spark基础知识四
围绕spark的其他特性和应用。主要包括以下几个方面
spark自定义分区
spark中的共享变量
spark程序的序列化问题
spark中的application/job/stage/task之间的关系
spark on yarn原理和机制
spark的资源分配方式
1. spark自定义分区
1.1 自定义分区说明
在对RDD数据进行分区时,默认使用的是HashPartitioner
该函数对key进行哈希,然后对分区总数取模,取模结果相同的就会被分到同一个partition中
HashPartitioner分区逻辑:
key.hashcode % 分区总数 = 分区号如果嫌HashPartitioner功能单一,可以自定义partitioner
1.2 自定义partitioner
实现自定义partitioner大致分为3个步骤
1、继承org.apache.spark.Partitioner
2、重写numPartitions方法
3、重写getPartition方法
1.3 案例实战
需求
后期要想根据rdd的key的长度进行分区,相同key的长度进入到同一个分区中
代码开发
TestPartitionerMain 主类
package com.lowi.partitioner
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
//todo:使用自己实现的自定义分区
object TestPartitionerMain {
def main(args: Array[String]): Unit = {
//1、构建SparkConf
val sparkConf: SparkConf = new SparkConf().setAppName("TestPartitionerMain").setMaster("local[2]")
//2、构建SparkContext
val sc = new SparkContext(sparkConf)
sc.setLogLevel("warn")
//3、构建数据源
val data: RDD[String] = sc.parallelize(List("hadoop","hdfs","hive","spark","flume","kafka","flink","azkaban"))
//4、获取每一个元素的长度,封装成一个元组
val wordLengthRDD: RDD[(String, Int)] = data.map(x=>(x,x.length))
//5、对应上面的rdd数据进行自定义分区
val result: RDD[(String, Int)] = wordLengthRDD.partitionBy(new MyPartitioner(3))
//6、保存结果数据到文件
result.saveAsTextFile("./data")
sc.stop()
}
}自定义分区MyPartitioner
package com.kaikeba.partitioner
import org.apache.spark.Partitioner
//自定义分区
class MyPartitioner(num:Int) extends Partitioner{
//指定rdd的总的分区数
override def numPartitions: Int = {
num
}
//消息按照key的某种规则进入到指定的分区号中
override def getPartition(key: Any): Int ={
//这里的key就是单词
val length: Int = key.toString.length
length match {
case 4 =>0
case 5 =>1
case 6 =>2
case _ =>0
}
}
}
2. spark的共享变量
2.1 spark的广播变量(broadcast variable)
Spark中分布式执行的代码需要传递到各个Executor的Task上运行。对于一些只读、固定的数据(比如从DB中读出的数据),每次都需要Driver广播到各个Task上,这样效率低下。
广播变量允许将变量只广播给各个Executor。该Executor上的各个Task再从所在节点的BlockManager获取变量,而不是从Driver获取变量,以减少通信的成本,减少内存的占用,从而提升了效率。
2.1.1 广播变量原理

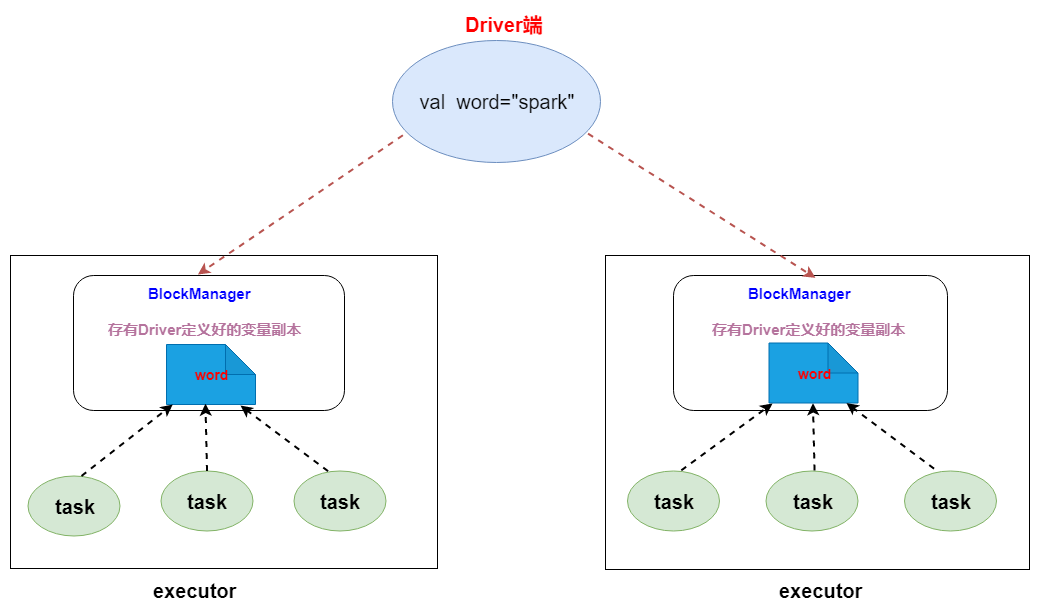
2.1.2 广播变量使用
(1) 通过对一个类型T的对象调用 SparkContext.broadcast创建出一个Broadcast[T]对象。
任何可序列化的类型都可以这么实现
(2) 通过 value 属性访问该对象的值
(3) 变量只会被发到各个节点一次,应作为只读值处理(修改这个值不会影响到别的节点)
不使用广播变量代码示例
val conf = new SparkConf().setMaster("local[2]").setAppName("brocast")
val rdd1=sc.textFile("/words.txt")
val word="spark"
val rdd2=rdd1.flatMap(_.split(" ")).filter(x=>x.equals(word))
rdd2.foreach(x=>println(x))
//这里的word单词为在每一个task中进行传输
使用广播变量代码示例
val conf = new SparkConf().setMaster("local[2]").setAppName("brocast")
val sc=new SparkContext(conf)
val rdd1=sc.textFile("/words.txt")
val word="spark"
//通过调用sparkContext对象的broadcast方法把数据广播出去
val broadCast = sc.broadcast(word)
//在executor中通过调用广播变量的value属性获取广播变量的值
val rdd2=rdd1.flatMap(_.split(" ")).filter(x=>x.equals(broadCast.value))
rdd2.foreach(x=>println(x))
2.1.3 广播变量使用注意事项
1、不能将一个RDD使用广播变量广播出去
2、广播变量只能在Driver端定义,不能在Executor端定义
3、在Driver端可以修改广播变量的值,在Executor端无法修改广播变量的值
4、如果executor端用到了Driver的变量,如果不使用广播变量在Executor有多少task就有多少Driver端的变量副本
5、如果Executor端用到了Driver的变量,如果使用广播变量在每个Executor中只有一份Driver端的变量副本
2.2 spark的累加器(accumulator)
累加器(accumulator)是Spark中提供的一种分布式的变量机制,其原理类似于mapreduce,即分布式的改变,然后聚合这些改变。
累加器的一个常见用途是在调试时对作业执行过程中的事件进行计数。可以使用累加器来进行全局的计数。
2.2.1 累加器原理
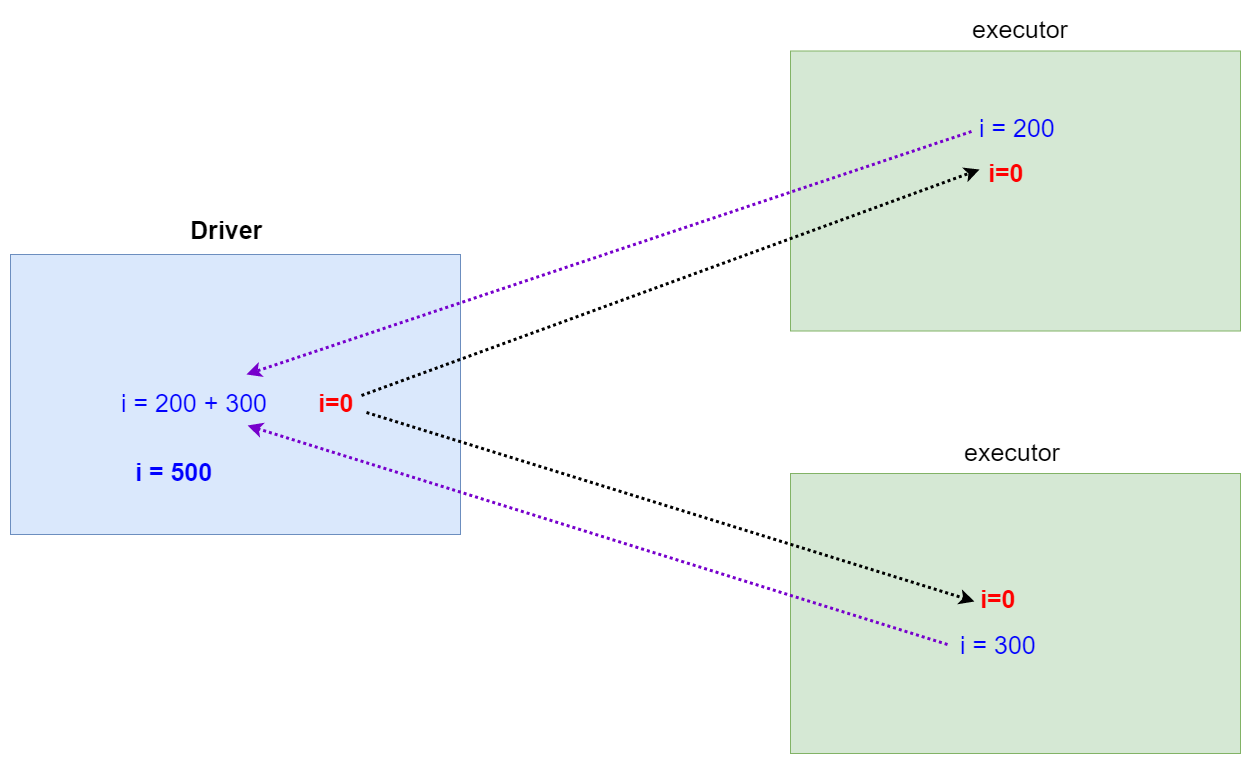

2.2.2 累加器使用
(1) 通过在driver中调用 SparkContext.accumulator(initialValue) 方法,创建出存有初始值的累加器。返回值为 org.apache.spark.Accumulator[T] 对象,其中 T 是初始值initialValue 的类型。
(2) spark闭包(函数序列化)里的excutor代码可以使用累加器的 add 方法增加累加器的值。
(3) driver程序可以调用累加器的 value 属性来访问累加器的值。
代码
object AccumulatorTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("accumulator")
val sc = new SparkContext(conf)
//创建accumulator并初始化为0
val accumulator = sc.accumulator(0);
//读取一个有10条记录的文件
val linesRDD = sc.textFile("/words.txt")
val result = linesRDD.map(s => {
accumulator.add(1) //有一条数据就增加1
s
})
result.collect(); //触发action操作
println("words lines is :" + accumulator.value)
sc.stop()
}
}
//输出结果: words lines is : 10
3. spark程序的序列化问题
3.1 transformation操作为什么需要序列化
spark是分布式执行引擎,其核心抽象是弹性分布式数据集RDD,其代表了分布在不同节点的数据。Spark的计算是在executor上分布式执行的,故用户开发的关于RDD的map,flatMap,reduceByKey等transformation 操作(闭包)有如下执行过程:
(1)代码中对象在driver本地序列化
(2)对象序列化后传输到远程executor节点
(3)远程executor节点反序列化对象
(4)最终远程节点执行
故对象在执行中需要序列化通过网络传输,则必须经过序列化过程。
3.2 spark的任务序列化异常
在编写spark程序中,由于在map,foreachPartition等算子内部使用了外部定义的变量和函数,从而引发Task未序列化问题。
然而spark算子在计算过程中使用外部变量在许多情形下确实在所难免,比如在filter算子根据外部指定的条件进行过滤,map根据相应的配置进行变换。
经常会出现“org.apache.spark.SparkException: Task not serializable”这个错误
其原因就在于这些算子使用了外部的变量,但是这个变量不能序列化。
当前类使用了“extends Serializable”声明支持序列化,但是由于某些字段不支持序列化,仍然会导致整个类序列化时出现问题,最终导致出现Task未序列化问题。

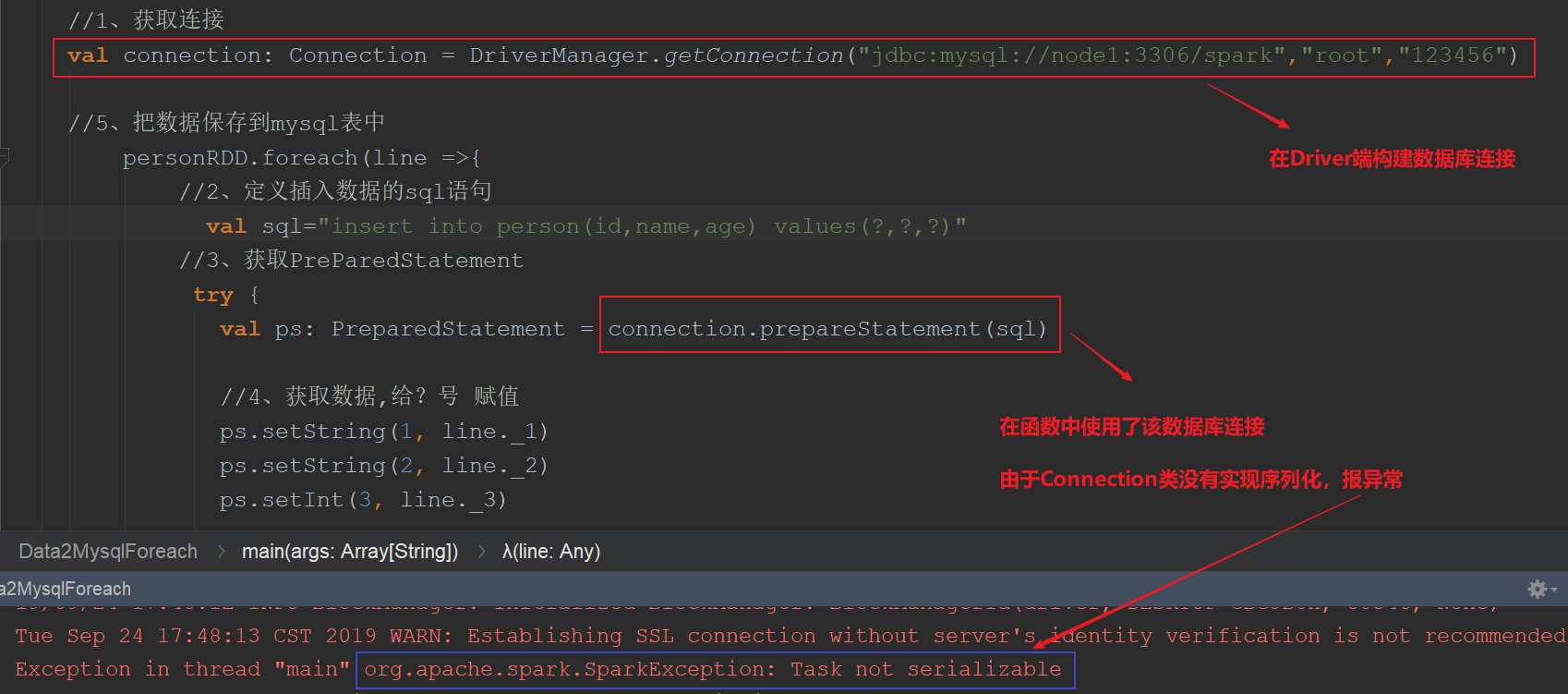

3.3 spark中解决序列化的办法
(1) 如果函数中使用了该类对象,该类要实现序列化
类 extends Serializable
(2) 如果函数中使用了该类对象的成员变量,该类除了要实现序列化之外,所有的成员变量必须要实现序列化
(3) 对于不能序列化的成员变量使用“@transient”标注,告诉编译器不需要序列化
(4) 也可将依赖的变量独立放到一个小的class中,让这个class支持序列化,这样做可以减少网络传输量,提高效率。
(5) 可以把对象的创建直接在该函数中构建这样避免需要序列化
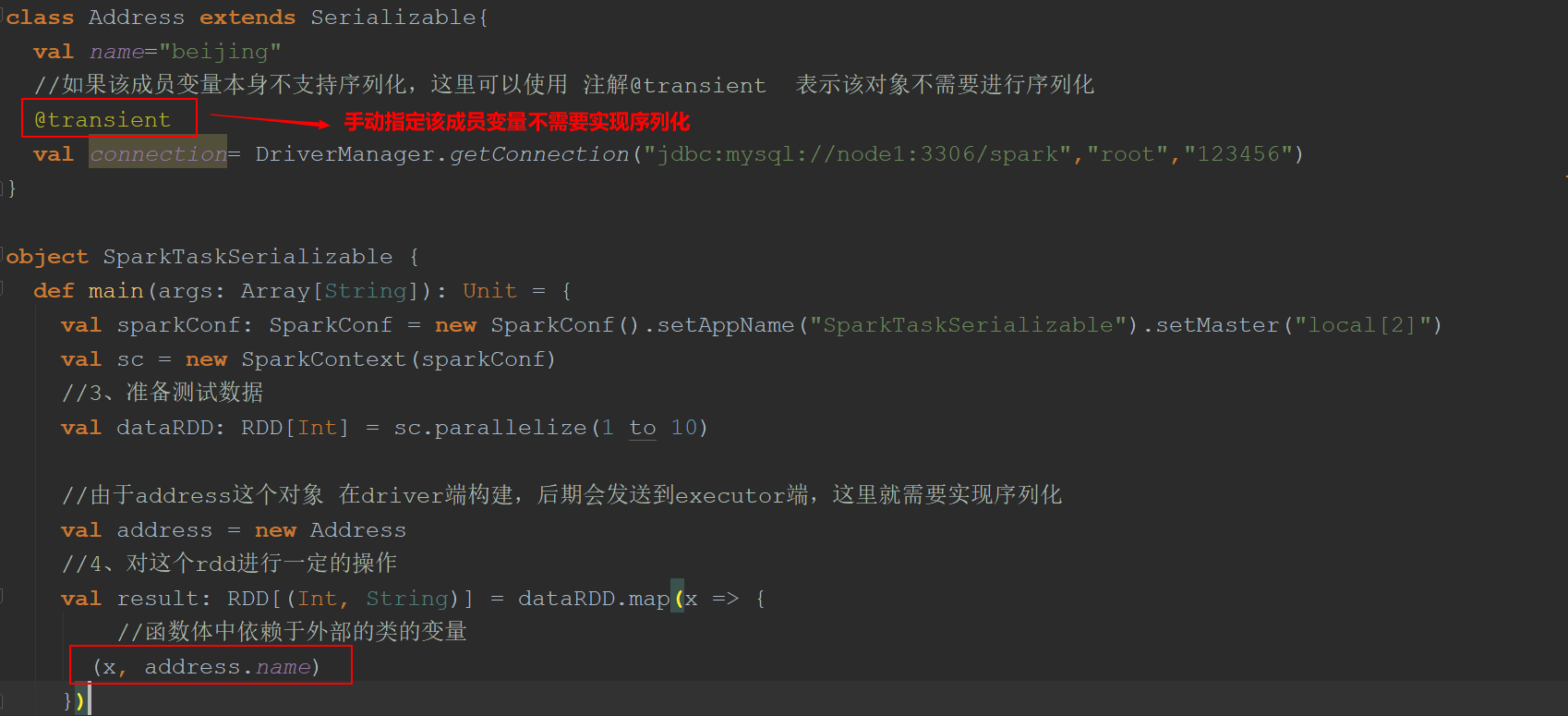

4. application、job、stage、task之间的关系
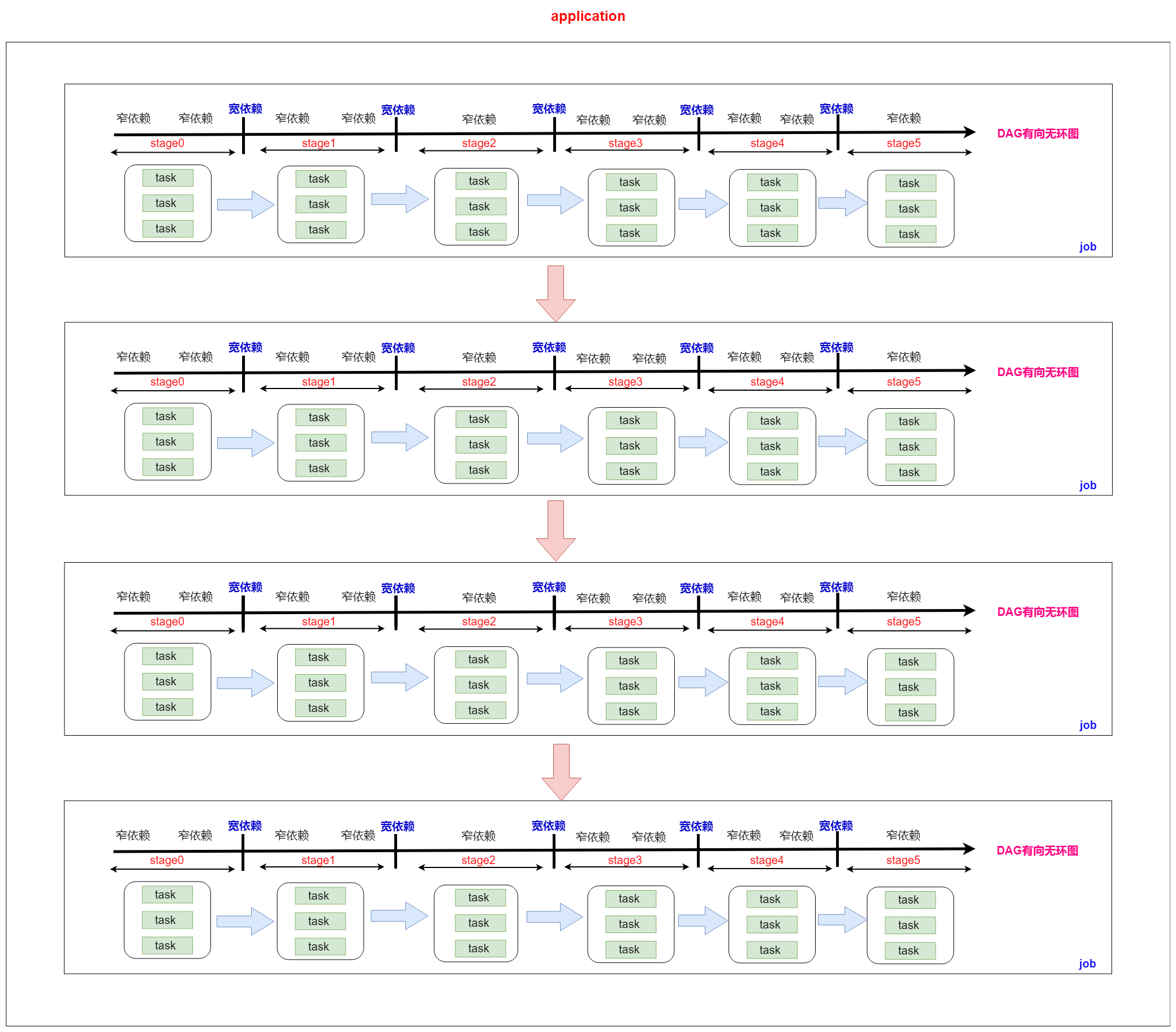

一个application就是一个应用程序,包含了客户端所有的代码和计算资源
一个action操作对应一个DAG有向无环图,即一个action操作就是一个job
一个job中包含了大量的宽依赖,按照宽依赖进行stage划分,一个job产生了很多个stage
一个stage中有很多分区,一个分区就是一个task,即一个stage中有很多个task
总结
一个application包含了很多个job
一个job包含了很多个stage
一个stage包含了很多个task
5. spark on yarn
可以把spark程序提交到yarn中去运行,此时spark任务所需要的计算资源由yarn中的老大ResourceManager去分配
官网资料地址
环境准备
1、安装hadoop集群
2、安装spark环境
注意这里不需要安装spark集群
只需要解压spark安装包到任意一台服务器
修改文件 spark-env.sh
export JAVA_HOME=/opt/bigdata/jdk
export HADOOP_CONF_DIR=/opt/bigdata/hadoop/etc/hadoop
按照Spark应用程序中的driver分布方式不同,Spark on YARN有两种模式:
yarn-client模式、yarn-cluster模式。- yarn web ui界面:主机名:18088 (由yarn-site.xml中配置,yarn.resourcemanager.webapp.address) ----》很多人配置的是8088
5.1 yarn-cluster模式
yarn-cluster模式下提交任务示例 (当任务在shell中提交后,即使退出命令,任务依旧在执行)
spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--driver-memory 1g \
--executor-memory 1g \
--executor-cores 1 \
/opt/bigdata/spark/examples/jars/spark-examples_2.11-2.3.3.jar \
10
如果运行出现错误,可能是虚拟内存不足,可以添加参数
vim yarn-site.xml
<!--容器是否会执行物理内存限制默认为True-->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--容器是否会执行虚拟内存限制 默认为True-->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
5.2 yarn-client模式
yarn-client模式下提交任务示例 (当任务在shell中提交后,即使退出命令,任务将不会再执行,即:停止)
spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
--driver-memory 1g \
--executor-memory 1g \
--executor-cores 1 \
/opt/bigdata/spark/examples/jars/spark-examples_2.11-2.3.3.jar \
10
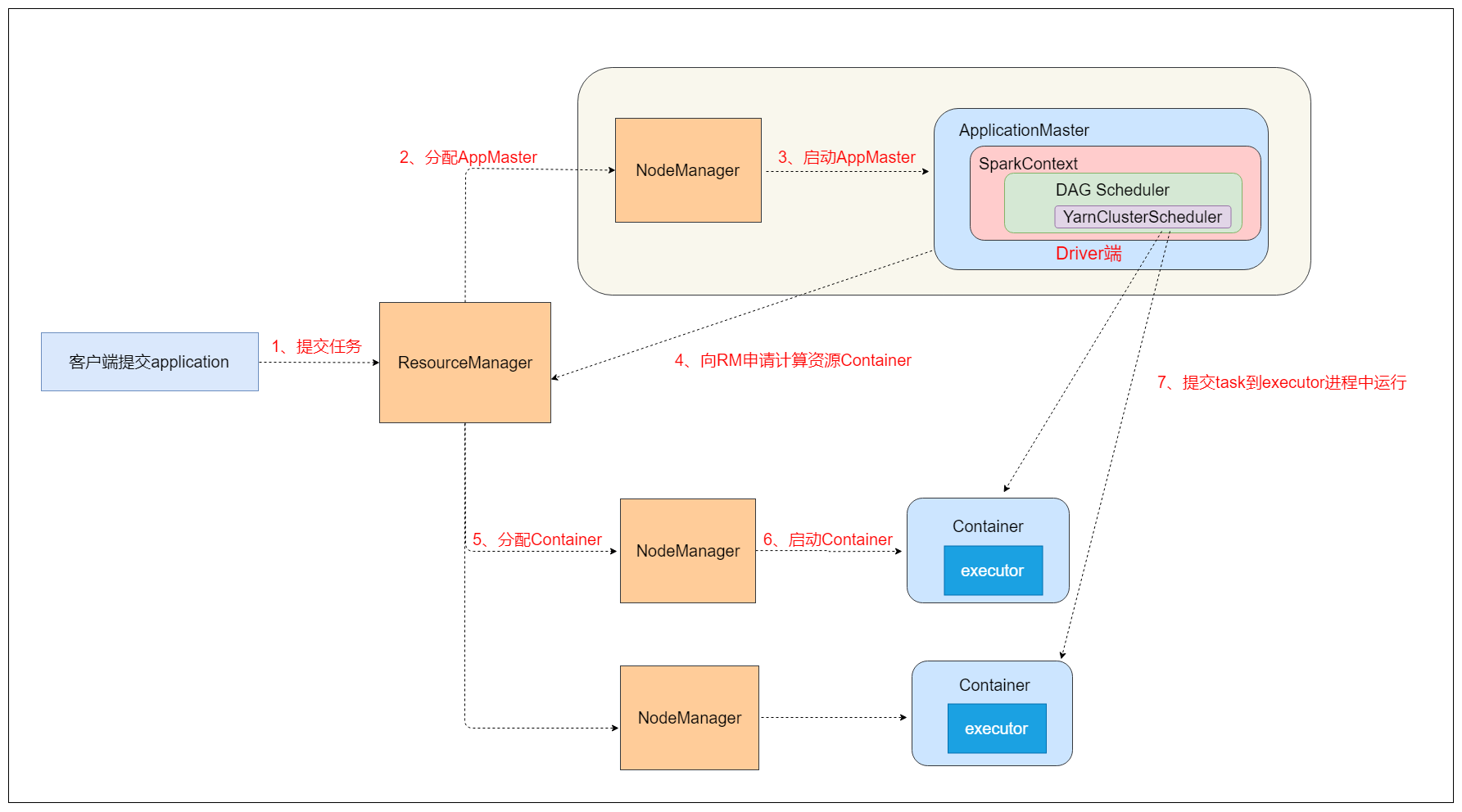
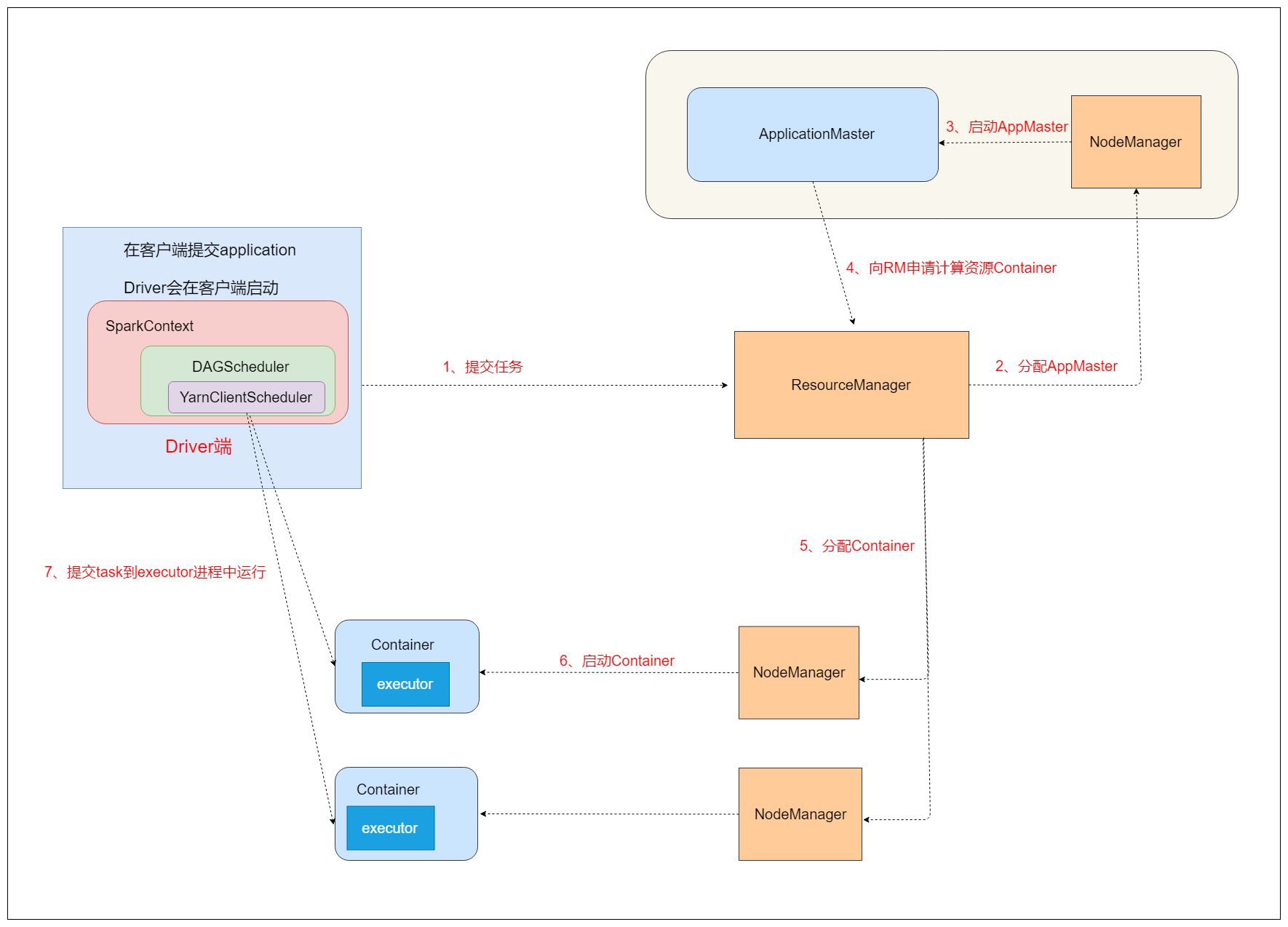
5.3 两种模式的原理
yarn-cluster模式

yarn-client模式

5.4 两种模式的区别
yarn-cluster模式
spark程序的Driver程序在YARN中运行,运行结果不能在客户端显示,并且客户端可以在启动应用程序后消失应用的。
最好运行那些将结果最终保存在外部存储介质(如HDFS、Redis、Mysql),客户端的终端显示的仅是作为YARN的job的简单运行状况。
yarn-client模式
spark程序的Driver运行在Client上,应用程序运行结果会在客户端显示,所有适合运行结果有输出的应用程序(如spark-shell)
总结
最大的区别就是Driver端的位置不一样。
yarn-cluster: Driver端运行在yarn集群中,与ApplicationMaster进程在一起。
yarn-client: Driver端运行在提交任务的客户端,与ApplicationMaster进程没关系,经常 用于进行测试
6. collect 算子操作剖析
collect算子操作的作用
1、它是一个action操作,会触发任务的运行
2、它会把RDD的数据进行收集之后,以数组的形式返回给Driver端
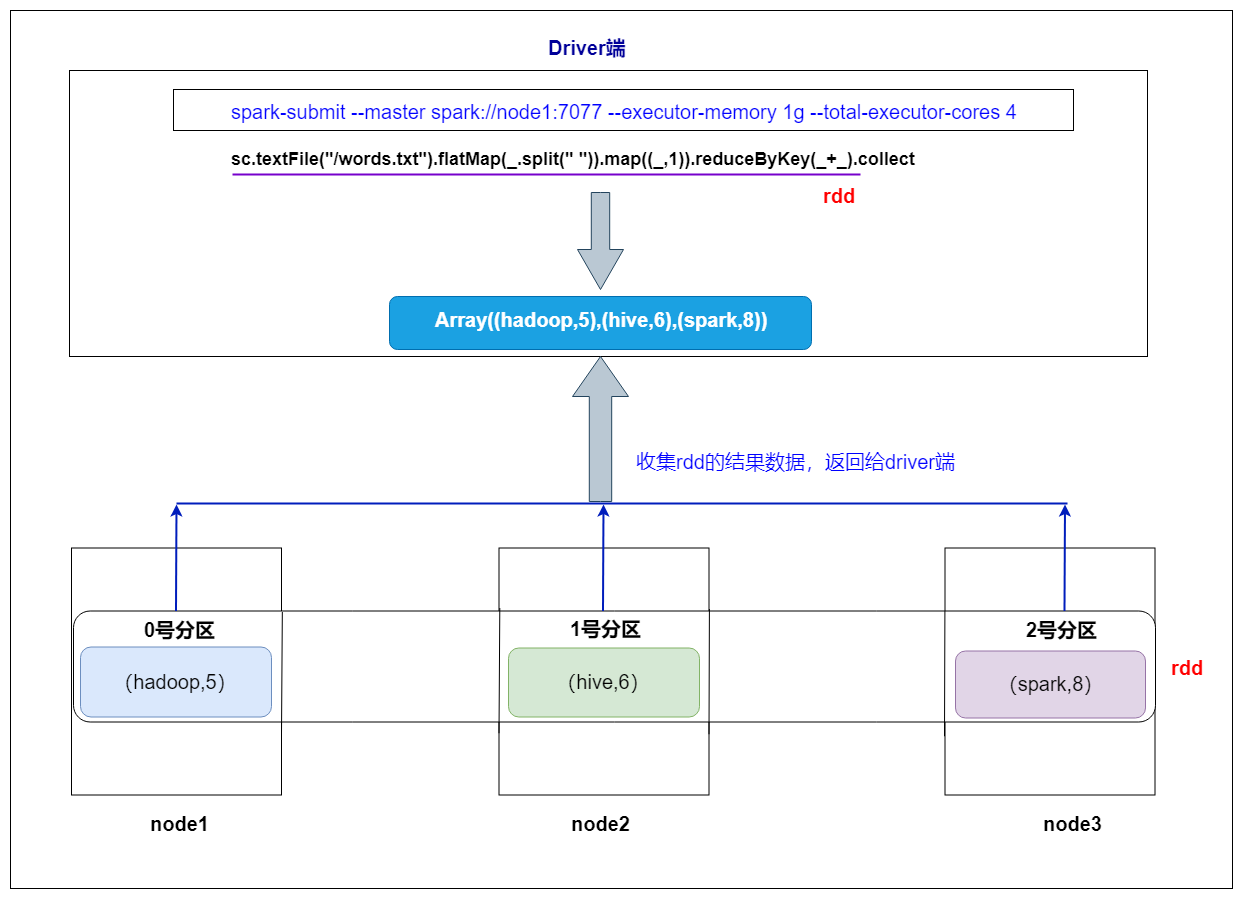

总结:
默认Driver端的内存大小为1G,由参数 spark.driver.memory 设置
如果某个rdd的数据量超过了Driver端默认的1G内存,对rdd调用collect操作,这里会出现Driver端的内存溢出,所有这个collect操作存在一定的风险,实际开发代码一般不会使用。
实际企业中一般都会把该参数调大,比如5G/10G等
可以在代码中修改该参数,如下
new SparkConf().set("spark.driver.memory","5G")
7. spark任务中资源参数剖析
通过开发工具开发好spark程序后达成jar包最后提交到集群中运行
提交任务脚本如下
spark-submit \
--master spark://node1:7077,node2:7077 \
--class com.kaikeba.WordCountOnSpark \
--executor-memory 1g \
--total-executor-cores 4 \
original-spark_class01-1.0-SNAPSHOT.jar \
/words.txt /out
--executor-memory
表示每一个executor进程需要的内存大小,它决定了后期操作数据的速度
--total-executor-cores
表示任务运行需要总的cpu核数,它决定了任务并行运行的粒度
总结
后期对于spark程序的优化,可以从这2个参数入手,无论你把哪一个参数调大,对程序运行的效率来说都会达到一定程度的提升
加大计算资源它是最直接、最有效果的优化手段。
在计算资源有限的情况下,可以考虑其他方面,比如说代码层面,JVM层面等
spark基础知识四的更多相关文章
- 最全的spark基础知识解答
原文:http://www.36dsj.com/archives/61155 一. Spark基础知识 1.Spark是什么? UCBerkeley AMPlab所开源的类HadoopMapReduc ...
- Python基础知识(四)
Python基础知识(四) 一丶列表 定义格式: 是一个容器,由 [ ]表示,元素与元素之间用逗号隔开. 如:name=["张三","李四"] 作用: 存储任意 ...
- C# 基础知识 (四).C#简单介绍及托管代码
暑假转瞬即逝,从10天的支教生活到1周的江浙沪旅游,在这个漫长的暑假中我经历了非常多东西,也学到了非常多东西,也认识到了非常多不足之处!闲暇之余我准备又一次进一步巩固C#相关知识,包含 ...
- C语言基础知识(四)——位操作
一.进制基础知识 1.通常,1字节(Byte)包含8位(bit).C语言用字节表示储存系统字符集所需的大小. 2.对于一个1字节8位的二进制数,最右边(第0位)是最低阶位,最左边(第1位)是最高阶位, ...
- spark基础知识(1)
一.大数据架构 并发计算: 并行计算: 很少会说并发计算,一般都是说并行计算,但是并行计算用的是并发技术.并发更偏向于底层.并发通常指的是单机上的并发运行,通过多线程来实现.而并行计算的范围更广,他是 ...
- spark基础知识
1.Spark是什么? UCBerkeley AMPlab所开源的类HadoopMapReduce的通用的并行计算框架. dfsSpark基于mapreduce算法实现的分布式计算,拥有HadoopM ...
- spark基础知识介绍2
dataframe以RDD为基础的分布式数据集,与RDD的区别是,带有Schema元数据,即DF所表示的二维表数据集的每一列带有名称和类型,好处:精简代码:提升执行效率:减少数据读取; 如果不配置sp ...
- spark基础知识介绍(包含foreachPartition写入mysql)
数据本地性 数据计算尽可能在数据所在的节点上运行,这样可以减少数据在网络上的传输,毕竟移动计算比移动数据代价小很多.进一步看,数据如果在运行节点的内存中,就能够进一步减少磁盘的I/O的传输.在spar ...
- spark基础知识一
1. spark是什么 Apache Spark™ is a unified analytics engine for large-scale data processing. spark是针对于大规 ...
随机推荐
- 027 奥展项目涉及的javascipt知识点笔记
1.获取指定div标签内的所有input标签 let inputs = document.getElementById("inspect-part1").getElementsBy ...
- j2ee的容器:web容器和ejb容器的概念
在J2EE中,容器充当的是中间件的角色. 两种主要容器的概念 Web容器 给处于其中的应用程序组件(JSP.Servlet)提供一个环境,使得JSP,Servlet能直接和容器中的环境变量.接口交互而 ...
- Linux : Nginx相关
nginx安装参考链接: https://www.cnblogs.com/kaid/p/7640723.html 自定义编译目录: https://blog.csdn.net/ainuser/arti ...
- 信安周报-第04周:系统函数与UDF
信安之路 第04周 前言 这周自主研究的任务如下: 附录解释: SQLi的时候应对各种限制,可以使用数据库自带的系统函数来进行一系列变换绕过验证 eg:字符串转换函数.截取字符串长度函数等 注入的时候 ...
- 还不错的PHP导出EXCEL函数挺好用的
直接上函数吧 //导出 $data内容二维数组 $title各个标题 $filename表名称 function exportexcelinfo($data=array(),$title=array( ...
- 【转】Redis 分布式锁的正确实现方式( Java 版 )
链接:wudashan.cn/2017/10/23/Redis-Distributed-Lock-Implement/ 前言 分布式锁一般有三种实现方式:1. 数据库乐观锁:2. 基于Redis的分布 ...
- 安装oracle时出现的问题
数据库引擎和几个功能安装失败后 ,重新再装还是一样,好不容易全部功能装完成后结果发现登录不了oracle!!!!!!!!!!!!! 气死人,搞了一上午才发现原来是微软账号在搞事,登录本地管理员账户就 ...
- Windows Server - Tomcat服务器下载、安装、配置环境变量教程
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/qq_40881680/articl ...
- Java程序员需要掌握的技能
转自:https://www.cnblogs.com/harry335/p/5924505.html
- Spring常用注解之一
Spring中的常用注解 @Component 把普通 pojo 实例化到 Spring 容器中,相当于配置文件中的 泛指各种组件,就是说当我们的类不属于各种归类的时候(不属于@Controller. ...