C基础 stack 设计
前言 - stack 设计思路
先说说设计 stack 结构的原由. 以前我们再释放查找树的时候多数用递归的后续遍历去释放.
其内部隐含了运行时的函数栈, 有些语言中存在爆栈风险. 所以想运用显示栈来替代隐式函数栈.
这就是我们设计 stack 的背景. 而我们这里的 stack 设计思路也比较直白, 运用可变数组进行尾
部压入和尾部弹出操作. 具体可见下图. 从左到右式弹出过程,
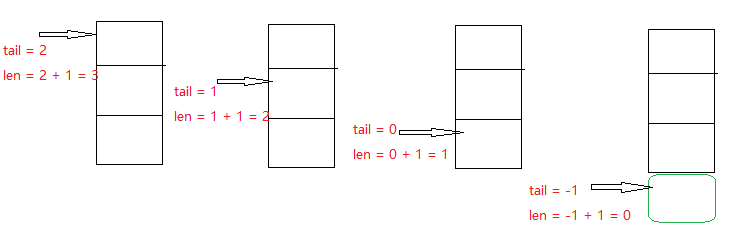
从右到左就是压入过程.
正文 - stack 详细设计
话不多说, 先看实现 code
stack.h - https://github.com/wangzhione/structc/blob/master/structc/struct/stack.h
#ifndef _STACK_H
#define _STACK_H #include "struct.h" #define INT_STACK (1 << 8) //
// struct stack 对象栈
// stack empty <=> tail = -1
// stack full <=> tail == cap
//
struct stack {
int tail; // 尾结点
int cap; // 栈容量
void ** data; // 栈实体
}; //
// stack_init - 初始化 stack 对象栈
// stack_free - 清除掉 stack 对象栈
// return : void
//
inline void stack_init(struct stack * s) {
assert(s && INT_STACK > );
s->tail = -;
s->cap = INT_STACK;
s->data = malloc(sizeof(void *) * INT_STACK);
} inline void stack_free(struct stack * s) {
free(s->data);
} //
// stack_delete - 删除 stack 对象栈
// s : stack 对象栈
// fdie : node_f push 结点删除行为
// return : void
//
inline void stack_delete(struct stack * s, node_f fdie) {
if (s) {
if (fdie) {
while (s->tail >= )
fdie(s->data[s->tail--]);
}
stack_free(s);
}
} //
// stack_empty - 判断 stack 对象栈是否 empty
// s : stack 对象栈
// return : true 表示 empty
//
inline bool stack_empty(struct stack * s) {
return s->tail < ;
} //
// stack_top - 获取 stack 栈顶对象
// s : stack 对象栈
// return : 栈顶对象
//
inline void * stack_top(struct stack * s) {
return s->tail >= ? s->data[s->tail] : NULL;
} //
// stack_pop - 弹出栈顶元素
// s : stack 对象栈
// return : void
//
inline stack_pop(struct stack * s) {
if (s->tail >= ) --s->tail;
} //
// stack_push - 压入元素到对象栈栈顶
// s : stack 对象栈
// m : 待压入的对象
// return : void
//
inline void stack_push(struct stack * s, void * m) {
if (s->cap <= s->tail) {
s->cap <<= ;
s->data = realloc(s->data, sizeof(void *) * s->cap);
}
s->data[++s->tail] = m;
} #endif//_STACK_H
INT_STACK 是拍脑门搞得 8 x 8, 唯一的损耗点可能在 stack_top 和 stack_empty 配合的时候, 需要
冗余判断一步 tail >= 0. 不过随着条件的分支预测, 实际影响不大, 也还好. 我们不妨写个业务测试.
#include <stack.h>
void stack_test(void) {
struct stack s; stack_init(&s);
char * str = NULL;
stack_push(&s, ++str);
stack_push(&s, ++str);
stack_push(&s, ++str);
// 数据输出
for (char * now; (now = stack_top(&s)); stack_pop(&s))
printf("now = %p\n", now);
stack_push(&s, ++str);
stack_push(&s, ++str);
for (char * now; (now = stack_top(&s)); stack_pop(&s))
printf("now = %p\n", now);
stack_free(&s);
}
那最终看 stack 实际运用场景吧, 运用显示栈来销毁查找树
// rtree_die - 后序删除树结点
static void rtree_die(struct $rtree * root, node_f fdie) {
struct $rtree * pre = NULL;
struct stack s; stack_init(&s);
stack_push(&s, root);
do {
struct $rtree * cur = stack_top(&s);
if ((!cur->left && !cur->right)
|| ((cur->left == pre || cur->right == pre) && pre)) {
fdie(pre = cur);
stack_pop(&s);
} else {
if (cur->right)
stack_push(&s, cur->right);
if (cur->left)
stack_push(&s, cur->left);
}
} while (!stack_empty(&s));
stack_free(&s);
}
更多细节代码可以阅读 rtree.h 对于二叉树后续非递归遍历, 压入右子树, 左子树,对比上次弹出的结点 ...
后记 - stack 未来展望
Friend- https://music.163.com/#/song?id=523560
错误是难免的, 欢迎交流提升 ~
基于当前 stack 设计, 未来展望具体从两方面处理. 复杂方面, 可以优化一下内存相关操作, 初始化,
扩容, 缩容等. 简单方面, 大家也看出来了, 这个栈代码极其少, 纯追求性能都可以直接放弃封装, 内嵌到
需要使用的地方和大业务混为一体. 那今天就到这里了, 2019/08/25 21:50 Dota2 OG 王朝真强
C基础 stack 设计的更多相关文章
- (2.15)Mysql之SQL基础——开发设计最佳规范
(2.15)Mysql之SQL基础——开发设计最佳规范 关键字:mysql三大范式,mysql sql开发规范 分析: show profile.mysqllsla.mysqldrmpslow.exp ...
- 小D课堂 - 新版本微服务springcloud+Docker教程_2_04微服务下电商项目基础模块设计
笔记 4.微服务下电商项目基础模块设计 简介:微服务下电商项目基础模块设计 分离几个模块,课程围绕这个基础项目进行学习 小而精的方式学习微服务 1.用户服务 ...
- SpringCloud Alibaba实战(3:存储设计与基础架构设计)
1.存储设计 在上一章中,我们已经完成了基本业务流程的梳理和服务模块的划分,接下来,开始设计数据存储. 虽然在微服务的理论中,没有对数据库定强制性的规范,但一般,服务拆分之后,数据库也会对应的拆分. ...
- Swift基础之设计折线坐标图
最近添加了折线视图的样式,所以在这里用Swift语言重新再使用设计一下 首先设置纵坐标的数值是:体重 //体重 let weightLabel = UILabel.init(frame: ...
- 网页基础:网页设计(我所知道的所有的html和css代码(含H5和CSS3)),如有错误请批评指正
最基础的网页设计,就是给你一个图片你做成一个网页,当然,我的工作是C#,个人网页的功底不是很高首先先认识一下网页的一些相关知识: 一般的,现在一个html网页一般包含html文件,css文件,js文件 ...
- 赢友网络通用框架V10.0.0(WinuAppSoft) 基础框架设计表
/* * 版权所有:赢友网络(http://www.winu.net/) * 开发人员:新生帝(JsonLei) * 设计名称:赢友网络通用框架V10.0.0(WinuAppSoft) * 设计时间: ...
- WCF基础之设计和实现服务协定
本来前面还有一个章节“WCF概述”,这章都是些文字概述,就不“复制”了,直接从第二章开始. 当然学习WCF还是要些基础的.https://msdn.microsoft.com/zh-cn/hh1482 ...
- C++标准库分析总结(五)——<Deque、Queue、Stack设计原则>
本节主要总结标准库Deque的设计方法和特性以及相关迭代器内部特征 1.Deque基本结构 Deque(双向队列)也号称连续空间(其实是给使用者一个善意的谎言,只是为了好用),其实它使用分段拼接起来的 ...
- 一、基础篇--1.1Java基础-MVC设计思想
MVC简介: MVC(Model View Controller) 是模型(model)-视图(view)-控制器(controller)的缩写.一种软件设计典范,用一种业务逻辑.数据.界面显示分离的 ...
随机推荐
- [PHP]Laravel无法使用COOKIE和SESSION的解决方法
COOKIE和SESSION的具体使用百度和官方文档上都有. 但是,文档里没有说明必须经过相应的中间件才能使用,百度搜索结果都是彼此copy的bullshit!!! 其实最终解决办法很简单,完全不是网 ...
- 【数论】[涨姿势:同余]P2312解方程
题目描述 已知多项式方程:\(a_0 + a_1x + a_2x^2+...+a_nx^n = 0\) 求这个方程在[1,m]内的整数解 \(1\leq n\leq100,|a_i|\leq 10^{ ...
- 【JZOJ5551】【20190625】旅途
题目 \(n\)个点\(m\)条边的无向图,一条路径的代价定义为路径上前\(k\)大边的边权和 对于$k = n \to 1 $,求1-n的最短路 \(n,m \le 3000 \ , \ w_i \ ...
- 一起学Makefile(三)
makefile工具箱 complicated项目的构建 文件结构如下: 文件内容如下: 项目依赖关系: gcc编译出可执行文件的过程包含了两个过程,编译和链接. makefile如下: 运行结果:
- Pytest权威教程19-编写钩子(Hooks)方法函数
目录 编写钩子(Hooks)函数 钩子函数验证和执行 firstresult: 遇到第一个有效(非None)结果返回 hookwrapper:在其他钩子函数周围执行 钩子(Hooks)函数排序/调用示 ...
- 使用adb连接Mumu模拟器
1)下载Mumu模拟器 2)运行Mumu模拟器 3)找到mumu安装目录下的MuMu\emulator\nemu\vmonitor\bin目录 4)在当前目录打开cmd,执行 adb connect ...
- 如何新建WebAPI,生成注释,TestAPI的项目
一.新建WebAPI的项目 1. 在Web下,ASP.NET Web 应用程序,点击确定 2. 点击确定 3. 如图所示, 新建Controller 4 . 运行项目 二.注释 1. 在生成中,勾选x ...
- 刷题记录:[HarekazeCTF2019]encode_and_encode
目录 刷题记录:[HarekazeCTF2019]encode_and_encode 一.知识点 JSON转义字符绕过 php伪协议 刷题记录:[HarekazeCTF2019]encode_and_ ...
- Seq2Seq模型 与 Attention 策略
Seq2Seq模型 传统的机器翻译的方法往往是基于单词与短语的统计,以及复杂的语法结构来完成的.基于序列的方式,可以看成两步,分别是 Encoder 与 Decoder,Encoder 阶段就是将输入 ...
- git修改提交作者和邮箱
作用一名程序员,我们会经常混迹与不同的代码仓库,时常不同仓库会有作者信息验证.比如公司内建的gitlab一般会要求统一使用公司内部的域账号签名:github要求使用github账号签名等.因此,很容易 ...