Scrapy各部分运行机制?Xpath为None?多层Response如何编写?搞定Scrapy的坑
前言
Scrapy那么多模块都是怎么结合的啊?明明在chrome上的xpath helper插件写好了xpath,为什么到程序就读取的是None?Scrapy可以直接写多层response么?难道必须再使用requests库??
没关系,这篇文章一站式解答scrapy常见的坑
Scrapy各部分运行机制
Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
Scrapy 使用了 Twisted['twɪstɪd](其主要对手是Tornado)异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。

Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
Downloader Middlewares(下载中间件):可以当作是一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
网上看到某位大佬生动形象的讲述了如何进行工作,易于理解:
Scrapy的运作流程
代码写好,程序开始运行...
引擎:Hi!Spider, 你要处理哪一个网站?
Spider:老大要我处理xxxx.com。
引擎:你把第一个需要处理的URL给我吧。
Spider:给你,第一个URL是xxxxxxx.com。
引擎:Hi!调度器,我这有request请求你帮我排序入队一下。
调度器:好的,正在处理你等一下。
引擎:Hi!调度器,把你处理好的request请求给我。
调度器:给你,这是我处理好的request
引擎:Hi!下载器,你按照老大的下载中间件的设置帮我下载一下这个request请求
下载器:好的!给你,这是下载好的东西。(如果失败:sorry,这个request下载失败了。然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载)
引擎:Hi!Spider,这是下载好的东西,并且已经按照老大的下载中间件处理过了,你自己处理一下(注意!这儿responses默认是交给def parse()这个函数处理的)
Spider:(处理完毕数据之后对于需要跟进的URL),Hi!引擎,我这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的Item数据。
引擎:Hi !管道 我这儿有个item你帮我处理一下!调度器!这是需要跟进URL你帮我处理下。然后从第四步开始循环,直到获取完老大需要全部信息。
管道``调度器:好的,现在就做!
注意:只有当调度器没有request需要处理时,整个程序才会停止。(对于下载失败的URL,Scrapy也会重新下载。)
Xpath问题
有的网站明明使用了xpath helper插件写好了xpath语句并且chrome验证没问题,但是偏偏到response.xpath的时候就是取不出来值,一直为None,问题出在哪了呢????
首先我们需要知道,我们在浏览器中看到的html代码可能与从scrapy得到的不一样,所以有时候就会出现在浏览器的xpath无法在程序中使用的问题
解决方法
- 如果是国外网站,首先注意一点就是chrome的自动翻译功能,建议选择显示原始网页,然后进行编写
- 据某些网友说,某些情况 xpath中含有 tbody 是浏览器规范化额外加上去的标签,实际的网页源码并没有 所以我们需要手动删除
终极解决方案 scrapy shell
不是说scrapy得到的跟我们在浏览器看到的不同吗?好的,那我们就直接去scrapy得到的响应去看看!
打开命令行,输入命令 scrapy shell url 如百度
D:\pythonwork>scrapy shell www.baidu.com
会发现现在我们进入了scrapy的shell之中
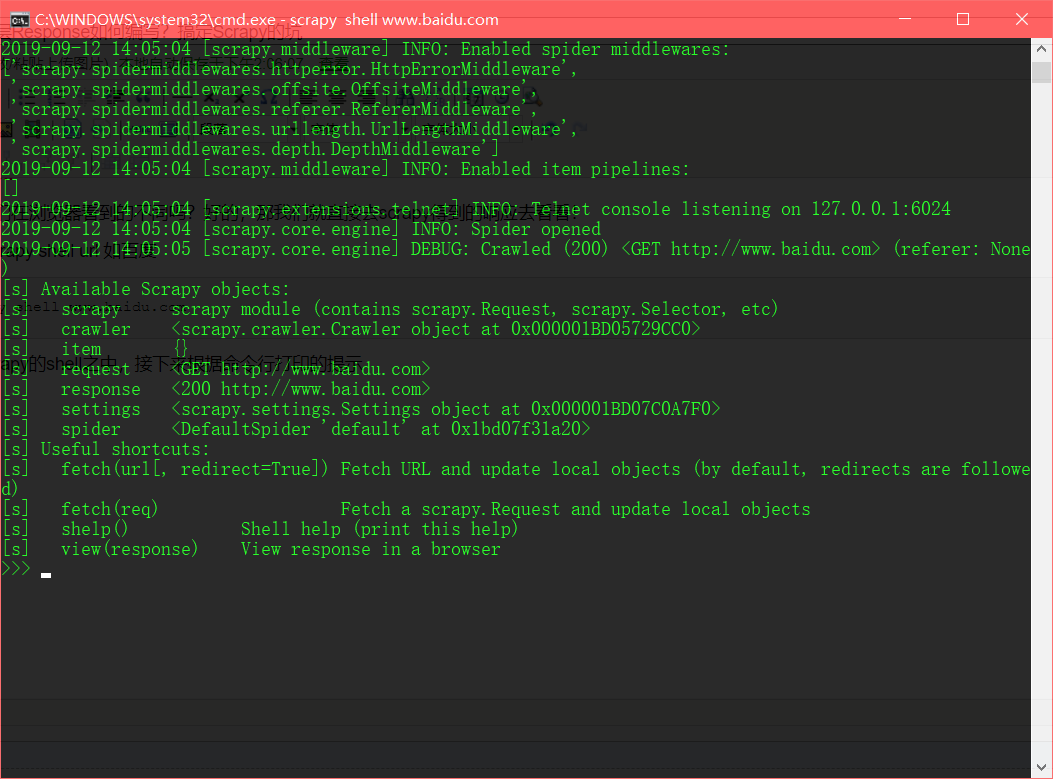
接下来根据提示 输入 view(response) 发现自动开启了浏览器打开了本地的一个网页
没错,这个就是通过scrapy得到的response 直接对于这个网页操作,这下就可以找到适用于我们程序的xpath了 (xpath helper需要在设置中开启允许访问文件网址即本地文件)

肯定有小伙伴发现某些网页403进不去,仔细想想为什么?因为命令行直接进去的是没有用户代理的,一些网站需要我们自己修改user-agent,怎么办?
我们可以在已经编写好各种设置settings的scrapy项目目录下使用scrapy,不然只会使用默认settings
多层Response的编写
我们在使用Scrapy做爬虫的时候经常碰到数据分布在多个页面,要发去多次请求才能收集到足够的信息,例如第一个页面只有简单的几个列表信息,更多的信息在其他request的response中。
而我们一般只写如 yield scrapy.Request(next_link,callback=self.parse) 只是最表层的一页之后就直接回调下一次的运行了,但是如果我们的信息还没有处理完成怎么办?需要更多的request和response处理
该怎么操作呢?总不能再引入使用requests库吧?
解决方案:
我在爬取某个壁纸网站的时候遇到了这个问题,首页只得到了各个图片的略缩图,而原图地址需要点开另外的html文件才能获得
解决代码如下:
# -*- coding: utf-8 -*-
import scrapy
from wallpaper.items import WallpaperItem class WallspiderSpider(scrapy.Spider):
name = 'wallspider'
allowed_domains = ['wall.alphacoders.com']
start_urls = ['https://wall.alphacoders.com/'] def parse(self, response):
picx_list = response.xpath("//div[@class='center']//div[@class='boxgrid']/a/@href").getall() for picx in picx_list:
url = 'https://wall.alphacoders.com/'+str(picx)
#回调给下一层处理函数
yield scrapy.Request(url,callback=self.detail_parse) def detail_parse(self, response):
pic_url = response.xpath("//*[@id='page_container']/div[4]/a/@href").get()
pic_size = response.xpath("//*[@id='wallpaper_info_table']/tbody//span/span[2]/a/text()").get()
pic_name = response.xpath("//*[@id='page_container']/div/a[4]/span/text()").get()
wall_item = WallpaperItem()
wall_item['pic_url'] = pic_url
wall_item['pic_size'] = pic_size.split()[0]
wall_item['pic_name'] = pic_name
print(wall_item)
return wall_item
同时我在csdn中看到 名为 kocor的用户写的解决方案则更有教学性,解决方案如下:
yield scrapy.Request(item['url'], meta={'item': item}, callback=self.detail_parse)
Scrapy 用scrapy.Request发起请求可以带上 meta={'item': item} 把之前已收集到的信息传递到新请求里,在新请求里用 item = response.meta('item') 接受过来,在 item 就可以继续添加新的收集的信息了。
多少级的请求的数据都可以收集。
spider.py文件
# -*- coding: utf-8 -*-
import scrapy
from Tencent.items import TencentItem class TencentSpider(scrapy.Spider):
# 爬虫名称
name = 'tencent'
# 允许爬取的域名
allowed_domains = ['www.xxx.com']
# 爬虫基础地址 用于爬虫域名的拼接
base_url = 'https://www.xxx.com/'
# 爬虫入口爬取地址
start_urls = ['https://www.xxx.com/position.php']
# 爬虫爬取页数控制初始值
count = 1
# 爬虫爬取页数 10为只爬取一页
page_end = 1 def parse(self, response): nodeList = response.xpath("//table[@class='tablelist']/tr[@class='odd'] | //table[@class='tablelist']/tr[@class='even']")
for node in nodeList:
item = TencentItem() item['title'] = node.xpath("./td[1]/a/text()").extract()[0]
if len(node.xpath("./td[2]/text()")):
item['position'] = node.xpath("./td[2]/text()").extract()[0]
else:
item['position'] = ''
item['num'] = node.xpath("./td[3]/text()").extract()[0]
item['address'] = node.xpath("./td[4]/text()").extract()[0]
item['time'] = node.xpath("./td[5]/text()").extract()[0]
item['url'] = self.base_url + node.xpath("./td[1]/a/@href").extract()[0]
# 根据内页地址爬取
yield scrapy.Request(item['url'], meta={'item': item}, callback=self.detail_parse) # 有下级页面爬取 注释掉数据返回
# yield item # 循环爬取翻页
nextPage = response.xpath("//a[@id='next']/@href").extract()[0]
# 爬取页数控制及末页控制
if self.count < self.page_end and nextPage != 'javascript:;':
if nextPage is not None:
# 爬取页数控制值自增
self.count = self.count + 1
# 翻页请求
yield scrapy.Request(self.base_url + nextPage, callback=self.parse)
else:
# 爬虫结束
return None def detail_parse(self, response):
# 接收上级已爬取的数据
item = response.meta['item'] #一级内页数据提取
item['zhize'] = response.xpath("//*[@id='position_detail']/div/table/tr[3]/td/ul[1]").xpath('string(.)').extract()[0]
item['yaoqiu'] = response.xpath("//*[@id='position_detail']/div/table/tr[4]/td/ul[1]").xpath('string(.)').extract()[0] # 二级内页地址爬取
yield scrapy.Request(item['url'] + "&123", meta={'item': item}, callback=self.detail_parse2) # 有下级页面爬取 注释掉数据返回
# return item def detail_parse2(self, response):
# 接收上级已爬取的数据
item = response.meta['item'] # 二级内页数据提取
item['test'] = "" # 最终返回数据给爬虫引擎
return item
他的文章地址:https://blog.csdn.net/ygc123189/article/details/79160146
Scrapy各部分运行机制?Xpath为None?多层Response如何编写?搞定Scrapy的坑的更多相关文章
- Scrapy(爬虫)基本运行机制
Scrapy(爬虫)基本运行机制
- 一文搞定scrapy爬取众多知名技术博客文章保存到本地数据库,包含:cnblog、csdn、51cto、itpub、jobbole、oschina等
本文旨在通过爬取一系列博客网站技术文章的实践,介绍一下scrapy这个python语言中强大的整站爬虫框架的使用.各位童鞋可不要用来干坏事哦,这些技术博客平台也是为了让我们大家更方便的交流.学习.提高 ...
- Scrapy分布式爬虫,分布式队列和布隆过滤器,一分钟搞定?
使用Scrapy开发一个分布式爬虫?你知道最快的方法是什么吗?一分钟真的能 开发好或者修改出 一个分布式爬虫吗? 话不多说,先让我们看看怎么实践,再详细聊聊细节~ 快速上手 Step 0: 首先安装 ...
- JAVA运行机制
这一篇我们来简单理解一下JAVA的运行机制 大概可以分为三大部分 1.编写程序 2.编译程序 3.运行程序 1.编写程序 编写程序就是我们前面说的源代码 这些源代码都有特殊的语法 例如main函数 他 ...
- python的scrapy框架的使用 和xpath的使用 && scrapy中request和response的函数参数 && parse()函数运行机制
这篇博客主要是讲一下scrapy框架的使用,对于糗事百科爬取数据并未去专门处理 最后爬取的数据保存为json格式 一.先说一下pyharm怎么去看一些函数在源码中的代码实现 按着ctrl然后点击函数就 ...
- Stream01 定义、迭代、操作、惰性求值、创建流、并行流、收集器、stream运行机制
1 Stream Stream 是 Java 8 提供的一系列对可迭代元素处理的优化方案,使用 Stream 可以大大减少代码量,提高代码的可读性并且使代码更易并行. 2 迭代 2.1 需求 随机创建 ...
- 关于Scrapy爬虫项目运行和调试的小技巧(下篇)
前几天给大家分享了关于Scrapy爬虫项目运行和调试的小技巧上篇,没来得及上车的小伙伴可以戳超链接看一下.今天小编继续沿着上篇的思路往下延伸,给大家分享更为实用的Scrapy项目调试技巧. 三.设置网 ...
- (十三)Maven插件解析运行机制
这里给大家详细说一下Maven的运行机制,让大家不仅知其然,更知其所以然. 1.插件保存在哪里? 与我们所依赖的构件一样,插件也是基于坐标保存在我们的Maven仓库当中的.在用到插件的时候会先从本地仓 ...
- 深入理解JavaScript运行机制
深入理解JavaScript运行机制 前言 本文是写作在给团队新人培训之际,所以其实本文的受众是对JavaScript的运行机制不了解或了解起来有困难的小伙伴.也就是说,其实真正的原理和本文阐述的并不 ...
随机推荐
- java设计模式学习-单例模式
java中单例模式定义:“一个类有且仅有一个实例,并且自行实例化向整个系统提供.”单例模式可以保证一个应用中有且只有一个实例,避免了资源的浪费和多个实例多次调用导致出错. 单例模式有以下特点: 1.单 ...
- Solr 集成ikanalyzer
Solr 不能对中文进行分词,ikanalyzer可以. ikanalyzer下载链接 1.下载 jar形式 2.放到D:\soft\solr-8.1.0\server\solr-webapp\web ...
- Python网络爬虫学习手记(1)——爬虫基础
1.爬虫基本概念 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.--------百度百科 简单的说,爬 ...
- JMeter-因cookie管理器不兼容返回H5内容内容的解决
问题: 使用的post方法但是显示的是get,并且返回页面H5的内容 解决: jmeter版本太低了,需要选择cookie管理期选择兼容模式(一般默认的为standard)
- 小数组的读写和带Buffer的读写哪个快
定义小数组如果是8192个字节大小和Buffered比较的话 定义小数组会略胜一筹,因为读和写操作的是同一个数组 而Buffered操作的是两个数组
- ISO/IEC 9899:2011 条款6.4.5——字符串字面量
6.4.5 字符串字面量 语法 1.string-literal: encoding-prefixopt " s-char-sequenceopt " encoding- ...
- Linux -- 信号编程
进程捕捉到信号对其进行处理时,进程正在执行的正常序列就被信号处理程序临时中断,它首先执行该信号处理程序中的指令.如果从信号处理程序返回(例如没有调用exit或longjmp),则继续执行在捕捉到信号时 ...
- Mysql字段修饰符(约束)
(1).null和not null not null不可以插入null,但可以插入空值. 数值型.字符型.日期型都可以插入null,但只有字符型可以插入空值. 使用方法如下: mysql> cr ...
- kubenetes安装
master节点主要由四个模块组成: APIServer 提供了资源操作的唯一入口,任何对资源进行增删改查的操作都要交给APIServer处理后再提交给etcd.kubectl就是对api ser ...
- 02.提交bug
写代码最烦的也就是修复bug了,虽然这个避无可避…………………… a. bug的严重级别设置 1级:影响主要流程 ->在bug 的影响下,主流程 测试无法向下进行 2级:影响核心功能 -> ...