Boost无锁队列
在开发接收转发agent时,采用了多线程的生产者-消费者模式,用了加互斥锁的方式来实现线程同步。互斥锁会阻塞线程,所以压测时,效率并不高。所以想起用无锁队列来实现,性能确实提升了。
首先介绍下lock-free和wait-free的区别:
阻塞算法可能会出现整个系统都挂起的情况(占有锁的线程被中断,无法释放所,那么所有试图争用这个锁的线程会被挂起),系统中的所有线程全部饿死。
无锁算法可以保证系统中至少有一个线程处于工作状态,但是还是可能有线程永远抢不到资源而被饿死。
无等待算法保证系统中的所有线程都能处于工作状态,没有线程会被饿死,只要时间够,所有线程都能结束。相比于无锁算法,无等待算法有更强的保证。
一. 用互斥锁实现单生产者-单消费者
#include <string>
#include <sstream>
#include <list>
#include <pthread.h>
#include <iostream>
#include <time.h>
using namespace std;
int producer_count = 0;
int consumer_count = 0;
list<string> product;
list<string> consumer_list;
pthread_mutex_t mutex;
const int iterations = 10000;
//是否生产完毕标志
bool done = false;
void* producer(void* args)
{
for (int i = 0; i != iterations; ++i) {
pthread_mutex_lock(&mutex);
int value = ++producer_count;
stringstream ss;
ss<<value;
product.push_back(ss.str());
//cout<<"list push:"<<ss.str()<<endl;
pthread_mutex_unlock(&mutex);
}
return 0;
}
//消费函数
void* consumer(void* args)
{
//当没有生产完毕,则边消费边生产
while (!done) {
pthread_mutex_lock(&mutex);
if(!product.empty()){
consumer_list.splice(consumer_list.end(), product);
pthread_mutex_unlock(&mutex);
while(!consumer_list.empty()){
string value = consumer_list.front();
consumer_list.pop_front();
//cout<<"list pop:"<<value<<endl;
++consumer_count;
}
}else{
pthread_mutex_unlock(&mutex);
}
}
//如果生产完毕,则消费
while(!consumer_list.empty()){
string value = consumer_list.front();
consumer_list.pop_front();
//cout<<"list pop:"<<value<<endl;
++consumer_count;
}
return 0;
}
int main(int argc, char* argv[])
{
struct timespec time_start={0, 0},time_end={0, 0};
clock_gettime(CLOCK_REALTIME, &time_start);
pthread_t producer_tid;
pthread_t consumer_tid;
pthread_mutex_init (&mutex,NULL);
pthread_create(&producer_tid, NULL, producer, NULL);
pthread_create(&consumer_tid, NULL, consumer, NULL);
//等待生产者生产完毕
pthread_join(producer_tid, NULL);
//可以消费标志
done = true; //主线程不等生产线程完毕就设置done标记
cout << "producer done" << endl; //输出以观察主线程和各子线程的执行顺序
//等待消费者结束
pthread_join(consumer_tid, NULL);
clock_gettime(CLOCK_REALTIME, &time_end);
long cost = (time_end.tv_sec-time_start.tv_sec)/1000000 + (time_end.tv_nsec-time_start.tv_nsec)/1000;
cout<<"===========cost time:"<<cost<<"us==========="<<endl;
cout << "produced " << producer_count << " objects." << endl;
cout << "consumed " << consumer_count << " objects." << endl;
}生产消费10000个string类型的数据,耗时:58185us
二. Boost库的无锁队列
boost.lockfree实现了三种无锁数据结构:
boost::lockfree::queue
alock-free multi-produced/multi-consumer queue
一个无锁的多生产者/多消费者队列,注意,这个queue不支持string类型,支持的数据类型要求:
- T must have a copy constructor
- T must have a trivial assignment operator
- T must have a trivial destructor
boost::lockfree::stack
alock-free multi-produced/multi-consumer stack
一个无锁的多生产者/多消费者栈,支持的数据类型要求:
- T must have a copy constructor
boost::lockfree::spsc_queue
await-free single-producer/single-consumer queue (commonly known as ringbuffer)
一个无等待的单生产者/单消费者队列(通常被称为环形缓冲区),支持的数据类型要求:
- T must have a default constructor
- T must be copyable
详细资料可以看官方文档:http://www.boost.org/doc/libs/1_55_0/doc/html/lockfree.html
三. Queue示例
这里实现的还是单生产者-单消费者。
#include <pthread.h>
#include <boost/lockfree/queue.hpp>
#include <iostream>
#include <time.h>
#include <boost/atomic.hpp>
using namespace std;
//生产数量
boost::atomic_int producer_count(0);
//消费数量
boost::atomic_int consumer_count(0);
//队列
boost::lockfree::queue<int> queue(512);
//迭代次数
const int iterations = 10000;
//生产函数
void* producer(void* args)
{
for (int i = 0; i != iterations; ++i) {
int value = ++producer_count;
//原子计数————多线程不存在计数不上的情况
//若没有进入队列,则重复推送
while(!queue.push(value));
//cout<<"queue push:"<<value<<endl;
}
return 0;
}
//是否生产完毕标志
boost::atomic<bool> done (false);
//消费函数
void* consumer(void* args)
{
int value;
//当没有生产完毕,则边消费边生产
while (!done) {
//只要能弹出元素,就消费
while (queue.pop(value)) {
//cout<<"queue pop:"<<value<<endl;
++consumer_count;
}
}
//如果生产完毕,则消费
while (queue.pop(value)){
//cout<<"queue pop:"<<value<<endl;
++consumer_count;
}
return 0;
}
int main(int argc, char* argv[])
{
cout << "boost::lockfree::queue is ";
if (!queue.is_lock_free())
cout << "not ";
cout << "lockfree" << endl;
struct timespec time_start={0, 0},time_end={0, 0};
clock_gettime(CLOCK_REALTIME, &time_start);
pthread_t producer_tid;
pthread_t consumer_tid;
pthread_create(&producer_tid, NULL, producer, NULL);
pthread_create(&consumer_tid, NULL, consumer, NULL);
//等待生产者生产完毕
pthread_join(producer_tid, NULL);
//可以消费标志
done = true; //主线程不等生产线程完毕就设置done标记
cout << "producer done" << endl; //输出以观察主线程和各子线程的执行顺序
//等待消费者结束
pthread_join(consumer_tid, NULL);
clock_gettime(CLOCK_REALTIME, &time_end);
long cost = (time_end.tv_sec-time_start.tv_sec)/1000000 + (time_end.tv_nsec-time_start.tv_nsec)/1000;
cout<<"===========cost time:"<<cost<<"us==========="<<endl;
//输出生产和消费数量
cout << "produced " << producer_count << " objects." << endl;
cout << "consumed " << consumer_count << " objects." << endl;
return 0;
}生产消费10000个int类型的数据,耗时:3963us
stack与queue类似,只不过是先进后出。
四. Waitfree Single-Producer/Single-Consumer Queue无等待单生产者/单消费者队列
#include <pthread.h>
#include <iostream>
#include <time.h>
#include <boost/lockfree/spsc_queue.hpp>
#include <boost/atomic.hpp>
using namespace std;
int producer_count = 0;
boost::atomic_int consumer_count (0);
boost::lockfree::spsc_queue<int, boost::lockfree::capacity<1024> > spsc_queue;
const int iterations = 10000;
void* producer(void* args)
{
for (int i = 0; i != iterations; ++i) {
int value = ++producer_count;
while(!spsc_queue.push(value));
//cout<<"queue push:"<<value<<endl;
}
return 0;
}
//是否生产完毕标志
boost::atomic<bool> done (false);
//消费函数
void* consumer(void* args)
{
int value;
//当没有生产完毕,则边消费边生产
while (!done) {
//只要能弹出元素,就消费
while (spsc_queue.pop(value)) {
//cout<<"queue pop:"<<value<<endl;
++consumer_count;
}
}
//如果生产完毕,则消费
while (spsc_queue.pop(value)){
//cout<<"queue pop:"<<value<<endl;
++consumer_count;
}
return 0;
}
int main(int argc, char* argv[])
{
using namespace std;
cout << "boost::lockfree::queue is ";
if (!spsc_queue.is_lock_free())
cout << "not ";
cout << "lockfree" << endl;
struct timespec time_start={0, 0},time_end={0, 0};
clock_gettime(CLOCK_REALTIME, &time_start);
pthread_t producer_tid;
pthread_t consumer_tid;
pthread_create(&producer_tid, NULL, producer, NULL);
pthread_create(&consumer_tid, NULL, consumer, NULL);
//等待生产者生产完毕
pthread_join(producer_tid, NULL);
//可以消费标志
done = true; //主线程不等生产线程完毕就设置done标记
cout << "producer done" << endl; //输出以观察主线程和各子线程的执行顺序
//等待消费者结束
pthread_join(consumer_tid, NULL);
clock_gettime(CLOCK_REALTIME, &time_end);
long cost = (time_end.tv_sec-time_start.tv_sec)/1000000 + (time_end.tv_nsec-time_start.tv_nsec)/1000;
cout<<"===========cost time:"<<cost<<"us==========="<<endl;
cout << "produced " << producer_count << " objects." << endl;
cout << "consumed " << consumer_count << " objects." << endl;
}生产消费10000个int类型的数据,耗时:1832us
如果把int改为string类型,耗时:28788us
五.性能对比
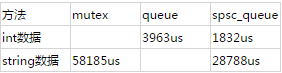
从上面可以看出在单生产者-单消费者模式下,spsc_queue比queue性能好,无锁队列比互斥锁的方式性能也要好。
Boost无锁队列的更多相关文章
- boost 无锁队列
一哥们翻译的boost的无锁队列的官方文档 原文地址:http://blog.csdn.net/great3779/article/details/8765103 Boost_1_53_0终于迎来了久 ...
- 基于Boost无锁队列实现的内存池
- 无锁队列以及ABA问题
队列是我们非常常用的数据结构,用来提供数据的写入和读取功能,而且通常在不同线程之间作为数据通信的桥梁.不过在将无锁队列的算法之前,需要先了解一下CAS(compare and swap)的原理.由于多 ...
- HashMap的原理与实 无锁队列的实现Java HashMap的死循环 red black tree
http://www.cnblogs.com/fornever/archive/2011/12/02/2270692.html https://zh.wikipedia.org/wiki/%E7%BA ...
- zeromq源码分析笔记之无锁队列ypipe_t(3)
在上一篇中说到了mailbox_t的底层实际上使用了管道ypipe_t来存储命令.而ypipe_t实质上是一个无锁队列,其底层使用了yqueue_t队列,ypipe_t是对yueue_t的再包装,所以 ...
- 一个可无限伸缩且无ABA问题的无锁队列
关于无锁队列,详细的介绍请参考陈硕先生的<无锁队列的实现>一文.然进一步,如何实现一个不限node数目即能够无限伸缩的无锁队列,即是本文的要旨. 无锁队列有两种实现形式,分别是数组与链表. ...
- 无锁队列--基于linuxkfifo实现
一直想写一个无锁队列,为了提高项目的背景效率. 有机会看到linux核心kfifo.h 原则. 所以这个实现自己仿照,眼下linux我们应该能够提供外部接口. #ifndef _NO_LOCK_QUE ...
- CAS简介和无锁队列的实现
Q:CAS的实现 A:gcc提供了两个函数 bool __sync_bool_compare_and_swap (type *ptr, type oldval, type newval, ...)// ...
- Go语言无锁队列组件的实现 (chan/interface/select)
1. 背景 go代码中要实现异步很简单,go funcName(). 但是进程需要控制协程数量在合理范围内,对应大批量任务可以使用"协程池 + 无锁队列"实现. 2. golang ...
随机推荐
- Windows 10 安装FileZilla Server
在windows 10本机安装了FileZilla Server 本机用FilleZilla Client连接localhost或者192.168.0.197 port 21 都可以连通,但是在同 ...
- 单点登录系统SSO实现
前些天被问到单点登录了,而据我当时做的这个模块两年了,现在重新温习并记录下,方便以后快速回忆起来 一.什么是单点登录系统 SSO全称Single Sign On.SSO是用户只需要登录一次就可以访问所 ...
- Delphi MSComm 控件方法
- 用Python+Aria2写一个自动选择最优下载方式的E站爬虫
前言 E站爬虫在网上已经有很多了,但多数都只能以图片为单位下载,且偶尔会遇到图片加载失败的情况:熟悉E站的朋友们应该知道,E站许多资源都是有提供BT种子的,而且通常打包的是比默认看图模式更高清的文件: ...
- Go语言基础之Cookie和Session
Cookie和Session Cookie和Session是Web开发绕不开的一个环节,本文介绍了Cookie和Session的原理及在Go语言中如何操作Cookie. Cookie Cookie的由 ...
- 【ARC072 E】Alice in linear land
被智商题劝退,告辞 题意 有一个人在一条数轴的距离原点为 \(D\) 的位置,他可以执行 \(n\) 次操作,每次操作为给定一个整数 \(d_i\),这个人向原点的方向走 \(d_i\) 个单位,但如 ...
- .NET平台的发展
.NET平台的发展.NET从1.0到.NET Core3.0:C#从1.0到8.0: ASP.NET从1.0到Core3.0: ASP.NET MVC1.0到ASP.NET MVC6.0,
- 【u-boot】u-boot中initf_dm()函数执行流程(转)
前部分设备模型初始化 为了便于阅读,删掉部分代码,只留关键的过程: static int initf_dm(void){ int ret; ret = dm_init_and_scan(t ...
- spring RestTemplate 出现 NoHttpResponseException 和 ConnectionTimeoutException
使用 httpclient.4.5.6 springboot 2.0.8RELEASE RetryExec.java CloseableHttpResponse execute() try { ret ...
- 水果商城 ( Iview+ SSM + MySQL )
因为时间原因,只做了后台,前台本来是打算使用 uni 框架 的. 有文档.E-R流程图.数据库文件. 项目源码地址:https://github.com/oukele/MyProject-Two