Java实现Tire
Trie,又称单词查找树或键树,是一种树形结构。典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:最大限度地减少无谓的字符串比较,查询效率比哈希表高。
它有3个基本性质:
- 根节点不包含字符,除根节点外每一个节点都只包含一个字符。
- 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
- 每个节点的所有子节点包含的字符都不相同。
下面这个图就是Trie的表示,每一条边表示一个字符,如果结束,就用星号表示。在这个Trie结构里,我们有下面字符串,比如do, dork, dorm等,但是Trie里没有ba, 也没有sen,因为在a, 和n结尾,没有结束符号(星号)。
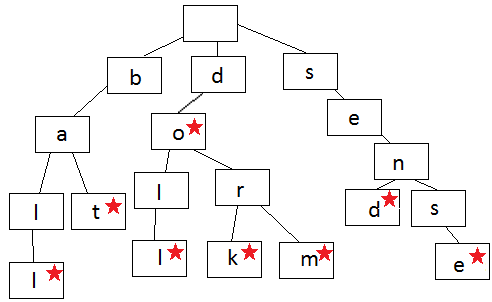
有了这样一种数据结构,我们可以用它来保存一个字典,要查询改字典里是否有相应的词,是否非常的方便呢?我们也可以做智能提示,我们把用户已经搜索的词存在Trie里,每当用户输入一个词的时候,我们可以自动提示,比如当用户输入 ba, 我们会自动提示 bat 和 baii.
现在来讨论Trie的实现。
首先,我们定义一个Abstract Trie,Trie 里存放的是一个Node。这个类里有两个操作,一个是插入,另一个是查询。具体实现放在后面。
实现
Node类:
package com.yydcdut;
import java.util.LinkedList;
public class Node {
char content; //装node中的内容
boolean isEnd; //是否是单词的结尾
int count; //这个单词的这个字母下面分支的个数
LinkedList<Node> childList; //子list
/**
* 构造函数
* @param c 单词的字母
*/
public Node(char c){
childList = new LinkedList<Node>();
isEnd = false;
content = c;
count = 0;
}
/**
* 遍历一下这个node中LinkedList中是否有这个字母,有就意味着可以继续查找下去,没有就没有。
* @param c 单词的字母
* @return 如果有的话就返回下一个node,没有的话就返回null
*/
public Node subNode(char c){
if(childList != null){
for(Node eachChild : childList){
if(eachChild.content == c){
return eachChild;
}
}
}
return null;
}
}
具体实现:
package com.yydcdut;
public class Main {
private Node root; //根
/**
* 构造函数,生成根
*/
public Main(){
root = new Node(' ');
}
/**
* 插入函数,先判断是否有这个单词了(通过每个单词字母来判断),如果没有,挨着顺序判断是否有这个字母了,
*如果有这个字幕,继续判断下一个,当没有这个字母的时候,对这个字母new一个node对象,放入到上一个字母的
*LinkedList里面
* @param word 要插入的单词
*/
public void insert(String word){
//如果找到就返回
if(search(word) == true) return;
Node current = root;
for(int i = 0; i < word.length(); i++){
Node child = current.subNode(word.charAt(i));
if(child != null){
current = child;
} else {
current.childList.add(new Node(word.charAt(i)));
current = current.subNode(word.charAt(i));
}
//单词下面分支数++
current.count++;
}
//在单词最后字母那里结束了
current.isEnd = true;
}
/**
* 查找函数,判断是否已经有隔着单词了
* @param word 要判断的单词
* @return 有这个单词返回true,没有返回false
*/
public boolean search(String word){
Node current = root;
for(int i = 0; i < word.length(); i++){
if(current.subNode(word.charAt(i)) == null)
return false;
else
current = current.subNode(word.charAt(i));
}
//判断这个单词的这个字母是否在字典里面结束了
if (current.isEnd == true) return true;
else return false;
}
/**
* 删除函数,先判断是否存在这个单词,不存在就跳出,存在就删除掉,每个单词的count都要减1
* @param word 要删除的单词
*/
public void deleteWord(String word){
if(search(word) == false) return;
Node current = root;
for(char c : word.toCharArray()) {
Node child = current.subNode(c);
if(child.count == 1) {
current.childList.remove(child);
return;
} else {
child.count--;
current = child;
}
}
current.isEnd = false;
}
public static void main(String[] args) {
Main trie = new Main();
trie.insert("ball");
trie.insert("balls");
trie.insert("sense");
System.out.println(trie.search("balls"));
System.out.println(trie.search("ba"));
trie.deleteWord("balls");
System.out.println(trie.search("balls"));
System.out.println(trie.search("ball"));
}
}
时间复杂度分析:
对于insert, 如果被插入的String长度是 k, 每对一个字符进行查询,我们最多在child linkedlist里面查询26次(最多26个字母),所以,复杂度为O(26*k) = O(k). 对于 search, 复杂度是一样的。
我是天王盖地虎的分割线
源代码:http://pan.baidu.com/s/1dD1Qx01
trie.zip
参考:http://blog.csdn.net/beiyeqingteng
Java实现Tire的更多相关文章
- Spark案例分析
一.需求:计算网页访问量前三名 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /* ...
- 基于Tire树和最大概率法的中文分词功能的Java实现
对于分词系统的实现来说,主要应集中在两方面的考虑上:一是对语料库的组织,二是分词策略的制订. 1. Tire树 Tire树,即字典树,是通过字串的公共前缀来对字串进行统计.排序及存储的一种树形结构 ...
- Tire树
Trie树,又称单词查找树或键树,是一种树形结构,是一种哈希树的变种. 典型应用是用于统计和排序大量的字符串(但不仅限于字符串), 所以经常被搜索引擎系统用于文本词频统计. 字典树(Trie)可以保存 ...
- 一种c#深拷贝方式完胜java深拷贝(实现上的对比)
楼主是一名asp.net攻城狮,最近经常跑java组客串帮忙开发,所以最近对java的一些基础知识特别上心.却遇到需要将一个对象深拷贝出来做其他事情,而原对象保持原有状态的情况.(实在是不想自己new ...
- 《Java程序员面试笔试宝典》之组合与继承有什么区别
组合和继承是面向对象中两种代码复用的方式.组合是指在新类里面创建原有类的对象,重复利用已有类的功能.继承是面向对象的主要特性之一,它允许设计人员根据其它类的实现来定义一个类的实现.组合和继承都允许在新 ...
- Ancient Printer(tire树)
Ancient Printer Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 131072/65536 K (Java/Others) ...
- 最新阿里Java技术面试题,看这一文就够了!
金三银四跳槽季即将到来,作为 Java 开发者你开始刷面试题了吗?别急,小编整理了阿里技术面试题,看这一文就够了! 阿里面试题目目录 技术一面(基础面试题目) 技术二面(技术深度.技术原理) 项目实战 ...
- Java面试 32个核心必考点完全解析
目录 课程预习 1.1 课程内容分为三个模块 1.2 换工作面临问题 1.3 课程特色 课时1:技术人职业发展路径 1.1 工程师发展路径 1.2 常见技术岗位划分 1.3 面试岗位选择 1.4 常见 ...
- 双数组Trie树(DoubleArrayTrie)Java实现
http://www.hankcs.com/program/java/%E5%8F%8C%E6%95%B0%E7%BB%84trie%E6%A0%91doublearraytriejava%E5%AE ...
随机推荐
- Android IOS WebRTC 音视频开发总结(五四)-- WebRTC标准之父谈WebRTC
本文主要是整理自国内首届WebRTC大会上对Daniel的一些专访,转载必须说明出处,欢迎关注微信公众号blacker,更多说明详见www.rtc.help 说明:以下内容主要整理自InfoQ的专访, ...
- C++类成员函数的 重载、覆盖和隐藏区别
重载:成员函数被重载的特征: (1)相同的范围(在同一个类中): (2)函数名字相同: (3)参数不同: (4)virtual 关键字可有可无. #include <iostream> u ...
- Java中join的使用
join用于主线程等待子线程运行完毕它的run方法,再继续执行下面的代码. join() = join(0),主线程无限等待子线程执行完毕. join(n milliseconds),主线程只等待n毫 ...
- 泛型集合转换为DataTable
在做项目中,遇到了将集合转换为DataTable的使用,在网上看了资料,在这里记录下来,分享. using System; using System.Collections.Generic; usin ...
- http://www.shanghaihaocong.com-WORDPRESS开发的企业主题站
wordpress是世界上使用最多的php开源博客系统,功能强大,而且拥有众多的插件,可扩展性强. 最近,我也用它做了一个企业网站,欢迎浏览:http://www.shanghaihaocong.co ...
- linux分区和文件系统
linux分区主分区:最多只能有4个扩展分区:最多只能有一个 主分区+扩展分区最多4个 扩展分区不能写入数据,只能包含逻辑分区 见图示:fq.png 主分区:总共最多只能分4个扩展分区:只能有1个,也 ...
- PHP通过字符串调用函数
1. call_user_func function a($b,$c){ echo $b; echo $c; } call_user_func('a', "111","2 ...
- char引发的血案
char cc = 'j';cc = (char)(cc -32); //注意下,自动转型了System.out.println(cc);
- Android的ADT内容助手快捷方式设置
请注明出处:http://www.cnblogs.com/killerlegend/p/3550019.html Written By KillerLegend 先将Word Completion的 ...
- C#判断ip地址是否ping的通
Ping pingSender = new Ping(); PingReply reply = pingSender.Send("127.0.0.1",120);//第一个参数为i ...