Python数据分析学习(二)
转摘:https://segmentfault.com/a/1190000015613967
本篇将继续上一篇数据分析之后进行数据挖掘建模预测,这两部分构成了一个简单的完整项目。结合两篇文章通过数据分析和挖掘的方法可以达到二手房屋价格预测的效果。
下面从特征工程开始讲述。
二、特征工程
特征工程包括的内容很多,有特征清洗,预处理,监控等,而预处理根据单一特征或多特征又分很多种方法,如归一化,降维,特征选择,特征筛选等等。这么多的方法,为的是什么呢?其目的是让这些特征更友好的作为模型的输入,处理数据的好坏会严重的影响模型性能,而好的特征工程有的时候甚至比建模调参更重要。
下面是继上一次分析之后对数据进行的特征工程,博主将一个一个帮大家解读。
"""
特征工程
"""
# 移除结构类型异常值和房屋大小异常值
df = df[(df['Layout']!='叠拼别墅')&(df['Size']<1000)] # 去掉错误数据“南北”,因为爬虫过程中一些信息位置为空,导致“Direction”的特征出现在这里,需要清除或替换
df['Renovation'] = df.loc[(df['Renovation'] != '南北'), 'Renovation'] # 由于存在个别类型错误,如简装和精装,特征值错位,故需要移除
df['Elevator'] = df.loc[(df['Elevator'] == '有电梯')|(df['Elevator'] == '无电梯'), 'Elevator'] # 填补Elevator缺失值
df.loc[(df['Floor']>6)&(df['Elevator'].isnull()), 'Elevator'] = '有电梯'
df.loc[(df['Floor']<=6)&(df['Elevator'].isnull()), 'Elevator'] = '无电梯' # 只考虑“室”和“厅”,将其它少数“房间”和“卫”移除
df = df.loc[df['Layout'].str.extract('^\d(.*?)\d.*?') == '室'] # 提取“室”和“厅”创建新特征
df['Layout_room_num'] = df['Layout'].str.extract('(^\d).*', expand=False).astype('int64')
df['Layout_hall_num'] = df['Layout'].str.extract('^\d.*?(\d).*', expand=False).astype('int64') # 按中位数对“Year”特征进行分箱
df['Year'] = pd.qcut(df['Year'],8).astype('object') # 对“Direction”特征
d_list_one = ['东','西','南','北']
d_list_two = ['东西','东南','东北','西南','西北','南北']
d_list_three = ['东西南','东西北','东南北','西南北']
d_list_four = ['东西南北']
df['Direction'] = df['Direction'].apply(direct_func)
df = df.loc[(df['Direction']!='no')&(df['Direction']!='nan')] # 根据已有特征创建新特征
df['Layout_total_num'] = df['Layout_room_num'] + df['Layout_hall_num']
df['Size_room_ratio'] = df['Size']/df['Layout_total_num'] # 删除无用特征
df = df.drop(['Layout','PerPrice','Garden'],axis=1) # 对于object特征进行onehot编码
df,df_cat = one_hot_encoder(df)
特征工程-数据处理
由于一些清洗处理在上一篇文章已经提到,所以从17行代码开始。
Layout 先看看没经处理的Layout特征值是什么样的:
df['Layout'].value_counts()
显示房型分类统计信息
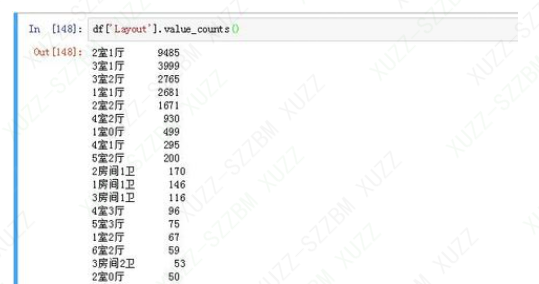
大家也都看到了,特征值并不是像想象中的那么理想。有两种格式的数据,一种是"xx室xx厅",另一种是"xx房间xx卫",但是绝大多数都是xx室xx厅的数据。而对于像"11房间3卫"或者"5房间0卫"这些的Layout明显不是民住的二手房(不在我们的考虑范围之内),因此最后决定将所有"xx房间xx卫"格式的数据都移除掉,只保留"xx室xx厅"的数据。
Layout特征的处理如下:
第2行的意思是只保留"xx室xx厅"数据,但是保留这种格式的数据也是不能作为模型的输入的,我们不如干脆将"室"和"厅"都提取出来,单独作为两个新特征(如第5和6行),这样效果可能更好。
具体的用法就是使用 str.extract() 方法,里面写的是正则表达式。
# 只考虑“室”和“厅”,将其它少数“房间”和“卫”移除
df = df.loc[df['Layout'].str.extract('^\d(.*?)\d.*?') == '室'] # 提取“室”和“厅”创建新特征
df['Layout_room_num'] = df['Layout'].str.extract('(^\d).*', expand=False).astype('int64')
df['Layout_hall_num'] = df['Layout'].str.extract('^\d.*?(\d).*', expand=False).astype('int64')
提取所需要的数据
Year分析:为建房的年限时间。年限种类很多,分布在1950和2018之间,如果每个不同的 Year 值都作为特征值,我们并不能找出 Year 对 Price 有什么影响,因为年限划分的太细了。因此,我们只有将连续数值型特征 Year 离散化,做分箱处理。
如何分箱还要看实际业务需求,博主为了方便并没有手动分箱,而使用了pandas的 qcut 采用中位数进行分割,分割数为8等份。
# 按中位数对“Year”特征进行分箱
df['Year'] = pd.qcut(df['Year'],8).astype('object')
按year进行分箱
将 Year 进行分箱的结果:

Direction分析:这个特征没处理之前更乱,原以为是爬虫的问题,但是亲自到链家看过,朝向确实是这样的

如上所见,像"西南西北北"或者"东东南南"这样的朝向是不符合常识的(反正我是理解不了)。因此,我们需要将这些凌乱的数据进行处理,具体实现方式是博主自己写了一个函数 direct_func,主要思想就是将各种重复但顺序不一样的特征值合并,比如"西南北"和"南西北",并将不合理的一些值移除,如"西南西北北"等。
然后通过 apply() 方法将 Direction 数据格式转换,代码如下:
# 对“Direction”特征
d_list_one = ['东','西','南','北']
d_list_two = ['东西','东南','东北','西南','西北','南北']
d_list_three = ['东西南','东西北','东南北','西南北']
d_list_four = ['东西南北']
df['Direction'] = df['Direction'].apply(direct_func)
df = df.loc[(df['Direction']!='no')&(df['Direction']!='nan')]
数据转换
处理完结果如下,所有的内容相同而顺序不同的朝向都合并了,异常朝向也被移除了。

创建新特征:
有时候仅靠已有的一些特征是不够的,需要根据对业务的理解,定义一些的新特征,然后尝试这些新特征对模型的影响,在实战中会经常使用这种方法。
这里尝试将"室"与"厅"的数量相加作为一个总数量特征,然后将房屋大小Size与总数量的比值作为一个新特征,可理解为 "每个房间的平均面积大小"。当然,新特征不是固定的,可根据自己的理解来灵活的定义。
# 根据已有特征创建新特征
df['Layout_total_num'] = df['Layout_room_num'] + df['Layout_hall_num']
df['Size_room_ratio'] = df['Size']/df['Layout_total_num'] # 删除无用特征
df = df.drop(['Layout','PerPrice','Garden'],axis=1)
创建新特征
最后删除旧的特征 Layout,PerPrice,Garden
One-hot coding:
这部分是 One-hot 独热编码,因为像 Region,Year(离散分箱后),Direction,Renovation,Elevator等特征都是定类的非数值型类型,而作为模型的输入我们需要将这些非数值量化。
在没有一定顺序(定序类型)的情况下,使用独热编码处理定类数据是非常常用的做法,在pandas中非常简单,就是使用 get_dummies() 方法,而对于像Size这样的定比数据则不使用独热,博主这里用了一个自己封装的函数实现了定类数据的自动量化处理。
对于定类,定序,定距,定比这四个非常重要的数据类型相信加入知识星球的伙伴都非常熟悉了,想要了解的同学可以扫描最后二维码查看。
# 对于object特征进行onehot编码
df,df_cat = one_hot_encoder(df)
one hot 编码
以上的特征工程就完成了。
特征相关性
下面使用 seaborn 的 heatmap 方法对特征相关性进行可视化。
# data_corr
colormap = plt.cm.RdBu
plt.figure(figsize=(20,20))
# plt.title('Pearson Correlation of Features', y=1.05, size=15)
sns.heatmap(df.corr(),linewidths=0.1,vmax=1.0, square=True, cmap=colormap, linecolor='white', annot=True)
可视化
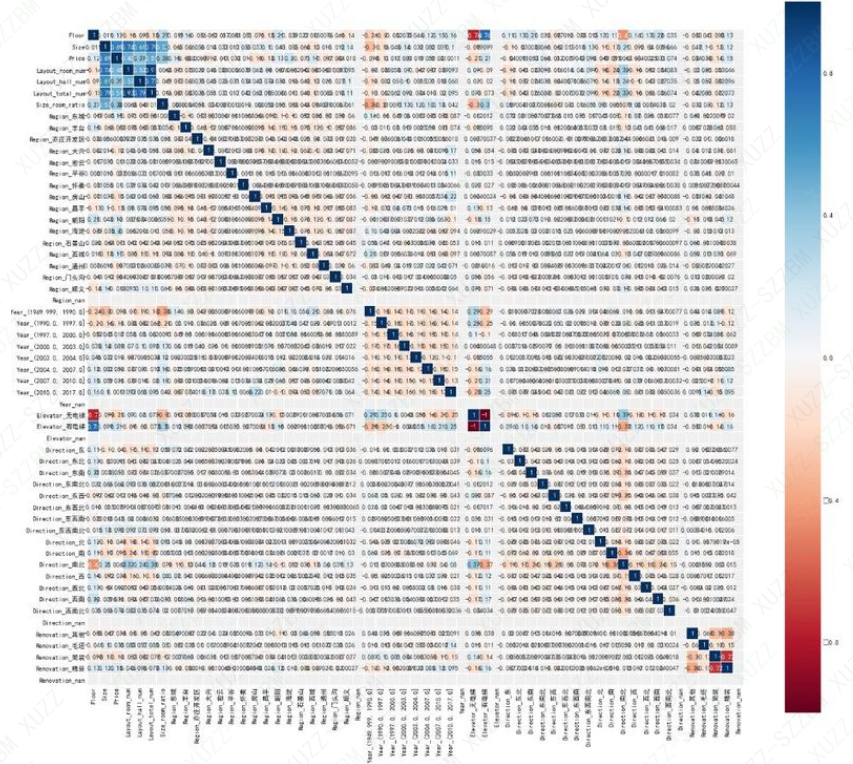
颜色偏红或者偏蓝都说明相关系数较大,即两个特征对于目标变量的影响程度相似,即存在严重的重复信息,会造成过拟合现象。因此,通过特征相关性分析,我们可以找出哪些特征有严重的重叠信息,然后择优选择。
三、数据建模预测
为了方便理解,博主在建模上做了一些精简,模型策略方法如下:
- 使用
Cart决策树的回归模型对二手房房价进行分析预测 - 使用
交叉验证方法充分利用数据集进行训练,避免数据划分不均匀的影响。 - 使用
GridSearchCV方法优化模型参数 - 使用
R2评分方法对模型预测评分
上面的建模方法比较简单,旨在让大家了解建模分析的过程。随着逐渐的深入了解,博主会介绍更多实战内容。
数据划分
# 转换训练测试集格式为数组
features = np.array(features)
prices = np.array(prices) # 导入sklearn进行训练测试集划分
from sklearn.model_selection import train_test_split
features_train, features_test, prices_train, prices_test = train_test_split(features, prices, test_size=0.2, random_state=0)
训练测试集
将以上数据划分为训练集和测试集,训练集用于建立模型,测试集用于测试模型预测准确率。使用sklearn的 model_selection 实现以上划分功能。
建立模型
from sklearn.model_selection import KFold
from sklearn.tree import DecisionTreeRegressor
from sklearn.metrics import make_scorer
from sklearn.model_selection import GridSearchCV # 利用GridSearchCV计算最优解
def fit_model(X, y):
""" 基于输入数据 [X,y],利于网格搜索找到最优的决策树模型""" cross_validator = KFold(10, shuffle=True)
regressor = DecisionTreeRegressor() params = {'max_depth':[1,2,3,4,5,6,7,8,9,10]}
scoring_fnc = make_scorer(performance_metric)
grid = GridSearchCV(estimator = regressor, param_grid = params, scoring = scoring_fnc, cv = cross_validator) # 基于输入数据 [X,y],进行网格搜索
grid = grid.fit(X, y)
# print pd.DataFrame(grid.cv_results_)
return grid.best_estimator_ # 计算R2分数
def performance_metric(y_true, y_predict):
"""计算并返回预测值相比于预测值的分数"""
from sklearn.metrics import r2_score
score = r2_score(y_true, y_predict) return score
mode
使用了 KFold 方法减缓过拟合,GridSearchCV 方法进行最优参数自动搜查,最后使用R2评分来给模型打分。
调参优化模型
import visuals as vs # 分析模型
vs.ModelLearning(features_train, prices_train)
vs.ModelComplexity(features_train, prices_train) optimal_reg1 = fit_model(features_train, prices_train) # 输出最优模型的 'max_depth' 参数
print("最理想模型的参数 'max_depth' 是 {} 。".format(optimal_reg1.get_params()['max_depth'])) predicted_value = optimal_reg1.predict(features_test)
r2 = performance_metric(prices_test, predicted_value) print("最优模型在测试数据上 R^2 分数 {:,.2f}。".format(r2))
参数调优
由于决策树容易过拟合的问题,我们这里采取观察学习曲线的方法查看决策树深度,并判断模型是否出现了过拟合现象。以下是观察到的学习曲线图形:

通过观察,最理想模型的参数"max_depth"是10,此种情况下达到了偏差与方差的最优平衡,最后模型在测试数据上的R2分数,也即二手房房价预测的准确率为:0.81。
Python数据分析学习(二)的更多相关文章
- Python数据分析学习目录
python数据分析学习目录 Anaconda的安装和更新 矩阵NumPy pandas数据表 matplotlib-2D绘图库学习目录
- python数据分析学习(2)pandas二维工具DataFrame讲解
目录 二:pandas数据结构介绍 下面继续讲解pandas的第二个工具DataFrame. 二:pandas数据结构介绍 2.DataFarme DataFarme表示的是矩阵的数据表,包含 ...
- Python数据分析学习(二):Numpy数组对象基础
1.1数组对象基础 .caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { bord ...
- Python数据分析学习(一)
转摘:https://segmentfault.com/a/1190000015440560 一.数据初探 首先导入要使用的科学计算包numpy,pandas,可视化matplotlib,seabor ...
- python数据分析学习(1)pandas一维工具Series讲解
目录 一:pandas数据结构介绍 python是数据分析的主要工具,它包含的数据结构和数据处理工具的设计让python在数据分析领域变得十分快捷.它以NumPy为基础,并对于需要类似 for循环 ...
- Python数据分析学习-re正则表达式模块
正则表达式 为高级的文本模式匹配.抽取.与/或文本形式的搜索和替换功能提供了基础.简单地说,正则表达式(简称为 regex)是一些由字符和特殊符号组成的字符串,它们描述了模式的重复或者表述多个字符,于 ...
- Python数据分析学习(一):Numpy与纯Python计算向量加法速度比较
import sys from datetime import datetime import numpy as np def numpysum(n): a = np.arange(n) ** 2 b ...
- Python数据分析学习之Numpy
Numpy的简单操作 import numpy #导入numpy包 file = numpy.genfromtxt("文件路径",delimiter=" ",d ...
- Python 数据分析(二 本实验将学习利用 Python 数据聚合与分组运算,时间序列,金融与经济数据应用等相关知识
Python 数据分析(二) 本实验将学习利用 Python 数据聚合与分组运算,时间序列,金融与经济数据应用等相关知识 第1节 groupby 技术 第2节 数据聚合 第3节 分组级运算和转换 第4 ...
随机推荐
- jquery设置css,animate设置多个属性
$("p").css("color","red"); $("p").css({ "font-size" ...
- 上传文本到hdfs上的一些命令
在hadoop下创建文件夹 bin/hdfs dfs -mkdir -p /usr/hadoop/spark/ touch wc.input 写一些文本进去. 上传到hdfs上 bin/hdfs ...
- 排序算法的c++实现——归并排序
归并排序是典型分治思想的代表——首先把原问题分解为两个或多个子问题,然后求解子问题的解,最后使用子问题的解来构造出原问题的解. 对于归并排序,给定一个待排序的数组,首先把该数组划分为两个子数组,然后对 ...
- MongoDB Spark Connector 实战指南
Why Spark with MongoDB? 高性能,官方号称 100x faster,因为可以全内存运行,性能提升肯定是很明显的 简单易用,支持 Java.Python.Scala.SQL 等多种 ...
- 使用Js将页面打印或保存为Pdf
很久没有写前端的文章了,今天就来说说js一个比较方便的功能,打印当前页面或保存成pdf吧. js有一个原生的函数,print(),顾名思义就是打印.但是有时候我们需要打印页面某些部分,所以需要对页面进 ...
- Vue开发之项目创建
1.编辑器配置 习惯使用VScode进行开发时,可以安装EditorConfig for Visual Studio Code插件,然后在项目中新建.editorconfig文件,来配置编辑器的使用习 ...
- hive的常用函数工作总结
1.concat_ws 它是一个特殊形式的 CONCAT() concat_ws(分隔符,参数1,参数2.......) as 字段 2.split 返回值为一个数组 a.基本用法: 例1:split ...
- TCP/IP通信过程(以发送电子邮件为例)(转)
1.应用程序处理 (1)A用户启动邮件应用程序,填写收件人邮箱和发送内容,点击“发送”,开始TCP/IP通信: (2)应用程序对发送的内容进行编码处理,这一过程相当于OSI的表示层功能: (3)由A用 ...
- 关于maven导入工程pom文件报错问题及解决
pom文件头报错 1.导入maven文件,经常遇到表头出错问题.报错:Failure to transfer org.apache.maven.shared:maven-filtering:pom:1 ...
- org.springframework.security.access.AccessDeniedException: Access is denied
org.springframework.security.access.AccessDeniedException: Access is denied at org.springframework.s ...