NIO原理详解
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
本文链接:https://blog.csdn.net/CharJay_Lin/article/details/81810922
文章目录
前言
1.阻塞与同步
2.BIO与NIO对比
3.NIO简介
4.缓冲区Buffer
5.通道Channel
6.反应堆
7.选择器
8.NIO源码分析
9.AIO
前言
该文是对NIO知识的归纳与整理
1.阻塞与同步
1)阻塞(Block)和非租塞(NonBlock):
阻塞和非阻塞是进程在访问数据的时候,数据是否准备就绪的一种处理方式,当数据没有准备的时候阻塞:往往需要等待缞冲区中的数据准备好过后才处理其他的事情,否則一直等待在那里。
非阻塞:当我们的进程访问我们的数据缓冲区的时候,如果数据没有准备好则直接返回,不会等待。如果数据已经准备好,也直接返回
2)同步(Synchronization)和异步(Async)的方式:
同步和异步都是基于应用程序私操作系统处理IO事件所采用的方式,比如同步:是应用程序要直接参与IO读写的操作。异步:所有的IO读写交给搡作系统去处理,应用程序只需要等待通知。
同步方式在处理IO事件的时候,必须阻塞在某个方法上靣等待我们的IO事件完成(阻塞IO事件或者通过轮询IO事件的方式).对于异步来说,所有的IO读写都交给了搡作系统。这个时候,我们可以去做其他的事情,并不拓要去完成真正的IO搡作,当搡作完成IO后.会给我们的应用程序一个通知
同步:阻塞到IO事件,阻塞到read成则write。这个时候我们就完全不能做自己的事情,让读写方法加入到线程里面,然后阻塞线程来实现,对线程的性能开销比较大,
参考:https://blog.csdn.net/CharJay_Lin/article/details/81259880
2.BIO与NIO对比
block IO与Non-block IO
1)区别
IO模型 IO NIO
方式 从硬盘到内存 从内存到硬盘
通信 面向流(乡村公路) 面向缓存(高速公路,多路复用技术)
处理 阻塞IO(多线程) 非阻塞IO(反应堆Reactor)
触发 无 选择器(轮询机制)
2)面向流与面向缓冲
Java NIO和IO之间第一个最大的区别是,IO是面向流的.NIO是面向缓冲区的。Java IO面向流意味着毎次从流中读一个成多个字节,直至读取所有字节,它们没有被缓存在任何地方,此外,它不能前后移动流中的数据。如果需要前后移动从流中读取的教据,需要先将它缓存到一个缓冲区。Java NIO的缓冲导向方法略有不同。数据读取到一个它稍后处理的缓冲区,霱要时可在缓冲区中前后移动。这就增加了处理过程中的灵活性。但是,还需要检查是否该缓冲区中包含所有您需要处理的数裾。而且,需确保当更多的数据读入缓冲区时,不要覆盖缓冲区里尚未处理的数据。
3)阻塞与非阻塞
Java IO的各种流是阻塞的。这意味着,当一个线程调用read() 或 write()时,该线程被阻塞,直到有一些数据被读取,或数据完全写入。该线程在此期间不能再干任何事情了。 Java NIO的非阻塞模式,使一个线程从某通道发送请求读取数据,但是它仅能得到目前可用的数据,如果目前没有数据可用时,就什么都不会获取。而不是保持线程阻塞,所以直至数据变的可以读取之前,该线程可以继续做其他的事情。 非阻塞写也是如此。一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。 线程通常将非阻塞IO的空闲时间用于在其它通道上执行IO操作,所以一个单独的线程现在可以管理多个输入和输出通道(channel)。
4)选择器(Selector)
Java NIO的选择器允许一个单独的线程来监视多个输入通道,你可以注册多个通道使用一个选择器,然后使用一个单独的线程来“选择"通道:这些通里已经有可以处理的褕入,或者选择已准备写入的通道。这选怿机制,使得一个单独的线程很容易来管理多个通道。
5)NIO和BIO读取文件
BIO读取文件:链接
BIO从一个阻塞的流中一行一行的读取数据
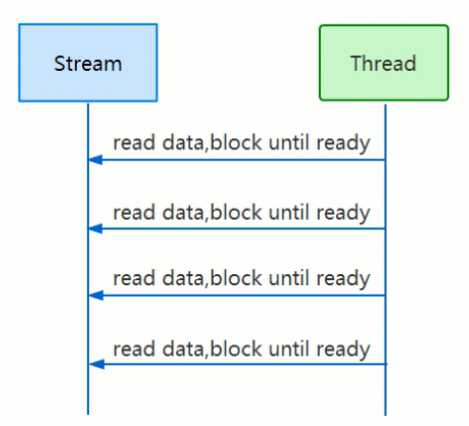
NIO读取文件:链接
通道是数据的载体,buffer是存储数据的地方,线程每次从buffer检查数据通知给通道
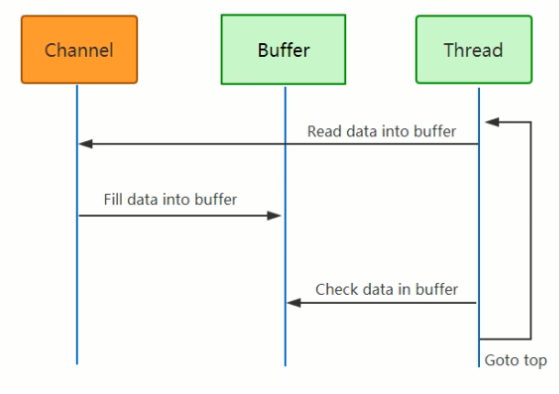
6)处理数据的线程数
NIO:一个线程管理多个连接
BIO:一个线程管理一个连接
3.NIO简介
在Java1.4之前的I/O系统中,提供的都是面向流的I/O系统,系统一次一个字节地处理数据,一个输入流产生一个字节的数据,一个输出流消费一个字节的数据,面向流的I/O速度非常慢,而在Java 1.4中推出了NIO,这是一个面向块的I/O系统,系统以块的方式处理处理,每一个操作在一步中产生或者消费一个数据库,按块处理要比按字节处理数据快的多。
在NIO中有几个核心对象需要掌握:缓冲区(Buffer)、通道(Channel)、选择器(Selector)。
参考:链接
4.缓冲区Buffer
缓冲区实际上是一个容器对象,更直接的说,其实就是一个数组,在NIO库中,所有数据都是用缓冲区处理的。在读取数据时,它是直接读到缓冲区中的; 在写入数据时,它也是写入到缓冲区中的;任何时候访问 NIO 中的数据,都是将它放到缓冲区中。而在面向流I/O系统中,所有数据都是直接写入或者直接将数据读取到Stream对象中。
在NIO中,所有的缓冲区类型都继承于抽象类Buffer,最常用的就是ByteBuffer,对于Java中的基本类型,基本都有一个具体Buffer类型与之相对应,它们之间的继承关系如下图所示:
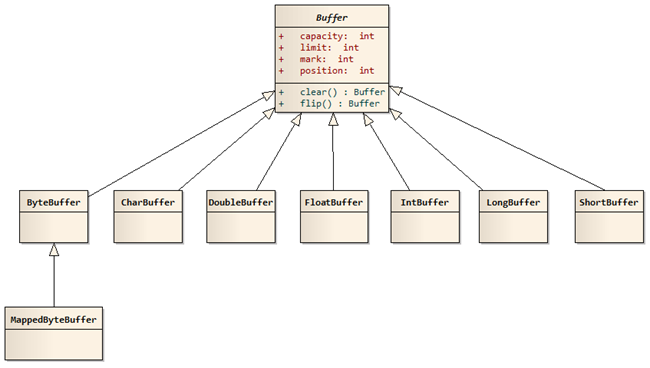
1)其中的四个属性的含义分别如下:
容量(Capacity):缓冲区能够容纳的数据元素的最大数量。这一个容量在缓冲区创建时被设定,并且永远不能改变。
上界(Limit):缓冲区的第一个不能被读或写的元素。或者说,缓冲区中现存元素的计数。
位置(Position):下一个要被读或写的元素的索引。位置会自动由相应的 get( )和 put( )函数更新。
标记(Mark):下一个要被读或写的元素的索引。位置会自动由相应的 get( )和 put( )函数更新。
2)Buffer的常见方法如下所示:
flip(): 写模式转换成读模式
rewind():将 position 重置为 0 ,一般用于重复读。
clear() :
compact(): 将未读取的数据拷贝到 buffer 的头部位。
mark(): reset():mark 可以标记一个位置, reset 可以重置到该位置。
Buffer 常见类型: ByteBuffer 、 MappedByteBuffer 、 CharBuffer 、 DoubleBuffer 、 FloatBuffer 、 IntBuffer 、 LongBuffer 、 ShortBuffer 。
3)基本操作
Buffer基础操作: 链接
缓冲区分片,缓冲区分配,直接缓存区,缓存区映射,缓存区只读:链接
4)缓冲区存取数据流程
存数据时position会++,当停止数据读取的时候
调用flip(),此时limit=position,position=0
读取数据时position++,一直读取到limit
clear() 清空 buffer ,准备再次被写入 (position 变成 0 , limit 变成 capacity) 。
5.通道Channel
通道是一个对象,通过它可以读取和写入数据,当然了所有数据都通过Buffer对象来处理。我们永远不会将字节直接写入通道中,相反是将数据写入包含一个或者多个字节的缓冲区。同样不会直接从通道中读取字节,而是将数据从通道读入缓冲区,再从缓冲区获取这个字节。

在NIO中,提供了多种通道对象,而所有的通道对象都实现了Channel接口。它们之间的继承关系如下图所示:
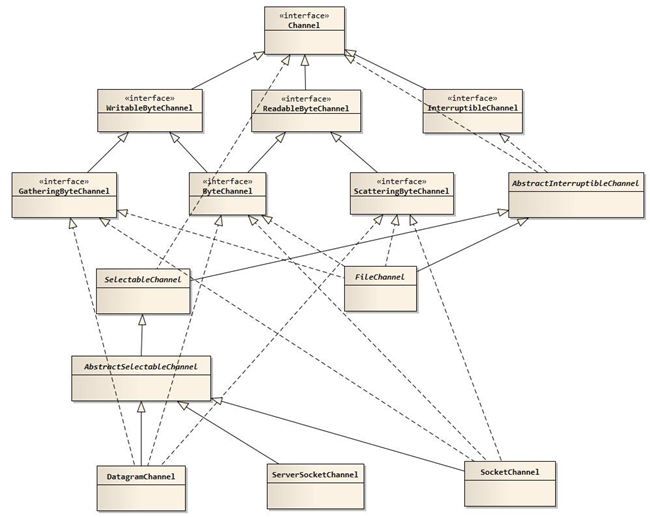
1)使用NIO读取数据
在前面我们说过,任何时候读取数据,都不是直接从通道读取,而是从通道读取到缓冲区。所以使用NIO读取数据可以分为下面三个步骤:
从FileInputStream获取Channel
创建Buffer
将数据从Channel读取到Buffer中
例子:链接
2)使用NIO写入数据
使用NIO写入数据与读取数据的过程类似,同样数据不是直接写入通道,而是写入缓冲区,可以分为下面三个步骤:
从FileInputStream获取Channel
创建Buffer
将数据从Channel写入到Buffer中
例子:链接
6.反应堆
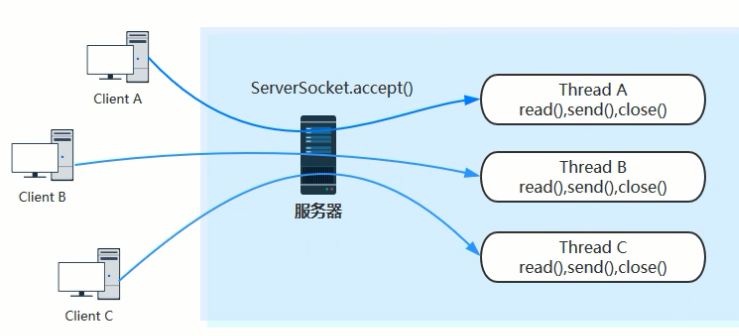
1)阻塞IO模型
在老的IO包中,serverSocket和socket都是阻塞式的,因此一旦有大规模的并发行为,而每一个访问都会开启一个新线程。这时会有大规模的线程上下文切换操作(因为都在等待,所以资源全都被已有的线程吃掉了),这时无论是等待的线程还是正在处理的线程,响应率都会下降,并且会影响新的线程。
2)NIO
Java NIO是在jdk1.4开始使用的,它既可以说成“新IO”,也可以说成非阻塞式I/O。下面是java NIO的工作原理:
1.由一个专门的线程来处理所有的IO事件,并负责分发。
2.事件驱动机制:事件到的时候触发,而不是同步的去监视事件。
3.线程通讯:线程之间通过wait,notify等方式通讯。保证每次上下文切换都是有意义的。减少无谓的线程切换。
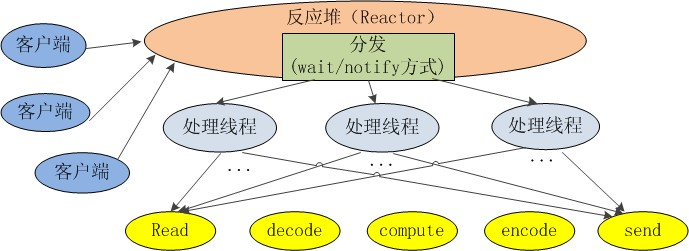
注:每个线程的处理流程大概都是读取数据,解码,计算处理,编码,发送响应。
7.选择器
传统的 server / client 模式会基于 TPR ( Thread per Request ) .服务器会为每个客户端请求建立一个线程.由该线程单独负贵处理一个客户请求。这种模式带未的一个问题就是线程数是的剧增.大量的线程会增大服务器的开销,大多数的实现为了避免这个问题,都采用了线程池模型,并设置线程池线程的最大数量,这又带来了新的问题,如果线程池中有 200 个线程,而有 200 个用户都在进行大文件下载,会导致第 201 个用户的请求无法及时处理,即便第 201 个用户只想请求一个几 KB 大小的页面。传统的 Sorvor / Client 模式如下围所示:
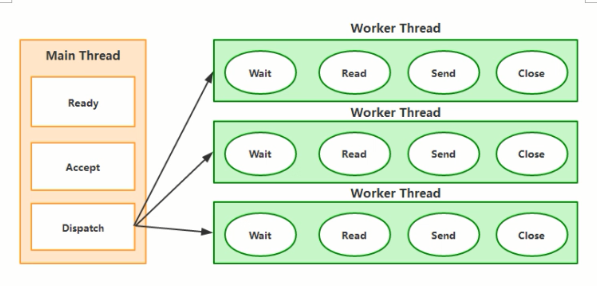
NIO 中非阻塞IO采用了基于Reactor模式的工作方式,IO调用不会被阻塞,相反是注册感兴趣的特点IO事件,如可读数据到达,新的套接字等等,在发生持定率件时,系统再通知我们。 NlO中实现非阻塞IO的核心设计Selector,Selector就是注册各种IO事件的地方,而且当那些事件发生时,就是这个对象告诉我们所发生的事件。
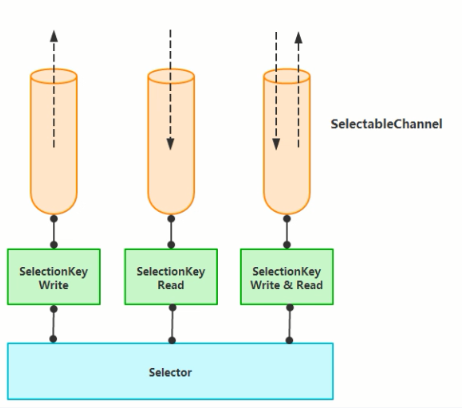
当有读或者写等任何注册的事件发生时,可以从Selector中获得相应的SelectionKey,同时从SelectionKey中可以找到发生的事件和该事件所发生的具体的SelectableChannel,以获得客户端发送过来的数据。
使用NIO中非阻塞IO编写服务器处理程序,有三个步骤
1.向Selector对象注册感兴趣的事件
2.从Selector中获取感兴趣的事件
3.根据不同事件进行相应的处理
8.NIO源码分析
Selector是NIO的核心
epool模型
1)Selector
Selector的open()方法:链接
2)ServerSocketChannel
ServerSocketChannel.open() 链接
9.AIO
Asynchronous IO
异步非阻塞IO
BIO ServerSocket
NIO ServerSocketChannel
AIO AsynchronousServerSocketChannel
AIO通信例子:链接
————————————————
版权声明:本文为CSDN博主「左耳听风」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/charjay_lin/article/details/81810922
NIO原理详解的更多相关文章
- Java网络编程和NIO详解6:Linux epoll实现原理详解
Java网络编程和NIO详解6:Linux epoll实现原理详解 本系列文章首发于我的个人博客:https://h2pl.github.io/ 欢迎阅览我的CSDN专栏:Java网络编程和NIO h ...
- I2C 基础原理详解
今天来学习下I2C通信~ I2C(Inter-Intergrated Circuit)指的是 IC(Intergrated Circuit)之间的(Inter) 通信方式.如上图所以有很多的周边设备都 ...
- Zigbee组网原理详解
Zigbee组网原理详解 来源:互联网 作者:佚名2015年08月13日 15:57 [导读] 组建一个完整的zigbee网状网络包括两个步骤:网络初始化.节点加入网络.其中节点加入网络又包括两个 ...
- 块级格式化上下文(block formatting context)、浮动和绝对定位的工作原理详解
CSS的可视化格式模型中具有一个非常重要地位的概念——定位方案.定位方案用以控制元素的布局,在CSS2.1中,有三种定位方案——普通流.浮动和绝对定位: 普通流:元素按照先后位置自上而下布局,inli ...
- SSL/TLS 原理详解
本文大部分整理自网络,相关文章请见文后参考. SSL/TLS作为一种互联网安全加密技术,原理较为复杂,枯燥而无味,我也是试图理解之后重新整理,尽量做到层次清晰.正文开始. 1. SSL/TLS概览 1 ...
- 锁之“轻量级锁”原理详解(Lightweight Locking)
大家知道,Java的多线程安全是基于Lock机制实现的,而Lock的性能往往不如人意. 原因是,monitorenter与monitorexit这两个控制多线程同步的bytecode原语,是JVM依赖 ...
- [转]js中几种实用的跨域方法原理详解
转自:js中几种实用的跨域方法原理详解 - 无双 - 博客园 // // 这里说的js跨域是指通过js在不同的域之间进行数据传输或通信,比如用ajax向一个不同的域请求数据,或者通过js获取页面中不同 ...
- 节点地址的函数list_entry()原理详解
本节中,我们继续讲解,在linux2.4内核下,如果通过一些列函数从路径名找到目标节点. 3.3.1)接下来查看chached_lookup()的代码(namei.c) [path_walk()> ...
- WebActivator的实现原理详解
WebActivator的实现原理详解 文章内容 上篇文章,我们分析如何动态注册HttpModule的实现,本篇我们来分析一下通过上篇代码原理实现的WebActivator类库,WebActivato ...
随机推荐
- 简单的python爬虫教程:批量爬取图片
python编程语言,可以说是新型语言,也是这两年来发展比较快的一种语言,而且不管是少儿还是成年人都可以学习这个新型编程语言,今天南京小码王python培训机构变为大家分享了一个python爬虫教程. ...
- python 之 Django框架(ORM常用字段和字段参数、关系字段和和字段参数)
12.324 Django ORM常用字段 .id = models.AutoField(primary_key=True):int自增列,必须填入参数 primary_key=True.当model ...
- Nmap脚本使用
Nmap是主机扫描工具,他的图形化界面是Zenmap,分布式框架为Dnamp. Nmap可以完成以下任务: 主机探测 端口扫描 版本检测 系统检测 支持探测脚本的编写 Nmap在实际中应用场合如下: ...
- Scratch编程:打猎(十)
“ 上节课的内容全部掌握了吗?反复练习了没有,编程最好的学习方法就是练习.练习.再练习.一定要记得多动手.多动脑筋哦~~” 01 — 游戏介绍 这节我们实现一个消灭猎物的射击游戏. 02 — 设计思路 ...
- Vue学习笔记(20190722)
- Spring Cloud--实现Eureka的高可用(Eureka集群搭建)实例
将10086注册到10087上: 再在10086服务的基础上复制一个Eureka的服务,端口为10087,将其注册到10086上: application-name的名称保持一致,只是一个服务的两个实 ...
- GRE
第一个技术是GRE,全称Generic Routing Encapsulation,它是一种IP-over-IP的隧道技术.它将IP包封装在GRE包里,外面加上IP头,在隧道的一端封装数据包,并在通路 ...
- oracle数据库 TIMESTAMP(6)时间戳类型
时间戳类型,参数6指的是表示秒的数字的小数点右边可以存储6位数字,最多9位.由于时间戳的精确度很高,我们也常常用来作为版本控制. 插入时,如下方式:insert into test4 values(t ...
- Linux实现MYSQl数据库的定时备份
今天给大家分享一下如何在Linux下实现MYSQl数据库的定时备份. 前提需要保证你的Linux服务器已经安装了MYSQl数据库服务. 1.创建shell脚本 vim backupdb.sh 创建脚本 ...
- SQL注入绕过技巧
1.绕过空格(注释符/* */,%a0): 两个空格代替一个空格,用Tab代替空格,%a0=空格: % % %0a %0b %0c %0d %a0 %00 /**/ /*!*/ 最基本的绕过方法,用注 ...