Pytorch入门随手记
Pytorch入门随手记
什么是Pytorch?
Pytorch是Torch到Python上的移植(Torch原本是用Lua语言编写的)
是一个动态的过程,数据和图是一起建立的。
tensor.dot(tensor1,tensor2)//tensor各个对应位置相乘再相加
print(net)可以输出网络结构
Pytorch的动态性:网络参数可以有多个不固定的,例如:
来源:https://morvanzhou.github.io/tutorials/machine-learning/torch/5-01-dynamic/
最典型的例子就是 RNN, 有时候 RNN 的 time step 不会一样, 或者在 training 和 testing 的时候,
batch_size和time_step也不一样, 这时, Tensorflow 就头疼了, Tensorflow 的人也头疼了. 哈哈, 如果用一个动态计算图的 Torch, 我们就好理解多了, 写起来也简单多了.激活函数使用层和function,在效果上没什么区别
使用torch.nn.Sequential快速搭建模型
torch.nn.Sequential(
#eg
torch.nn.linear(2,10),
torch.nn.ReLU(),
torch.nn.linear(10,2),
)
这里使用的是匿名对象,所以print出来之后是没有类型名称(即self.hidden和self.predict之类的,输出的时候会显示hidden和predict).
保存和提取神经网络
保存
torch.save(net,"net.pkl")#保存整个神经网络模型,类型名为pkl
torch.save(net.state_dict(),"net_params.pkl")#只保存参数而不保存整个网络
提取
net=torch.load("net.pkl")#提取网络
net2=torch.nn.Sequential(
这里只是举了用Sequential来创建网络的例子,如果不用这种匿名方法的话也是一样的,就是在提取参数之前要搭建一个和原网络完全一样的网络结构
)
net2.load_state_dict(torch.load("net_params.pkl"))#只提取参数
批训练(Mini Batch Training)
BATCH_SIZE=5
x=torch.linspace(1,10,10)
y=torch.linspace(10,1,10)
torch_dataset=Data.TensorDataset(data_tensor=x,target_tensor=y)
loader=Data.DataLoader(
dataset=torch_dataset,
batch_size=BATCH_SIZE,
shuffle=True,#shuffle如果设置为true,则每次batch都是选择的不一样的数据,设置为False,则每次batch的数据都一样。
num_workers=2,#设置提取数据时候的线程数量
)
for epoch in range(3):
for step,(batch_x,batch_y)in enumerate(loader):#enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
#例如本例中,那个step就是提取的index超参数:在机器学习的上下文中,超参数是在开始学习过程之前设置值的参数,而不是通过训练得到的参数数据。通常情况下,需要对超参数进行优化,给学习机选择一组最优超参数,以提高学习的性能和效果。
由此可见,超参数一般是人为指定的、定义在模型之前的一些全局变量,它对模型和训练的过程进行控制。习惯上,用大写来表示。
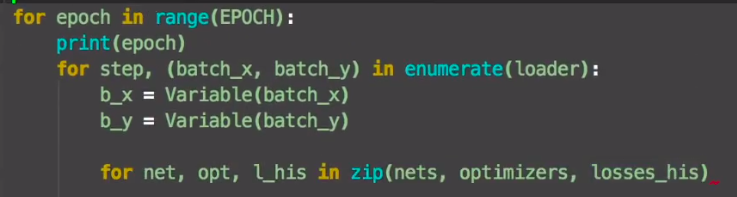
我觉得它第三个for循环和zip合起来还挺灵性的。
len(train_loader)和len(train_loader.dataset)的区别
这里举个例子:
train_loader = torch.utils.data.DataLoader(
dataset=torch_train_dataset,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=WORKERS)
len(train_loader.dataset)=len(torch_train_dataset),也就是数据集的大小,和batch_size无关
而len(train_loader)=len(train_loader.dataset)/batch_size并向上取整
Pytorch入门随手记的更多相关文章
- [pytorch] Pytorch入门
Pytorch入门 简单容易上手,感觉比keras好理解多了,和mxnet很像(似乎mxnet有点借鉴pytorch),记一记. 直接从例子开始学,基础知识咱已经看了很多论文了... import t ...
- pytorch 入门指南
两类深度学习框架的优缺点 动态图(PyTorch) 计算图的进行与代码的运行时同时进行的. 静态图(Tensorflow <2.0) 自建命名体系 自建时序控制 难以介入 使用深度学习框架的优点 ...
- 超简单!pytorch入门教程(五):训练和测试CNN
我们按照超简单!pytorch入门教程(四):准备图片数据集准备好了图片数据以后,就来训练一下识别这10类图片的cnn神经网络吧. 按照超简单!pytorch入门教程(三):构造一个小型CNN构建好一 ...
- pytorch入门2.2构建回归模型初体验(开始训练)
pytorch入门2.x构建回归模型系列: pytorch入门2.0构建回归模型初体验(数据生成) pytorch入门2.1构建回归模型初体验(模型构建) pytorch入门2.2构建回归模型初体验( ...
- pytorch入门2.0构建回归模型初体验(数据生成)
pytorch入门2.x构建回归模型系列: pytorch入门2.0构建回归模型初体验(数据生成) pytorch入门2.1构建回归模型初体验(模型构建) pytorch入门2.2构建回归模型初体验( ...
- pytorch入门2.1构建回归模型初体验(模型构建)
pytorch入门2.x构建回归模型系列: pytorch入门2.0构建回归模型初体验(数据生成) pytorch入门2.1构建回归模型初体验(模型构建) pytorch入门2.2构建回归模型初体验( ...
- Pytorch入门——手把手教你MNIST手写数字识别
MNIST手写数字识别教程 要开始带组内的小朋友了,特意出一个Pytorch教程来指导一下 [!] 这里是实战教程,默认读者已经学会了部分深度学习原理,若有不懂的地方可以先停下来查查资料 目录 MNI ...
- Pytorch入门上 —— Dataset、Tensorboard、Transforms、Dataloader
本节内容参照小土堆的pytorch入门视频教程.学习时建议多读源码,通过源码中的注释可以快速弄清楚类或函数的作用以及输入输出类型. Dataset 借用Dataset可以快速访问深度学习需要的数据,例 ...
- Pytorch入门中 —— 搭建网络模型
本节内容参照小土堆的pytorch入门视频教程,主要通过查询文档的方式讲解如何搭建卷积神经网络.学习时要学会查询文档,这样会比直接搜索良莠不齐的博客更快.更可靠.讲解的内容主要是pytorch核心包中 ...
随机推荐
- 定位ScheduledExecutorService过了一段时间不执行问题
今天查看生产环境的sentinel控制台,发现某dubbo应用一共5个节点,有3个失联了. 查看失联节点的应用日志,服务没有挂,各dubbo接口的日志正常在打印. 在应用节点ping/telnet s ...
- 高性能高可用的微服务框架TarsGo的腾讯实践
conference/2.3 高性能高可用的微服务框架TarsGo的腾讯实践 - 陈明杰.pdf at master · gopherchina/conferencehttps://github.co ...
- Git报错: OpenSSL SSL_connect: SSL_ERROR_SYSCALL in connection to github.com:443
在使用Git来克隆仓库报了错误,如下: fatal: unable to access ‘https://github.com/xiaobingchan/machine_learn/‘: OpenSS ...
- 上证50ETF申赎清单
[ETF50] Fundid1=510051 CreationRedemptionUnit=900000 MaxCashRatio=0.50000 Publish=1 CreationRedempti ...
- ArcMap 制作广州 18 级地图切片需要多少时间?
制作地图切片包会随着级别的上升,瓦片数量会指数级地上升,所需的计算时间也是指数级的. 但是 ArcMap 并不会提示时间信息,只有一个圈没完没了地转... 就在这无聊地等待中,我写了这篇帖子. 电脑配 ...
- java 面试题汇总
一.Java 基础 1.JDK 和 JRE 有什么区别? JDK是java开发工具包,提供java的开发环境和运行环境.包括编译器.开发工具和更多的类库等.JDK包含了JRE. JRE是java运行环 ...
- 创建多个Fragment可滑动界面
创建新项目,选择Tabbed Activity 默认就有2个Fragment,这里我们删除相关代码. 在切换时 FragmentPagerAdapter onDestroyView onCreateV ...
- vue文字向上滚动
<template> <vue-seamless-scroll :data="listData" :class-option="optionHover& ...
- Springboot 使用Jwt token失效时接口无响应(乌龙)
问题背景:新项目使用Springboot框架,鉴权使用了Jwt 处理cors: @Configuration public class WebMvcConfig implements WebMvcCo ...
- [转帖]强大的strace命令用法详解
强大的strace命令用法详解 文章转自: https://www.linuxidc.com/Linux/2018-01/150654.htm strace是什么? 按照strace官网的描述, st ...