基于语法树和概率的AI模型
语法树是句子结构的图形表示,它代表了句子的推导结果,有利于理解句子语法结构的层次。简单说,语法树就是按照某一规则进行推导时所形成的树。
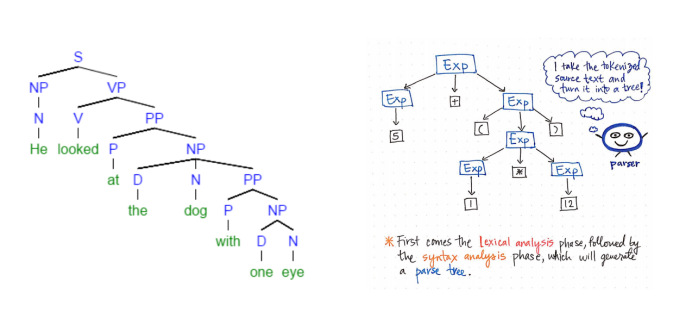
有了语法树,我们就可以根据其规则自动生成语句,但是语法树本身是死的,在日常生活中我们会有很多并不符合语法树的情况,比如:

我们转换一种思想,我不在意一句话对与不对,而是判断这句话出现概率的高低,如果一句话出现的最终概率越接近1,那么说明它越容易出现,反之亦然。这里我们就需要语言模型:N-gram,该模型基于这样一种假设,第N个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。

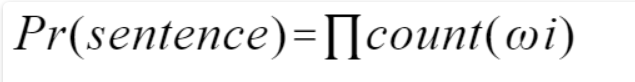
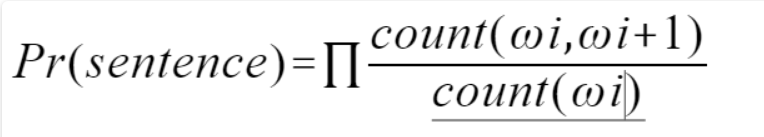
我们可以看出其实1-gram模型就是个词汇单独出现的概率累乘,与我们的初衷不符合,相反N值越大,其实模型应该越好,不过由于计算量的缘故,实际中我们常用的是2-gram(Bi-Gram)与3-gram(Tri-Gram),当N>=4时,实在是太慢了。
2-gram:需要统计句子中词汇与前一词汇同时出现的次数,最后累乘
3-gram:需要统计句子中词汇与前两词汇同时出现的次数,最后累乘
BaseDir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
file_path = f"{BaseDir}/day1/data/article_9k.txt"
with open(file_path, 'r', encoding='utf-8') as f:
FILE = f.read()
def cut(string):
return list(jieba.cut(string))
TOKENS = cut(FILE[:1000000])
words_count = Counter(TOKENS)
_2_gram_words = [
TOKENS[i] + TOKENS[i+1] for i in range(len(TOKENS)-1)
]
_2_gram_word_counts = Counter(_2_gram_words)
def get_gram_count(word, wc):
"""
获取字符串在总字符表中的次数
:param word: 需要查询的字符串
:param wc: 总字符表
:return: 该字符串出现的次数,如没有则定为出现最少次数字符串的次数
"""
return wc[word] if word in wc else wc.most_common()[-1][-1]
def two_gram_model(sentence):
"""
分别计算句子中该单词在总字符表中出现的次数
该单词跟后一单词在二连总字符表中出现的次数
做比后的连续乘积
:param sentence: 需要验证的句子
:return:
"""
tokens = cut(sentence)
probability = 1
for i in range(len(tokens)-1):
word = tokens[i]
next_word = tokens[i+1]
_two_gram_c = get_gram_count(word + next_word, _2_gram_word_counts)
_one_gram_c = get_gram_count(next_word, words_count)
pro = _two_gram_c / _one_gram_c
probability *= pro
return probability
r = two_gram_model("这个花特别好看")
print(r)
r = two_gram_model("花这个特别好看")
print(r)
r = two_gram_model("自然语言处理")
print(r)
r = two_gram_model("处语言理自然")
print(r)
r = two_gram_model("前天早上")
print(r)
1.7475796022508822e-05
9.342406678699686e-07
0.030927835051546393
0.00018491124260355032
0.02857142857142857
从得出的结果我们就可以判断出这个句子出现的概率是多少了,当然N-gram模型的结果是受原始词袋影响的。
基于语法树和概率的AI模型的更多相关文章
- 炸金花游戏(3)--基于EV(期望收益)的简单AI模型
前言: 炸金花这款游戏, 从技术的角度来说, 比德州差了很多. 所以他的AI模型也相对简单一些. 本文从EV(期望收益)的角度, 来尝试构建一个简单的炸金花AI. 相关文章: 德州扑克AI--Prog ...
- 基于Tire树和最大概率法的中文分词功能的Java实现
对于分词系统的实现来说,主要应集中在两方面的考虑上:一是对语料库的组织,二是分词策略的制订. 1. Tire树 Tire树,即字典树,是通过字串的公共前缀来对字串进行统计.排序及存储的一种树形结构 ...
- 基于行为树的AI 与 Behavior Designer插件
优点: 0.行为逻辑和状态数据分离,任何节点都可以反复利用. 1.高度模块化状态,去掉状态中的跳转逻辑,使得状态变成一个"行为". 2."行为" ...
- Microsoft宣布为Power BI提供AI模型构建器,关键驱动程序分析和Azure机器学习集成
微软的Power BI现在是一种正在大量结合人工智能(AI)的商业分析服务,它使用户无需编码经验或深厚的技术专长就能够创建报告,仪表板等.近日西雅图公司宣布推出几款新的AI功能,包括图像识别和文本分析 ...
- Atitit.sql ast 表达式 语法树 语法 解析原理与实现 java php c#.net js python
Atitit.sql ast 表达式 语法树 语法 解析原理与实现 java php c#.net js python 1.1. Sql语法树 ast 如下图锁死1 2. SQL语句解析的思路和过程3 ...
- 最强云硬盘来了,让AI模型迭代从1周缩短到1天
摘要:华为云擎天架构+ Flash-Native存储引擎+低时延CurreNET,数据存储和处理还有啥担心的? 虽然我们已经进入大数据时代,但多数企业数据利用率只有10%,数据的价值没有得到充分释放. ...
- 如何借助 JuiceFS 为 AI 模型训练提速 7 倍
背景 海量且优质的数据集是一个好的 AI 模型的基石之一,如何存储.管理这些数据集,以及在模型训练时提升 I/O 效率一直都是 AI 平台工程师和算法科学家特别关注的事情.不论是单机训练还是分布式训练 ...
- CANN5.0黑科技解密 | 别眨眼!缩小隧道,让你的AI模型“身轻如燕”!
摘要:CANN作为释放昇腾硬件算力的关键平台,通过深耕先进的模型压缩技术,聚力打造AMCT模型压缩工具,在保证模型精度前提下,不遗余力地降低模型的存储空间和计算量. 随着深度学习的发展,推理模型巨大的 ...
- 二手车价格预测 | 构建AI模型并部署Web应用 ⛵
作者:韩信子@ShowMeAI 数据分析实战系列:https://www.showmeai.tech/tutorials/40 机器学习实战系列:https://www.showmeai.tech/t ...
随机推荐
- django post 403
同一个地址GET方式可以正常访问 在POST 提交数据过程中报403错误, 原来是1.3版本settings.py 文件中 'django.middleware.csrf.CsrfViewMiddle ...
- redis安装与介绍
安装 一般推荐次新版的最后一个发行版.https://redis.io/download 先安装gcc, yum install gcc tar xzf redis-3.2.3.tar.gz cd r ...
- 如何在vue-cli 3.x中使用jquery
由于项目需求要使用jquery,结果各种引用都不济于事. 最后在网上找到了答案,现把它记录一下,给有需要者. 首先下载 jquery. cnpm install jquery --save-dev 方 ...
- Android:Recents和AMS中历史任务的区别
1.1 任务和返回栈 - 实际数据模型 这个是指在调度体系里实际保存的TaskRecord实例,而ActivityRecord-TaskRecord-ActivityStack之间的关系建议看官方文 ...
- Ionic4.x 项目结构简单分析
新建项目 e2e:端对端测试文件 node_modules :项目所需要的依赖包 resources :android/ios 资源(更换图标和启动动画) src:开发工作目录,页面.样式.脚本和图片 ...
- angular绑定数据
Angular 中使用{{}}绑定业务逻辑里面定义的数据 <h1> Welcome to {{ title }}! /*引入title*/ </h1> export class ...
- angular自定义组件
https://cli.angular.io/ 打开终端创建header组件: ng g component components/header import { Component, OnInit ...
- 【转载】 迁移学习与fine-tuning有什么区别
原文地址: https://www.cnblogs.com/fangpengchengbupter/p/8276204.html ----------------------------------- ...
- sql数据库为null时候ASP语句判断问题
我有一个表test1,有字段num,字段num有null值,也有空值,也有其他值,我要用asp语句判断我查询出来的num的值是否为null值.应该怎么写 严谨一点,要有两层判断: If IsNull( ...
- 【Leetcode_easy】788. Rotated Digits
problem 788. Rotated Digits solution1: class Solution { public: int rotatedDigits(int N) { ; ; i< ...