实却是开销一致,难道是100万数据太小,还是场景不够,还是语句不够复杂么。都在说看使用场景,那么到底是在什么场景下EXISTS比IN性能好呢,对此有更深入了解的你们,希望在评论中得到最实际的回答。而我认为觉得用EXISTS的话,只是EXISTS比IN更加灵活而已,而且不会出现意外的结果。下面我们继续往下看。
深入探讨EXISTS和IN
我们接下来看看用IN会出现什么意外的情况,我们首先创建测试表,并插入数据如下:
USE TSQL2012
GO CREATE TABLE table1 (id INT, title VARCHAR(), someIntCol INT)
GO
CREATE TABLE table12 (id INT, t1Id INT, someData VARCHAR())
GO
插入测试数据
INSERT INTO table1
SELECT , 'title 1', UNION ALL
SELECT , 'title 2', UNION ALL
SELECT , 'title 3', UNION ALL
SELECT , 'title 4', UNION ALL
SELECT null, 'title 5', UNION ALL
SELECT null, 'title 6', INSERT INTO table12
SELECT , , 'data 1' UNION ALL
SELECT , , 'data 2' UNION ALL
SELECT , , 'data 3' UNION ALL
SELECT , , 'data 4' UNION ALL
SELECT , , 'data 5' UNION ALL
SELECT , , 'data 6' UNION ALL
SELECT , , 'data 7' UNION ALL
SELECT , null, 'data 8' UNION ALL
SELECT , , 'data 9' UNION ALL
SELECT , , 'data 10' UNION ALL
SELECT , , 'data 11'
table1和table2中的数据分别如下:

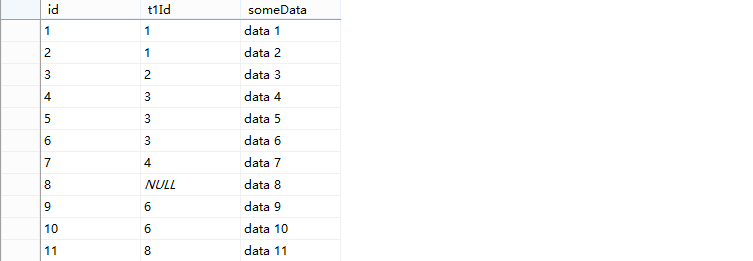
探讨一(IN查询导致错误结果)
我们来对比EXISTS和IN查询,如下:
USE TSQL2012
GO SELECT t1.*
FROM dbo.table1 AS t1
WHERE t1.id IN (SELECT t1id FROM dbo.table12) SELECT t1.*
FROM dbo.table1 AS t1
WHERE exists (SELECT * FROM dbo.table12 AS t2 WHERE t1.id = t2.t1id)

此时二者返回的结果都是正确,接下来我们再来看其他情况,我们需要获取所有table1中数据没有在table2中的所有行。
USE TSQL2012
GO SELECT t1.*
FROM dbo.table1 AS t1
WHERE NOT EXISTS (SELECT * FROM dbo.table12 AS t2 WHERE t1.id = t2.t1id) SELECT t1.*
FROM dbo.table1 as t1
WHERE t1.id NOT IN (SELECT t1id FROM dbo.table12 as t2)

此时利用EXISTS得到了正确的结果,而通过IN查询未达到我们查询的目的,原因之前也有说过IN是基于三值逻辑,此时遇到NULL则会当做UNKNOWN来处理,所以最终得到的结果集是错误的。我们继续往下探讨。
探讨2(手写错误导致意外结果)
我们重新创建测试表并插入测试数据,如下:
USE TSQL2012
GO CREATE TABLE TestTable1 (id1 int)
CREATE TABLE TestTable2 (id2 int) INSERT TestTable1 VALUES(),(),()
INSERT TestTable2 VALUES(),()
我们首先进行如下查询:
USE TSQL2012
GO SELECT *
FROM TestTable1
WHERE id1 IN (SELECT id2 FROM TestTable2)

此时结果是正确的,假如在子查询中我们将列id2写成了id1,那么情况又会是怎样的呢?
SELECT *
FROM TestTable1
WHERE id1 IN (SELECT id1 FROM TestTable2)

不知你是否注意到什么没有,表面是没什么问题,我们接着运行下上述子查询
SELECT id1 FROM TestTable2

单独运行查询时,结果居然出错了,到这了我们再看下创建的表的列,id1是在Table1中而非在Table2中,所以导致了这种意外的错误,如果手写错误,结果数据也有,一般是不会觉察不到,通过使用IN查询就导致了意外的出现。而如下利用EXISTS时会直接报错,而不是得到错误的结果集
SELECT *
FROM t1
WHERE EXISTS (SELECT * FROM TestTable2 t2 WHERE t2.id2 = t1.id1 )
当然了也有人会说根本不会犯这样低级错误,但是谁能保证呢,SQL有智能提示更加容易犯这样的错误,因为直接在子查询就会有这样的列出现,但是该列在子查询表中根本不存在。所以基于探讨的两点,利用EXISTS更加保险。到此,关于EXISTS和IN的介绍算是结束,下此结论。
EXISTS和IN性能分析结论:我们推荐使用EXISTS,而不是IN,原因不是EXISTS性能优于IN,二者性能开销是一样的,而是利用EXISTS比IN更加灵活,更加安全、保险不会出现意想不到的结果。
总结
本节我们讲解了EXISTS和IN,关于其二者在性能方面还是有点疑惑,毕竟场景不够,当然最后还是推荐使用EXISTS,而原因不在于性能。我们下节讲解LEFT JOIN和NOT EXISTS,简短的内容,深入的理解,我们下节再会。
SQL Server-聚焦EXISTS AND IN性能分析(十六)的更多相关文章
- SQL Server-聚焦IN VS EXISTS VS JOIN性能分析(十九)
前言 本节我们开始讲讲这一系列性能比较的终极篇IN VS EXISTS VS JOIN的性能分析,前面系列有人一直在说场景不够,这里我们结合查询索引列.非索引列.查询小表.查询大表来综合分析,简短的内 ...
- 十、SQL中EXISTS的用法 十三、sql server not exists
十.SQL中EXISTS的用法 EXISTS用于检查子查询是否至少会返回一行数据,该子查询实际上并不返回任何数据,而是返回值True或False EXISTS 指定一个子查询,检测 行 的存在. 语法 ...
- SQL Server管理员必备技能之性能优化
SQL Server管理员必备技能之性能优化 高文龙关注1人评论1171人阅读2017-09-22 08:27:41 SQL Server 作为企业必不可少的服务之一,所以对于管理员的日常运维是一个极 ...
- SQL Server一个特殊的阻塞案例分析2
最近发现一个非常奇怪的阻塞问题,如下截图所示(来自监控工具DPA),会话583被会话1036阻塞,而且阻塞发生在tempdb,被阻塞的SQL如下截图所示,会话等待类型为LCK_M_S 因为DPA工具不 ...
- SQL中利用DMV进行数据库性能分析
相信朋友对SQL Server性能调优相关的知识或多或少都有一些了解.虽然说现在NOSQL相关的技术非常的火热,但是RMDB(关系型数据库)与NOSQL是并存的,并且适用在各种的项目中.在一般的企业级 ...
- Sql Server 2012 的新分页方法分析(offset and fetch) - 转载
最近在分析 Sql Server 2012 中 offset and fetch 的新特性,发现 offset and fetch 无论语法的简洁还是功能的强大,都是相当相当不错的 其中 offset ...
- 使用SQL Server 2000索引视图提高性能
什么是索引视图? 许多年来,Microsoft? SQL Server? 一直都提供创建虚拟表(称为视图)的功能.在过去,这些视图主要有两种用途: 提供安全机制,将用户限制在一个或多个基表中的数据的某 ...
- SQL Server 数据库中关于死锁的分析
SQL Server数据库发生死锁时不会像Oracle那样自动生成一个跟踪文件.有时可以在[管理]->[当前活动] 里看到阻塞信息(有时SQL Server企业管理器会因为锁太多而没有响应). ...
- SQL Server里书签查找的性能伤害
在我的博客上,以前我经常谈到SQL Serverl里的书签查找,还有它们带来的很多问题.在今天的文章里,我想从性能角度进一步谈下书签查找,还有它们如何拉低你整个SQL Server性能. 书签查找—— ...
随机推荐
- NodeJs之child_process
一.child_process child_process是NodeJs的重要模块.帮助我们创建多进程任务,更好的利用了计算机的多核性能. 当然也支持线程间的通信. 二.child_process的几 ...
- Asp.Net WebApi核心对象解析(下篇)
在接着写Asp.Net WebApi核心对象解析(下篇)之前,还是一如既往的扯扯淡,元旦刚过,整个人还是处于晕的状态,一大早就来处理系统BUG,简直是坑爹(好在没让我元旦赶过来该BUG),队友挖的坑, ...
- 千呼万唤始出来,微软Power BI简体中文版官网终于上线了,中文文档也全了。。
前几个月时间,研究微软Power BI技术,由于没有任何文档和资料,只能在英文官网瞎折腾,同时也发布了英文文档的相关文章:系列文章,刚好上周把文章发布完,结果简体中文版上线了.哈哈,心里有苦啊,早知道 ...
- 设置tomcat远程debug
查看端口占用情况命令: netstat -tunlp |grep 8000 tomcat 启动远程debug: startup.sh 中的最后一行 exec "$PRGDIR"/& ...
- CSS样式重置(转)
body,h1,h2,h3,h4,h5,h6,dl,dt,dd,ul,ol,li,th,td,p,blockquote,pre,form,fieldset,legend,input,button,te ...
- 3种web会话管理的方式
http是无状态的,一次请求结束,连接断开,下次服务器再收到请求,它就不知道这个请求是哪个用户发过来的.当然它知道是哪个客户端地址发过来的,但是对于我们的应用来说,我们是靠用户来管理,而不是靠客户端. ...
- 【JQ基础】DOM操作
内部插入:append() //向每个匹配的元素内部追加内容,可包含 HTML 标签 $(selector).append(function(index,html)) /*•index - 可选.接收 ...
- NPM如何更新到最新版
参考文章--npm更新到最新版本的方法 其实我们可以这样,随便新建一个文件夹例如:F:\test.按着"shift"键,右键该文件夹,选择"在此处打开命令窗口(W)&qu ...
- IOS开发基础知识--碎片51
1:https关闭证书跟域名的验证 AFSecurityPolicy *securityPolicy = [AFSecurityPolicy defaultPolicy]; securityPolic ...
- Android中Activity的四大启动模式实验简述
作为Android四大组件之一,Activity可以说是最基本也是最常见的组件,它提供了一个显示界面,从而实现与用户的交互,作为初学者,必须熟练掌握.今天我们就来通过实验演示,来帮助大家理解Activ ...